Python网咯爬虫 — Scrapy框架应用
Scrapy框架
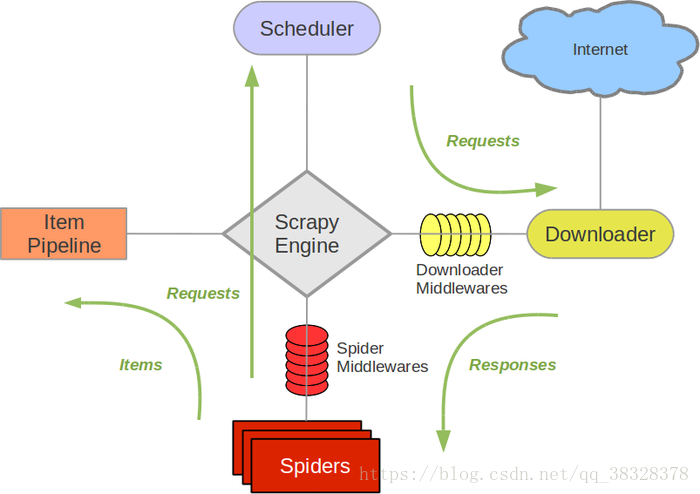
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程
Scrapy运行流程大概如下:
1)引擎从调度器中取出一个链接(URL)用于接下来的抓取;
2)引擎把URL封装成一个请求(Request)传给下载器;
3)下载器把资源下载下来,并封装成应答包(Response);
4)爬虫解析Response;
5)解析出实体(Item),则交给实体管道进行进一步的处理;
6)解析出的是链接(URL),则把URL交给调度器等待抓取。
Scrapy的安装
首先在cmd命令行中安装Scrapy
pip install scrapy在Windows安装是可能会出现错误,提示找不到Microsoft Visual C++,需要安装Twisted 。
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
Twisted的安装:
pip install E:\Downloads\Twisted-18.4.0-cp36-cp36m-win_amd64.whl最后再安装Scrapy。
Scrapy常用命令
| 命令 | 说明 | 格式 |
| startproject | 创建一个新工程 | Scrapy startproject 项目名 |
| genspider | 创建一个爬虫 | Scrapy genspider 项目名 域名 |
| settings | 获取爬虫配置信息 | Scrapy settings |
| crawl | 运行一个爬虫 | Scrapy crawl 项目名 |
| list | 列出工程所有爬虫 | Scrapy list |
| shell | 启动URL调试命令行 | Scrapy shell [url] |
| edit | 编辑爬虫文件 | Scrapy edit 文件名 |
注意:一般创建爬虫文件时,以网站域名命名
项目创建
项目创建步骤:
E:\PyCodes\scrapy startproject myprojectE:\PyCodes\myproject\scrapy genspider mydome mydome.com步骤3:配置产生的spider爬虫
# -*- coding:utf-8 -*-
import scrapy
class MydemoSpider(scrapy.Spider):
name = "mydemo"
allowd_domains = ["http://mydome.com"]
start_url = ['http://python123.io/ws/dome.html']
def parse(self, response):
passE:\PyCodes\myproject\scrapy crawl mydome生成的项目结构:
myproject/ -------外层目录
scrapy.cfg -------项目的配置文件
myproject/ -------该项目的python模块。之后您将在此加入代码。
__init__.py -------初始化脚本
items.py -------item代码模块(继承类)
middlewares.py -------Middlewares代码模板(继承类)
pipelines.py -------Pipelines代码模板(继承类)
settings.py -------Scrapy爬虫的配置文件
spiders/ -------Spiders代码模板目录(继承类)
__init__.py -------初始文件,无需修改
__init__.py -------缓存目录,无需修改Python网咯爬虫 — Scrapy框架应用的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 爬虫scrapy框架之CrawlSpider
爬虫scrapy框架之CrawlSpider 引入 提问:如果想要通过爬虫程序去爬取全站数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模 ...
- 安装爬虫 scrapy 框架前提条件
安装爬虫 scrapy 框架前提条件 (不然 会 报错) pip install pypiwin32
- 爬虫Ⅱ:scrapy框架
爬虫Ⅱ:scrapy框架 step5: Scrapy框架初识 Scrapy框架的使用 pySpider 什么是框架: 就是一个具有很强通用性且集成了很多功能的项目模板(可以被应用在各种需求中) scr ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明 scrapy 为一个框架 框架和第三方库的区别: 库可以直接拿来就用, 框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好 命令: 创建一个 项目 : cd 到需 ...
随机推荐
- SQL Server-索引管理
http://www.2cto.com/database/201305/207508.html SQL Server-索引管理 一.显示索引信息 在建立索引后,可以对表索引信息进行查询. (1)在 ...
- HDU3032 nim博弈
题目大意: 可以从某一堆中取任意个数,也可把一堆分成两个不为0的堆,直到某一方无法操作为输 因为是nim博弈,所以只要考虑一堆时候的sg值,把所有堆的sg值异或即可 很显然这里 0 是一个终止态 sg ...
- [NOIP2007] 提高组 洛谷P1099 树网的核
题目描述 设T=(V, E, W) 是一个无圈且连通的无向图(也称为无根树),每条边到有正整数的权,我们称T为树网(treebetwork),其中V,E分别表示结点与边的集合,W表示各边长度的集合,并 ...
- Linux下汇编语言学习笔记30 ---
这是17年暑假学习Linux汇编语言的笔记记录,参考书目为清华大学出版社 Jeff Duntemann著 梁晓辉译<汇编语言基于Linux环境>的书,喜欢看原版书的同学可以看<Ass ...
- Codeforces 621E Wet Shark and Block【dp + 矩阵快速幂】
题意: 有b个blocks,每个blocks都有n个相同的0~9的数字,如果从第一个block选1,从第二个block选2,那么就构成12,问对于给定的n,b有多少种构成方案使最后模x的余数为k. 分 ...
- [bzoj3238][Ahoi2013]差异_后缀数组_单调栈
差异 bzoj-3238 Ahoi-2013 题目大意:求任意两个后缀之间的$LCP$的和. 注释:$1\le length \le 5\cdot 10^5$. 想法: 两个后缀之间的$LCP$和显然 ...
- Sum-(最大子序列和)
http://bestcoder.hdu.edu.cn/contests/contest_showproblem.php?cid=652&pid=1003 题目大意: 给你一个序列,你随便找一 ...
- Remove Duplicates from Sorted List (链表)
Given a sorted linked list, delete all duplicates such that each element appear only once. For examp ...
- hibernate dynamic-update="true"属性不起作用原因(转载)
原文地址: https://yan-sa.iteye.com/blog/1913684 由于我在action层使用了注解多例@Scope("prototype"),而在dao层默认 ...
- 怎样删除Tomcat下已经部署的项目
lz说的是把web项目部署到tomcat之中,要把它删除..很简单,找到webapps文件(tomcat的根目录)下把它删除即可.. 2.Tomcat 6.0\webapps\项目名 只要在把这个目录 ...