python多进程的理解 multiprocessing Process join run
最近看了下多进程。
一种接近底层的实现方法是使用 os.fork()方法,fork出子进程。但是这样做事有局限性的。比如windows的os模块里面没有 fork() 方法。
windows: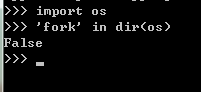 。linux:
。linux: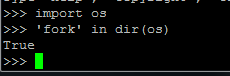
另外还有一个模块:subprocess。这个没整过,但从vamei的博客里看到说也同样有局限性。
所以直接说主角吧 --- multiprocessing模块。 multiprocessing模块会在windows上时模拟出fork的效果,可以实现跨平台,所以大多数都使用multiprocessing。
下面给一段简单的代码,演示一下创建进程:
#encoding:utf-8
from multiprocessing import Process
import os, time, random #线程启动后实际执行的代码块
def r1(process_name):
for i in range(5):
print process_name, os.getpid() #打印出当前进程的id
time.sleep(random.random())
def r2(process_name):
for i in range(5):
print process_name, os.getpid() #打印出当前进程的id
time.sleep(random.random()) if __name__ == "__main__":
print "main process run..."
p1 = Process(target=r1, args=('process_name1', )) #target:指定进程执行的函数,args:该函数的参数,需要使用tuple
p2 = Process(target=r2, args=('process_name2', )) p1.start() #通过调用start方法启动进程,跟线程差不多。
p2.start() #但run方法在哪呢?待会说。。。
p1.join() #join方法也很有意思,寻思了一下午,终于理解了。待会演示。
p2.join()
print "main process runned all lines..."
执行结果:
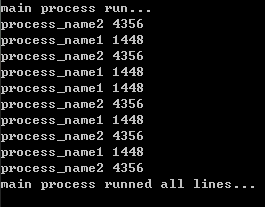
上面提到了两个方法:run 和join
run:如果在创建Process对象的时候不指定target,那么就会默认执行Process的run方法:
#encoding:utf-8
from multiprocessing import Process
import os, time, random def r():
print 'run method' if __name__ == "__main__":
print "main process run..."
#没有指定Process的targt
p1 = Process()
p2 = Process()
#如果在创建Process时不指定target,那么执行时没有任何效果。因为默认的run方法是判断如果不指定target,那就什么都不做
#所以这里手动改变了run方法
p1.run = r
p2.run = r p1.start()
p2.start()
p1.join()
p2.join()
print "main process runned all lines..."
另:python源码里,Process.run方法:
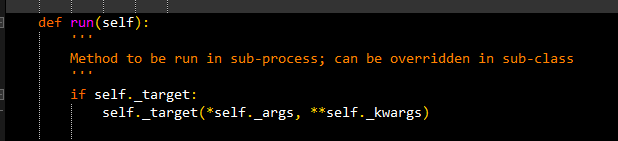
执行结果:
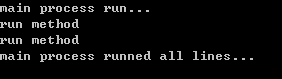
可见如果在实例化Process时不指定target,就会执行默认的run方法。
还有一个join方法:
最上面演示的代码中,在调用Process的start方法后,调用了两次join方法。这个join方法是干什么的呢?
官方文档的意思是:阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程。
比如还是刚才的代码,只是把两个join注释掉了:
#encoding:utf-8
from multiprocessing import Process
import os, time, random def r1(process_name):
for i in range(5):
print process_name, os.getpid() #打印出当前进程的id
time.sleep(random.random())
def r2(process_name):
for i in range(5):
print process_name, os.getpid() #打印出当前进程的id
time.sleep(random.random()) if __name__ == "__main__":
print "main process run..."
p1 = Process(target=r1, args=('process_name1', ))
p2 = Process(target=r2, args=('process_name2', )) p1.start()
p2.start()
#p1.join()
#p2.join()
print "main process runned all lines..."
执行结果:
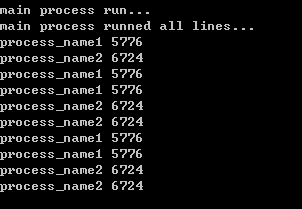
发现主进程不像之前那样,等待两个子进程执行完了,才继续执行。而是启动两个进程后立即向下执行。
为了深刻理解,这次把p2的执行函数里面睡眠时间调大,让他多睡一会,然后保留p1的join,注释掉p2的join,效果更明显:
#encoding:utf-8
from multiprocessing import Process
import os, time, random def r1(process_name):
for i in range(5):
print process_name, os.getpid() #打印出当前进程的id
time.sleep(random.random())
def r2(process_name):
for i in range(5):
print process_name, os.getpid() #打印出当前进程的id
time.sleep(random.random()*2) if __name__ == "__main__":
print "main process run..."
p1 = Process(target=r1, args=('process_name1', ))
p2 = Process(target=r2, args=('process_name2', )) p1.start()
p2.start()
p1.join()
#p2.join()
print "main process runned all lines..."
执行结果:
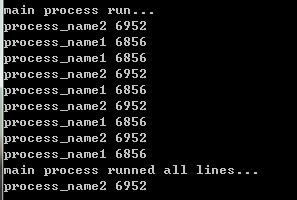
发现主线程只是等待p1完成了,就会向下执行,而不会等待p2是否完成。
所以使用多进程的常规方法是,先依次调用start启动进程,再依次调用join要求主进程等待子进程的结束。
然而为什么要先依次调用start再调用join,而不是start完了就调用join呢,如下:
由:
p1.start()
p2.start()
p1.join()
改为:
p1.start()
p1.join()
p2.start()
执行效果:
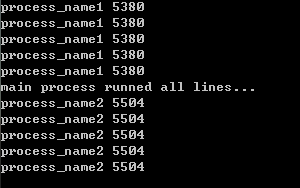
发现是先执行完p1,再执行主线程,最后才开始p2。
今天上午一直困惑这个事,现在终于明白了。join是用来阻塞当前线程的,p1.start()之后,p1就提示主线程,需要等待p1结束才向下执行,那主线程就乖乖的等着啦,自然没有执行p2.start()这一句啦,当然就变成了图示的效果了。
python多进程的理解 multiprocessing Process join run的更多相关文章
- 进程 multiprocessing Process join Lock Queue
多道技术 1.空间上的复用 多个程序公用一套计算机硬件 2.时间上的复用 cpu 切换程序+保存程序状态 1.当一个程序遇到IO操作,操作系统会剥夺该程序的cpu执行权限(提高了cpu的利用率,并且不 ...
- Python多进程multiprocessing使用示例
mutilprocess简介 像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多. import multipr ...
- Python多进程库multiprocessing创建进程以及进程池Pool类的使用
问题起因最近要将一个文本分割成好几个topic,每个topic设计一个regressor,各regressor是相互独立的,最后汇总所有topic的regressor得到总得预测结果.没错!类似bag ...
- 创建一个多进程(multiprocessing.Process)
进程是资源的集合,每个进程至少包含一个线程 import multiprocessing #导入进程模块import time, threading #导入线程 def thread_run(): p ...
- 【转】Python多进程编程
[转]Python多进程编程 序. multiprocessingpython中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程.Pytho ...
- Python 多进程编程之multiprocessing--Process
Python 多进程编程之multiprocessing 1,Process 跨平台的进程创建模块(multiprocessing), 支持跨平台:windowx/linux 创建和启动 创 ...
- python多进程详解和协程
1.由于python多线程适合于多IO操作,但不适合于cpu计算型工作,这时候可以通过多进程实现.python多进程简单实用 # 多进程,可以cpu保持一致,python多线程适合多io.对于高cpu ...
- python多进程总结
概述 由于python中全局解释器锁(GIL)的存在,所以python多线程并不能有效利用CPU多核的性能(相当于单核并发)实现多线程多核并行,所以在对CPU密集型的程序时处理效率较低,反而对IO密集 ...
- Python 多进程异常处理
前言 最近项目用到了Python作为网站的前端,使用的框架是基于线程池的Cherrypy,但是前端依然有一些比较‘重’的模块.由于python的多线程无法很好的利用多核的性质,所以觉得把这些比较‘重’ ...
随机推荐
- phaser源码解析(一) Phaser.Utils类下shuffle方法
/** * #一个 基于 费雪耶茨排列 洗牌方法 * A standard Fisher-Yates Array shuffle implementation. * @method Phaser.Ut ...
- skip跳跃表的实现
skiplist介绍 跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入.删除.查找的复杂度均为O(logN).跳表的具体定义, 跳表是由William Pugh发明的, ...
- Linux下通过ODBC连接sqlserver
Linux下通过ODBC连接sqlserver 1.需求: 最近有个需求就是要在linux下连接(可以执行sql语句)sqlserver 2.环境 操作系统: Centos6.5 数据库: ...
- jQuery EasyUI tree中state属性慎用
EasyUI 1.4.4 tree控件中,如果是叶子节点,切忌把state设置为closed,否则该节点会加载整个tree,形成死循环 例如: json入下: [ { "checked&qu ...
- 网站开发常用jQuery插件总结(11)折叠插件Akordeon
实现折叠菜单,可以完全不使用插件.如果使用jquery的话,实现起来也比较简单,我们只需要定义折叠菜单的样式,然后使用jquery中的渐隐渐现就可以了.如果我们自己写折叠菜单,可以方便的使用我们自己的 ...
- jquery 多级无限分类
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/ ...
- 青瓷qici - H5小游戏 抽奖机 3 效果设置
现在是万事俱备,只欠东风,好,我们一起动手,先来东风东. 烟花粒子效果 第一个来实现我们的烟花粒子效果,点击我们的粒子,按照下图方式配置. 注意此时我们已经加入了white.png作为粒子特效使用. ...
- 搭建mysql主从复制---Mysql Replication
主从复制原理 Mysql的Replication是一个异步的复制过程,从一个Mysql Instance(master)复制到另一个Mysql Instance(slave).中间需要三个线程slav ...
- html5 API
1.Canvas绘图 2.postMessage跨域.多窗口传输 3.requestAnimationFrame动画 4.PageVisibility API页面可见性 5.File 本地文件操作 6 ...
- hadoop2——新MapReduces——yarm详解
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个Nod ...