Mysql ICP(翻译)
英文版原文链接
https://mariadb.com/kb/en/library/index-condition-pushdown/
ICP 全称 Index Condition Pushdown。这个特性主要是针对索引查找的优化,使得查找数据的时候,无法精确匹配的索引也会做出比较。会在存储引擎层将不满足的数据直接过滤掉。
Index Condition Pushdown is an optimization that is applied for access methods that access table data through indexes: range, ref, eq_ref,
ref_or_null, and Batched Key Access. The idea is to check part of the WHERE condition that refers to index fields (we call it Pushed Index Condition) as soon as we've accessed the index.
If the Pushed Index Condition is not satisfied, we won't need to read the whole table record.
ICP 是一种通过索访问表数据的访问方法的优化,可以优化的类型有range,ref,eq_ref,ref_or_null。只要where后面的条件是索引,那么就可以适用于这个特性。如果ICP不满足(感觉这里应该是满足),则不用访问整个表的记录。
打开和关闭ICP
SET optimizer_switch='index_condition_pushdown=off'
ICP特性是默认打开的,可以通过sql语句关闭这个特性
当ICP特性被打开之后,Explain 字段会显示 “Using index condition”
When Index Condition Pushdown is used, EXPLAIN will show "Using index condition":
MariaDB [test]> explain select * from tbl where key_col1 between 10 and 11 and key_col2 like '%foo%';
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| 1 | SIMPLE | tbl | range | key_col1 | key_col1 | 5 | NULL | 2 | Using index condition |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
1 row in set (0.01 sec)
The idea behind index condition pushdown 关于ICP背后的秘密
In disk-based storage engines, making an index lookup is done in two steps, like shown on the picture:
在基于磁盘的存储引擎中,完成一个索引查询需要两个步骤
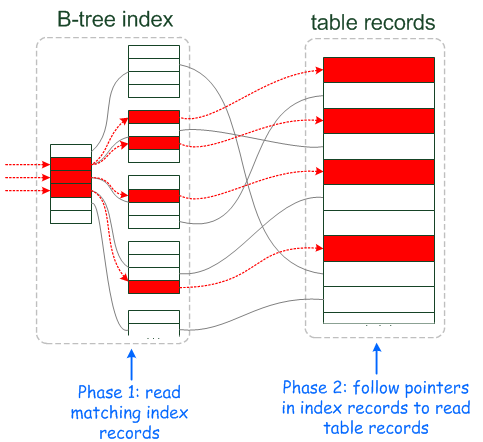
第一步是读入匹配的索引记录,第二步是根据索引中的指针读取表中的记录
Index Condition Pushdown optimization tries to cut down the number of full record reads by checking whether index records satisfy part of the WHERE condition that can be checked for them:
ICP特性 尝试检测where条件中的条件是否,来减少读取整个表的数据
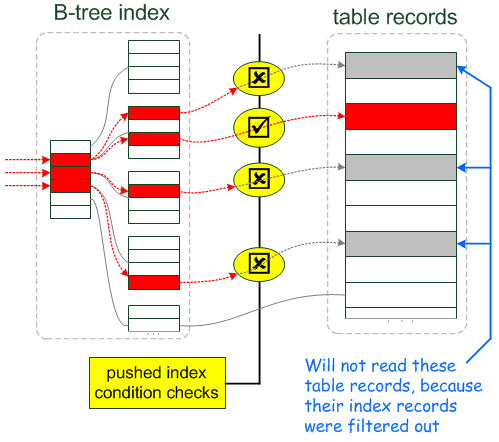
How much speed will be gained depends on - How many records will be filtered out - How expensive it was to read them The former depends on the query and the dataset. The latter is generally bigger when table records are on disk and/or are big, especially when they have blobs.
将获得多少速度取决于 - 多少记录将被过滤掉 - 取决于多去数据需要消耗的花费 前者取决于查询和数据集。 当表记录在磁盘上和/或是大的时候,后者通常更大,特别是当它们具有斑点时。
Mysql ICP(翻译)的更多相关文章
- MySQL ICP(Index Condition Pushdown)特性
一.SQL的where条件提取规则 在ICP(Index Condition Pushdown,索引条件下推)特性之前,必须先搞明白根据何登成大神总结出一套放置于所有SQL语句而皆准的where查询条 ...
- 《高性能Mysql》翻译错误
原文中在分区表中的一句话翻译错误,如下 应该是[扫描列a上的索引就需要扫描每一个分区内对应的索引树],英文版描述如下: ''' Suppose you define an index on a and ...
- MySQL 使用经验
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/10 在索引中完成排序 SELECT thread_id FROM ...
- MySQL 执行计划中Extra(Using where,Using index,Using index condition,Using index,Using where)的浅析
关于如何理解MySQL执行计划中Extra列的Using where.Using Index.Using index condition,Using index,Using where这四者的区别 ...
- MySQL数据丢失讨论
原文地址:http://hatemysql.com/tag/sync_binlog/ 1. 概述 很多企业选择MySQL都会担心它的数据丢失问题,从而选择Oracle,但是其实并不十分清楚什么情况下 ...
- MYSQL—— 启动MYSQL 57 报错“The service MYSQL57 failed the most recent........等”的问题解决方式!
每天开机之后,启动MYSQL Notifier就报错,第一次出现重启电脑后解决,后面的几天老是出现,重启电脑好几次都没有解决,感觉很烦人,一定要搞定这个问题找到原因,于是有了下文....... 启动M ...
- MySQL Execution Plan--IN子查询包含超多值引发的查询异常
问题描述 版本:MySQL 5.7.24 SQL语句: SELECT wave_no, SUM(IF(picking_qty IS NULL, 0, picking_qty)) AS PICKED_Q ...
- (转)MySQL数据丢失讨论
原文地址:http://hatemysql.com/tag/sync_binlog/ 1. 概述 很多企业选择MySQL都会担心它的数据丢失问题,从而选择Oracle,但是其实并不十分清楚什么情况下 ...
- Atitit s2018.2 s2 doc list on home ntpc.docx \Atiitt uke制度体系 法律 法规 规章 条例 国王诏书.docx \Atiitt 手写文字识别 讯飞科大 语音云.docx \Atitit 代码托管与虚拟主机.docx \Atitit 企业文化 每日心灵 鸡汤 值班 发布.docx \Atitit 几大研发体系对比 Stage-Gat
Atitit s2018.2 s2 doc list on home ntpc.docx \Atiitt uke制度体系 法律 法规 规章 条例 国王诏书.docx \Atiitt 手写文字识别 ...
随机推荐
- pycharm命令行快捷启动
打开 本用户目录下的.bashrc文件 vim .bashrc 在末尾添加一行 alias pycharm="the-path-to-pycharm.sh" 最后保存退出 然后更新 ...
- redis主从集群搭建
一.安装redis 首先登陆官网下载压缩包,我安装的是最新版本5.X,下载地址http://download.redis.io/releases/redis-5.0.2.tar.gz. 进入文件所在目 ...
- C#语言开发规范-ching版
拙劣之处请大家斧正,愚某虚心接受,如有雷同,不胜荣幸 C#语言开发规范 作者ching 1. 命名规范 a) 类 [规则1-1]使用Pascal规则命名类名,即首字母要大写. eg: Class T ...
- iOS 跷跷板动画 Seesaw Animation
Xcode Playgound示例代码: let testView = UIView() testView.frame = CGRect.init(x: , y: , width: , height: ...
- Selenium | 网上教程
java selenium (一) selenium 介绍 java selenium (二) 环境搭建方法一 java selenium (三) 环境搭建 基于Maven java selenium ...
- the little schemer 笔记(4)
第四章 numbers games 14 是原子吗 是的,数都是原子 (atom? n) 是真还是假,其中n是14 真,14 是原子 -3是数吗 是的,不过我们暂不考虑负数 3.14159是数吗 是的 ...
- Codeforces 1144F(二分染色)
发现奇环不可行,偶环可行,考虑二分图.然后染色,方向全都从一种指向另一种就可以了,随意. ; int n, m, color[maxn]; vector<int> vc[maxn]; ve ...
- 牛客国庆集训派对Day_1~3
Day_1 A.Tobaku Mokushiroku Kaiji 题目描述 Kaiji正在与另外一人玩石头剪刀布.双方各有一些代表石头.剪刀.布的卡牌,每局两人各出一张卡牌,根据卡牌的内容决定这一局的 ...
- COPY, RETAIN, ASSIGN , READONLY , READWRITE,STRONG,WEAK,NONATOMIC整理--转
copy:建立一个索引计数为1的对象,然后释放旧对象 对NSString 对NSString 它指出,在赋值时使用传入值的一份拷贝.拷贝工作由copy方法执行,此属性只对那些实行了NSCopying协 ...
- NTP服务简介
定义:NTP全称为Network Time Protocol,即网络时间协议.是用来使计算机时间同步的一种协议.它可以使计算机对服务器或时钟源做同步,可以提供高精度的时间校正(LAN 上与标准时间小于 ...