xpath选择器
一、xpath中节点关系
父(Parent):每个元素以及属性都有一个父
子(Children):元素节点可有零个、一个或多个子
同胞(Sibling):拥有相同的父的节点
先辈(Ancestor):某节点的父、父的父
后代(Descendant):某个节点的子,子的子
二、xpath中选取节点的路径表达式
/ 绝对路径
// 相对路径
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
三、xpath中“谓语”
放在[]中的几种查找方式写法如下:
//ul/li[1] , 表示选择 ul多个li子元素中的第一个
//ul/li[last()], 表示选择ul子元素中的最后一个li元素
//ul/li[last()-1], 表示选择ul子元素中的倒数第二个li元素
//ul/li[position()<3],表示选取最前面2个属于ul元素的li子元素
//a[@href] ,表示选取只要含有href属性的a元素
//a[@href='http://www.cnblogs.com/jenniferhuang'] ,属性值完全匹配
//input[contains(@id,'quantityTextBox')], 当属性值部分匹配时,插入函数的写法
四、xpath函数
函数被分成四类
节点集函数: last(), position(),
字符串函数: contains(), substring(@class,'abc')="", substring-before(), substring-after(), string-length()
布尔函数:
数字函数:
reference : http://www.cnblogs.com/cxd4321/archive/2007/09/24/903869.html SearchKkeyword: "核心函数库"
五、xpath轴
|
轴名称 |
结果 |
|
ancestor |
选取当前节点的所有先辈(父、祖父等) |
|
ancestor-or-self |
选取当前节点的所有先辈(父、祖父等)以及当前节点本身 |
|
descendant |
选取当前节点的所有后代元素(子、孙等) |
|
descendant-or-self |
选取当前节点的所有后代元素(子、孙等)以及当前节点本身 |
|
parent |
选取当前节点的父节点 |
|
child |
选取当前节点的所有子元素 |
|
following |
选取文档中当前节点的结束标签之后的所有节点 |
|
preceding |
选取文档中当前节点的开始标签之前的所有节点 |
|
preceding-sibling |
选取当前节点之前的所有同级节点 |
|
attribute |
选取当前节点的所有属性 |
|
namespace |
选取当前节点的所有命名空间节点 |
|
self |
选取当前节点 |
六、应用举例
1、定位某个节点,该节点包含有一已知的特定后代节点
//table[contains(@class,'orderHistoryBox') and descendant::dd[text()='11132789']]
2、定位一已知节点的某一先辈节点
//dd[text()='11132789']//ancestor::table[contains(@class,'orderHistoryBox')](与1效果相同)
3、不包含的写法
//table[@id='wizards-ivrKeyPressAssignment-extSelectorForm-mailbox-field']/tbody/tr[not(contains(@class,'x-hidden'))][5]
4、注意class的取用:
//*[contains(@id,'userCallForwarding/rules-hoursSelector-tabBar-root-item') and contains(@class,'textTabButtonSelected')]
该class可以不是当前id''userCallForwarding/rules-hoursSelector-tabBar-root-item'' 下的class,可以是其包含标签内其他元素的class,例如下面对应的xpath结构
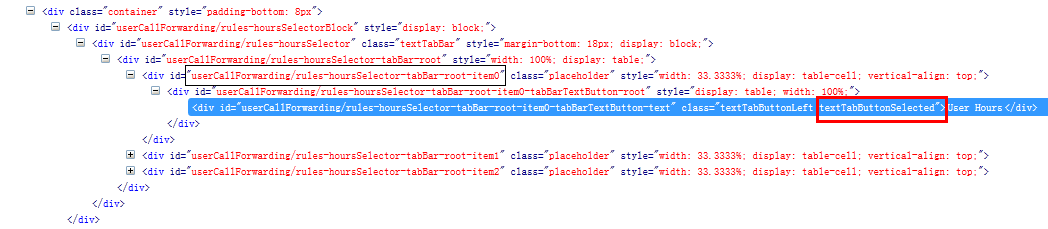
//*[contains(@id,'userCallForwarding/rules-hoursSelector-tabBar-root-item') and contains(@class,'textTabButtonSelected')]@id
可以取到Attribute"userCallForwarding/rules-hoursSelector-tabBar-root-item0-tabBarTextButton-text"
5、xpath拆分法可以增强稳定性
例如:
public TabBar(String id) {
super(id);
rootLocator = locator + PropertyReader.getProperty("Controls.TabBar.root");
itemLocator = rootLocator + PropertyReader.getProperty("Controls.TabBar.item");
}
6、xpath带有变量
例如:
extensionDescription.xpath=//tbody[@id='system-extensions-usersGrid-tbody']//div[@class='system-extensions-title' and text()='$VALUE']/../../following-sibling::*[1]
真正要取列表中哪个Description:
extensionDescription.getxPath().replace("$VALUE",groupName)
7、取属性值
id=entry-settings-phoneSystem-departments@class
或者 //*[@id='entry-settings-phoneSystem-departments']@class
http://www.51testing.com/?uid-79191-action-spacelist-type-blog-itemtypeid-25252
WebElement label = driver.findElement(By.xpath("//label[text()='User Name:' and not(contains(@style,'display:none'))]"))
More examples:
http://www.zvon.org/xxl/XPathTutorial/General_chi/examples.html
xpath选择器的更多相关文章
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 常用xpath选择器和css选择器总结
xpath选择器 表达式 说明 article 选取所有article元素的所有子节点 /article 选取根元素article article/a 选取所有属于article的子元素的a元素 // ...
- xpath选择器简介及如何使用
xpath选择器简介及如何使用 一.总结 一句话总结:XPath 的全称是 XML Path Language,即 XML 路径语言,它是一种在结构化文档(比如 XML 和 HTML 文档)中定位信息 ...
- 在Scrapy中如何利用Xpath选择器从HTML中提取目标信息(两种方式)
前一阵子我们介绍了如何启动Scrapy项目以及关于Scrapy爬虫的一些小技巧介绍,没来得及上车的小伙伴可以戳这些文章: 手把手教你如何新建scrapy爬虫框架的第一个项目(上) 手把手教你如何新建s ...
- Selenium(九):Xpath选择器
1. Xpath选择器 1.1 Xpath语法简介 前面我们学习了CSS选择元素. 大家可以发现非常灵活.强大. 还有一种灵活.强大的选择元素的方式,就是使用Xpath表达式. XPath (XML ...
- 用Xpath选择器解析网页(lxml)
在<爬虫基础以及一个简单的实例>一文中,我们使用了正则表达式来解析爬取的网页.但是正则表达式有些繁琐,使用起来不是那么方便.这次我们试一下用Xpath选择器来解析网页. 首先,什么是XPa ...
- xpath选择器使用
简单说,xpath就是选择XML文件中节点的方法. 所谓节点(node),就是XML文件的最小构成单位,一共分成7种. - element(元素节点)- attribute(属性节点)- text ( ...
- 初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)
一 安装 #Linux: pip3 install scrapy #Windows: a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu ...
- 使用 XPath 选择器
在前面的内容中,我们掌握了一些 CSS 选择器和它们的使用方法,以及 rvest 包中用于提取网页内容的函数.一般来说,CSS 选择器足够满足绝大部分的 HTML 节点匹配的需要.但是,当需要根据某些 ...
随机推荐
- Git branch (分支学习)
以前总结的一些git操作,分享在这里. Git 保存的不是文件差异或者变化量,而只是一系列文件快照. - 列出当前所有分支 git branch <--merge> | <--n ...
- 读《CSS禅意花园》 有感
1.图片用<img>标签添加到页面中,会增加页面的大小,导致页面加载需要更长的时间.可以用css background 引用图片. 1.1.若图像属于“内容”而不是“样式”的一部分,例如“ ...
- 【JS】Intermediate7:jQuery:DOM API
1.jQuery also makes performing actions on many elements at the same time simple 2.eg:$('.note').css( ...
- sunlime操作
ctrl+p 查找文件 @进行符号查找ctrl+h 替换文件 选中字符以后多次按 ctrl+D 跳过则按 ctrl+Kctrl+shift+d 复制多行alt+f3 多选 ctrl+shift+p ...
- Esper系列(六)子查询、Exists、In/not in、Any/Some、Join
子查询 1 >= all (select salary from orderEvent.win:length_batch(5))"; 注意: 运行以上三个例句后的结果,刚开始让很费 ...
- CF_216_Div_2
比赛链接:http://codeforces.com/contest/369 369C - Valera and Elections: 这是一个树上问题,用深搜,最开始贪心想得是只加叶子节点,找到一个 ...
- Recommended add-ons/plugins for Microsoft Visual Studio [closed]
SmartPaster - (FREE) Copy/Paste code generator for strings AnkhSvn - (FREE) SVN Source Control Integ ...
- centos git版本服务器配置
在服务器上安装git及做些操作 - 执行命令 ` sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-de ...
- 图的强连通&双连通
http://www.cnblogs.com/wenruo/p/4989425.html 强连通 强连通是指一个有向图中任意两点v1.v2间存在v1到v2的路径及v2到v1的路径. dfs遍历一个图, ...
- 原来DataTable的Distinct竟如此简单![转]
本文转自:http://www.cnblogs.com/BlueFly/archive/2009/01/08/1372151.html 有时我们需要从DataTable中抽取Distinct数据,以前 ...