基于NodeJs的网页爬虫的构建(一)
好久没写博客了,这段时间已经忙成狗,半年时间就这么没了,必须得做一下总结否则白忙。接下去可能会有一系列的总结,都是关于定向爬虫(干了好几个月后才知道这个名词)的构建方法,实现平台是Node.JS。
背景
一般爬虫的逻辑是这样的,给定一个初始链接,把该链接的网页下载保存,接着分析页面中的链接,找到目标链接检查是否已经请求过,如果未请求则放入请求队列,页面下载完成后交给索引器建立索引,如此往复即可建立一套提供给搜索引擎使用的文档库。我当时的需求并不是这样,而是抓取某几个网站的数据并把规定的字段输出为结构化的文件最终会放到EXCEL中分析。后者也许只需要该网站全量的商品数据,其它一概不需要,这样见面不需要保存。
我将顺着时间顺序记录问题和想法。
问题
编码遇到的第一个问题,也是在哪里都会遇到的问题,要彻底解决编码问题,就需要弄清楚三个问题:
- 为什么乱码?
- 如何找到内容的正确编码?
- 如何转码?
为什么乱码,当然是因为当前的字符串使用的编码并不是“正确”的,所谓“正确”就是该字符串在进入内存时用的什么编码去存储。举个粟子,“你”字的utf8编码[1]时内存的值: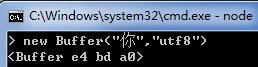
这时候使用ascii来解码就得不到正确的文本,因为ascii最大也就认识7E[2]。之所以NodeJS打印非utf8的字符串乱码,是因为它默认使用utf8,所以必须要找到来源的正确编码转换成utf8。
那么如何找到内容的正确编码?看HTTP协议!在HTTP header中有一个Content-Type的field[3],它可以指定协议所支持的media-type,包括图片、文本、音频等,我们只看文本,并且是文本中的html,一般后面会跟上字符集编码。举个例子:
Content-Type: text/html; charset=ISO-8859-4
可以看到指定了html格式的文本类型和字符集,那当我们接收到返回时,只需要读取返回头中的Content-Type块,这就可以解决绝大部分问题了。但还没有完,有的网站并没有在HTTP header里面告诉你是什么字符集,例如:
Content-Type: text/html baidu.com返回的就是这样的头,那浏览器如何知道怎么解析页面呢,因为浏览器打开并不会乱码,仔细看看返回的HTML文件就会发现文档里面会有meta标签来指定编[4]:
When the http-equiv attribute is specified on a meta element, the element is a pragma directive. You can use this element to simulate an HTTP response header, but only if the server doesn't send the corresponding real header; you can't override an HTTP header with ameta http-equivelement.
这样看来呢,协议头里面的优先级会高一点,所以正确的解析顺序是先从协议头中找编码方式,找不到再从文档里面寻找meta的http-equiv标签。(还有两篇文章关于UTF-8和Unicode详解写的很详细([5],[6]))。
找到了正确的编码以后,就可以找类库来做转码。比如从GBK编码转到UTF-8,只需要使用它们的编码对应关系做对应的替换。在NodeJS里面使用iconv和iconv-lite可以很好地完成这个工作,iconv是C++实现的本地库,安装会有些困难,iconv-lite是纯javascript实现的转码,安装相对简单,缺点是可能码不全也没有正式版。
多谢@落幕残情的提醒,再加一点补充。编码是可以通过检测来获取的,但是在WEB中并不是正确的做法,这种方法通常在不知道源的编码情况被迫使用的,而HTTP协议中和HTML文档规定了字符编码!检测概率模型存在误差,NodeJS有一个库叫做jschardet,该模块在node-webcrawler中被使用,实践告诉我出错概率非常大。再次感谢,欢迎其他想法。
[1]. http://zh.wikipedia.org/wiki/UTF-8
[2]. http://zh.wikipedia.org/wiki/ASCII
[3]. http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html
[4]. http://www.w3.org/wiki/HTML/Elements/meta
[5]. 关于文件编码格式的一点探讨
[6].Unicode详解
基于NodeJs的网页爬虫的构建(一)的更多相关文章
- 基于NodeJs的网页爬虫的构建(二)
好久没写博客了,这段时间已经忙成狗,半年时间就这么没了,必须得做一下总结否则白忙.接下去可能会有一系列的总结,都是关于定向爬虫(干了好几个月后才知道这个名词)的构建方法,实现平台是Node.JS. 背 ...
- 一次使用NodeJS实现网页爬虫记
前言 几个月之前,有同事找我要PHP CI框架写的OA系统.他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP. 我上QeePHP官网,发现官方网站打不开了,GOOGL ...
- 基于nodeJS的小说爬虫实战
背景与需求分析 最近迷恋于王者荣耀.斗鱼直播与B站吃播视频,中毒太深,下班之后无心看书. 为了摆脱现状,能习惯看书,我开始看小说了,然而小说网站广告多而烦,屌丝心态不愿充钱,于是想到了爬虫. 功能分析 ...
- nodeJS实现简单网页爬虫功能
前面的话 本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/h ...
- 浏览器自动刷新——基于Nodejs的Gulp LiveReload与VisualStudio完美结合。
本文版权桂博客园和作者吴双共同所有,转载和爬虫请注明原文地址 http://www.cnblogs.com/tdws/p/6016055.html 写在前面 大家好我是博客园的蜗牛,博客园的蜗牛就是我 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- [resource-]Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
reference: http://www.52nlp.cn/python-%e7%bd%91%e9%a1%b5%e7%88%ac%e8%99%ab-%e6%96%87%e6%9c%ac%e5%a4% ...
- 【ShoppingWebCrawler】-基于Webkit内核的爬虫蜘蛛引擎概述
写在开头 在各个电商平台发展日渐成熟的今天.很多时候,我们需要一些平台上的基础数据.比如:商品分类,分类下的商品详细,甚至业务订单数据.电商平台大多数提供了相应的业务接口.允许ISV接入,用来扩展自身 ...
- 【Python】Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
本文转载自:https://www.cnblogs.com/colipso/p/4284510.html 好文 mark http://www.52nlp.cn/python-%E7%BD%91%E9 ...
随机推荐
- cep
- centos6.4 yum kvm
1. 安装软件包: yum -y install virt-manager; yum install qemu-kvm yum install libvirt yum install libvi ...
- Yii框架CGridView columns中使用数组或变量传值
继续Yii框架的学习与使用,CGridView对于网站后台而言十分有用处,可以很快速地实现数据列表显示,并集成排序,搜索等功能,很巧妙. 今天,在项目中遇到了状态显示问题,在controller中定义 ...
- 问题-[VMware Workstation]断电后,重启电脑,之后就提示“内部错误”
问题现象:突然断电后,重启电脑,再打开VMware Workstation,启动不了.之后就提示“内部错误”.问题原因:希望高人指点.问题处理:关闭VMware Workstation,在快捷方式上, ...
- javascript的类和构造函数
在javascript中,类的实现是基于其原型继承机制的.如果两个实例都从同一个原型对象上继承了属性,我们就说它们是同一个类的实例.那么,如果两个对象继承自同一个原型,那基本上可以认为它们是由同一个构 ...
- [struts2]struts结合ECharts的用法
<script src="http://echarts.baidu.com/build/dist/echarts-all.js"></script> < ...
- Robot Framework自动化测试(三)--- 封装系统关键字
之前对robotframework-ride了解的不多,后来知道了引入Selenium2Lirary库后可以做web UI自动化测试,但发现和python没啥关系,今天学习了封装系统关键字算是和pyt ...
- Redis_基本类型介绍和指令___3
1.set(集合) Redis的Set是string类型的无序集合.集合成员是唯一的,这就意味着集合中不能出现重复的数据. Redis 中 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O( ...
- 机房收费系统(VB.NET)——存储过程实战
最初接触存储过程是在耿建玲老师的视频里,当初仅仅是草草过了一遍.仅仅是有了个印象.知道了这个名词:大二时也有SqlServer数据库这门课,只是老师没讲,自己也没看:真正对存储过程的了解来自于自学考试 ...
- 正尝试在 OS 载入程序锁内执行托管代码。不要尝试在 DllMain 或映像初始化函数内执行托管代码,这样做会导致应用程序挂起。
出错提示: 正尝试在 OS 载入程序锁内执行托管代码. 不要尝试在 DllMain 或映像初始化函数内执行托管代码,这样做会导致应用程序挂起. 原因分析: .NET2.0中添加了42种非常强大的调试助 ...