基于服务器版centos7的Hadoop/spark搭建
前提说明:
1.Hadoop与spark是两个独立的框架,只安装spark也可独立运行,spark有自己的调度器(standalone模式);
2.在Hadoop的基础上安装spark就是为了使用yarn调度器与Hadoop的hdfs存储;
3.如果你只想安装spark,可不用看Hadoop的安装,并不影响spark的安装与使用。
4.并不需要单独安装scala,因为spark之中已经集成了Scala(如果想要对应的版本也可以自己安装)
我的安装环境:
centos7服务器版、jdk8、hadoop2.7.4、spark2.4.0(请自行下载到所有节点Linux虚拟机中)(我没有使用克隆虚拟机的方式)
虚拟机数量:3(master、slave、slave)
实体机:win10
一.前期环境的配置
1.IP配置
1.1虚拟机网络设置
三台虚拟机均要设置成桥接模式,不然无法使用外部浏览器访问虚拟机,虽然能ping通并且ssh能够连接上
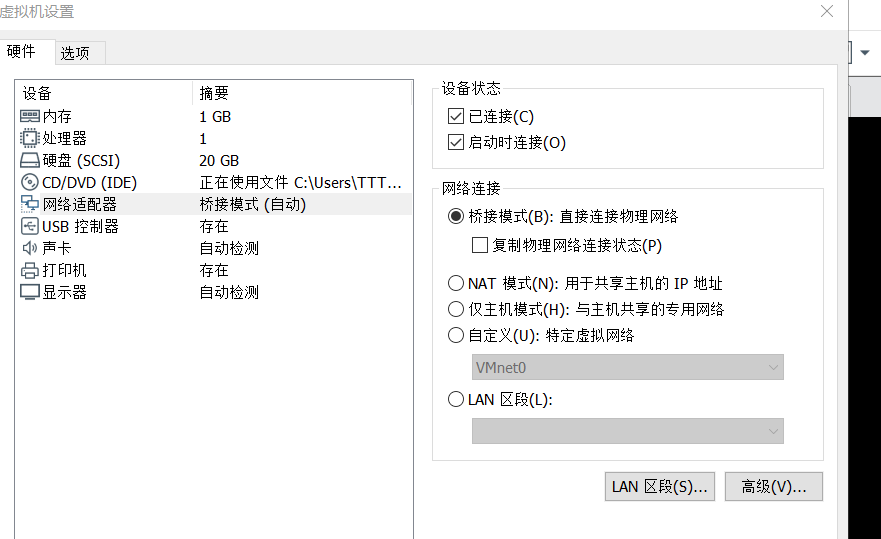
1.2静态IP配置
注:1.实体机在连接网线与wlan模式下IP不同,请在一种网络连接下配置(我的是在连接网线状态下)
2.如果不配置静态IP,在桥接模式下IP会自动获取,在后期无法使用
(1)首先在实体机中的cmd中查看并己住本机ip、网关、子掩网码:
(2)使用命令:ipconfig
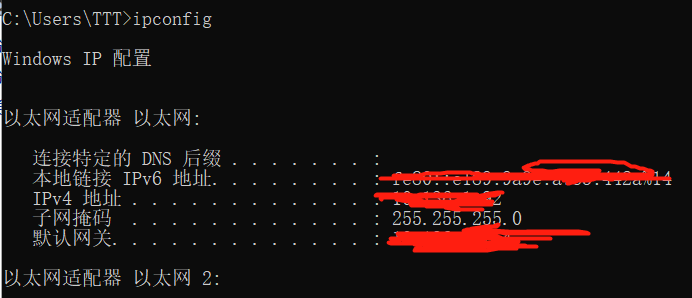
(3)根据以上信息填写如下文件:
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33(有的是ifcfg-eno16777736文件)
改成如下:

2.1接下来按照如下链接进行
https://www.linuxidc.com/Linux/2018-06/152795.htm
注:在链接中的2.3中:
scp -r /usr/local/hadoop-2.6.5 root@hadoop2:/usr/local/
scp -r /usr/local/hadoop-2.6.5 root@hadoop3:/usr/local/
链接作者是使用root用户进行安装配置的,没有问题,但是就像我使用非root进行root进行安装的,所以后期启动hadoop\spark会报权限错误,可使用如下方法进行更改目录所属用户权限:
chown -R user /usr/local/hadoop-2.7.4
同样,配置spark时也是一样
按照链接进行配置,亲测可行,虽然系统有所差异,但是不大,皆可百度、谷歌解决。
感谢链接作者,非常详尽!
基于服务器版centos7的Hadoop/spark搭建的更多相关文章
- 基本环境安装: Centos7+Java+Hadoop+Spark+HBase+ES+Azkaban
1. 安装VM14的方法在 人工智能标签中的<跨平台踩的大坑有提到> 2. CentOS分区设置: /boot:1024M,标准分区格式创建. swap:4096M,标准分区格式创建. ...
- centos7 hdfs yarn spark 搭建笔记
1.搭建3台虚拟机 2.建立账户及信任关系 3.安装java wget jdk-xxx rpm -i jdk-xxx 4.添加环境变量(全部) export JAVA_HOME=/usr/java/j ...
- 基于腾讯Centos7云服务器搭建SVN版本控制库
基于腾讯Centos7云服务器搭建SVN版本控制库 最近在和小伙伴组队参加一个关于人工智能的比赛,无奈不知道怎么处理好每个人的代码托管问题,于是找到了晚上免费svn托管服务器的服务,但是所给的免费空间 ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
随机推荐
- SQLALchemy之介绍,基本使用
一.介绍 SQLALchemy也是一个python的ORM框架,django内部的ORM框架只适用于django,而SQLALchemy适用于所有python的web框架 SQLAlchemy是一个基 ...
- linux下的C语言开发 进程创建 延伸的几个例子
在Linux下面,创建进程是一件十分有意思的事情.我们都知道,进程是操作系统下面享有资源的基本单位.那么,在linux下面应该怎么创建进程呢?其实非常简单,一个fork函数就可以搞定了.但是,我们需要 ...
- is not mapped [from错误
我出现的错误是:org.hibernate.hql.ast.QuerySyntaxException: loginuser is not mapped [from loginuser] 配置文件如下: ...
- 昆石VOS3000_2.1.2.0完整安装包及安装脚本
安装包下载地址 http://www.51voip.org/post/57.html 安装教程: 上传安装包 ·给整个目录授权 chmod 777 /root/vosintsall 1.安装前准备 首 ...
- E20171102-E
segment n. 环节; 部分,段落; [计算机] (字符等的) 分段; [动物学] 节片; distinct adj. 明显的,清楚的; 卓越的,不寻常的; 有区别的; 确切的;
- P3207 [HNOI2010]物品调度
传送门 完了题目看错了--还以为所有的\(x,y\)都要一样--结果题解都没看懂-- 先考虑如果已经求出了所有的\(pos\)要怎么办,那么我们可以把\(0\)也看做是一个箱子,然后最后每个箱子都在一 ...
- [Qt Creator 快速入门] 第8章 界面外观
一个完善的应用程序不仅应该有实用的功能,还要有一个漂亮的外观,这样才能使应用程序更加友好,更加吸引用户.作为一个跨平台的UI开发框架,Qt提供了强大而灵活的界面外观设计机制.这一章将学习在Qt中设计应 ...
- 洛谷 P2090 数字对
发现如果给定两个数(a,b),可以用类似辗转相除法在logn的时间内计算出(反向)变到(1,1)的最小步数. 然而并不知道另一个数是多少? 暴力嘛,枚举一下另一个数,反正1000000的nlogn不虚 ...
- 解决:org.springframework.tuple.spel.TuplePropertyAccessor
原来运行调试正常的项目,今天启动时报“java.lang.IllegalStateException: ApplicationEventMulticaster not initialized”错误.从 ...
- anime.js 实战:实现一个带有描边动画效果的复选框
在网页或者是APP的开发中,动画运用得当可以起到锦上添花的作用.正确使用动画,不但可以有助于用户理解交互的作用,还可以大大提高网页应用的魅力和使用体验.并且在现在的网页开发中,动画已经成为了一个设计的 ...