python大战机器学习——数据降维
注:因为公式敲起来太麻烦,因此本文中的公式没有呈现出来,想要知道具体的计算公式,请参考原书中内容
降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中
1、主成分分析(PCA)
将n维样本X通过投影矩阵W,转换为K维矩阵Z
输入:样本集D,低维空间d
输出:投影矩阵W
算法步骤:
1)对所有样本进行中心化操作
2)计算样本的协方差矩阵
3)对协方差矩阵做特征值分解
4)取最大的d个特征值对应的特征向量,构造投影矩阵W
注:通常低维空间维数d的选取有两种方法:1)通过交叉验证法选取较好的d 2)从算法原理的角度设置一个阈值,比如t=0.95,然后选取似的下式成立的最小的d值:
Σ(i->d)λi/Σ(i->n)λi>=t,其中λi从大到小排列
PCA降维的准则有以下两个:
最近重构性:重构后的点距离原来的点的误差之和最小
最大可分性:样本点在低维空间的投影尽可能分开
实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold def load_data():
iris=datasets.load_iris()
return iris.data,iris.target def test_PCA(*data):
X,Y=data
pca=decomposition.PCA(n_components=None)
pca.fit(X)
print("explained variance ratio:%s"%str(pca.explained_variance_ratio_)) def plot_PCA(*data):
X,Y=data
pca=decomposition.PCA(n_components=2)
pca.fit(X)
X_r=pca.transform(X)
# print(X_r) fig=plt.figure()
ax=fig.add_subplot(1,1,1)
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)
for label,color in zip(np.unique(Y),colors):
position=Y==label
# print(position)
ax.scatter(X_r[position,0],X_r[position,1],label="target=%d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[0]")
ax.legend(loc="best")
ax.set_title("PCA")
plt.show() X,Y=load_data()
test_PCA(X,Y)
plot_PCA(X,Y)
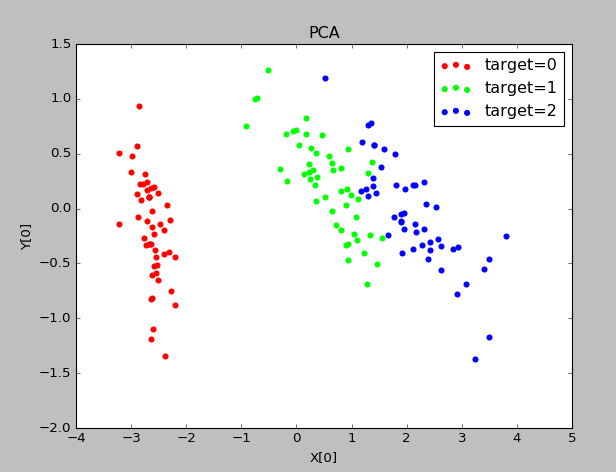
实验结果:
可以看出四个特征值的比例分别占比0.92464621,0.05301557,0.01718514,0.00518309,因此可将原始特征4维降低到2维

IncrementalPCA超大规模数据降维
可以使用与超大规模数据,它可以将数据分批加载进内存,其接口和用法几乎与PCA完全一致
2、SVD降维
SVD奇异值分解等价于PCA主成分分析,核心都是求解X*(X转置)的特征值以及对应的特征向量
3、核化线性(KPCA)降维
是一种非线性映射的方法,核主成分分析是对PCA的一种推广
实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold def load_data():
iris=datasets.load_iris()
return iris.data,iris.target def test_KPCA(*data):
X,Y=data
kernels=['linear','poly','rbf','sigmoid']
for kernel in kernels:
kpca=decomposition.KernelPCA(n_components=None,kernel=kernel)
kpca.fit(X)
print("kernel=%s-->lambdas:%s"%(kernel,kpca.lambdas_)) def plot_KPCA(*data):
X,Y=data
kernels = ['linear', 'poly', 'rbf', 'sigmoid']
fig=plt.figure()
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)
for i,kernel in enumerate(kernels):
kpca=decomposition.KernelPCA(n_components=2,kernel=kernel)
kpca.fit(X)
X_r=kpca.transform(X)
ax=fig.add_subplot(2,2,i+1)
for label,color in zip(np.unique(Y),colors):
position=Y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target=%d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title("kernel=%s"%kernel)
plt.suptitle("KPCA")
plt.show() X,Y=load_data()
test_KPCA(X,Y)
plot_KPCA(X,Y)
实验结果:
不同的核函数,其降维后的数据分布是不同的
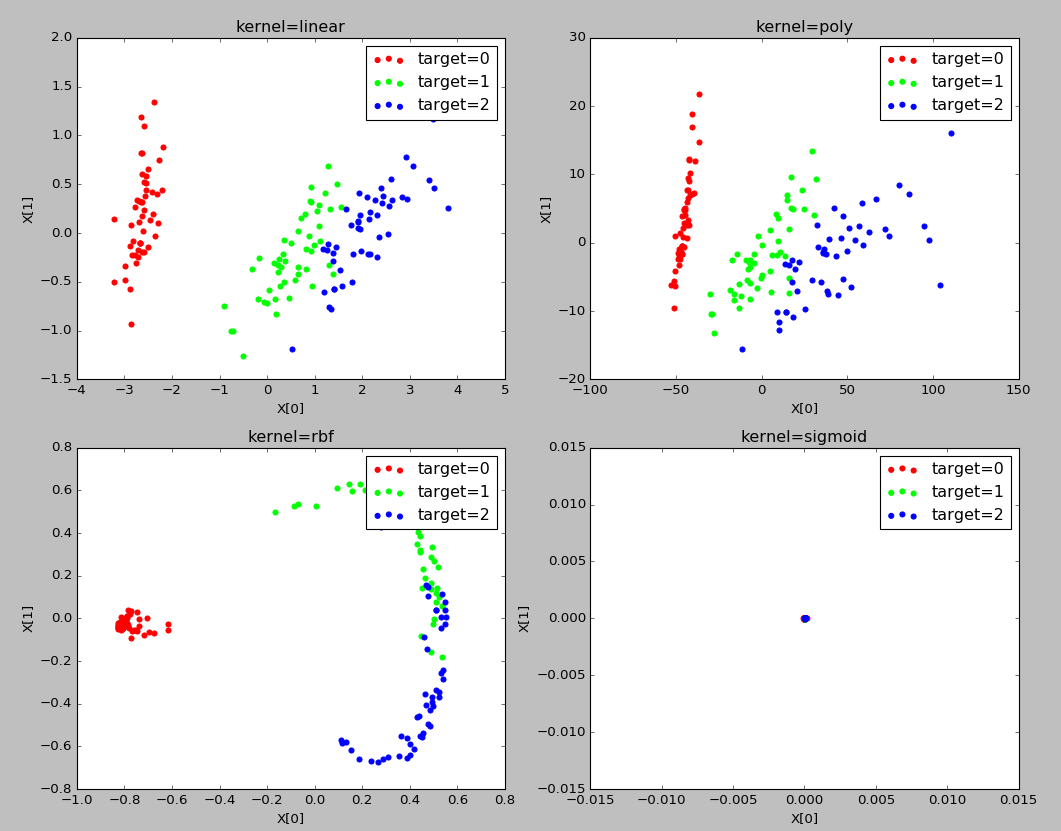
并且采用同样的多项式核函数,如果参数不同,其降维后的数据分布是不同的。因此再具体应用中,可以通过选用不同的核函数以及设置多种不同的参数来对比哪种情况下可以获得最好的效果。
4、流形学习降维
是一种借鉴了拓扑流形概念的降维方法
5、多维缩放(MDS)降维
MDS要求原始空间中样本之间的距离在低维空间中得到保持
输入:距离矩阵D,低维空间维数n'
输出:样本集在低维空间中的矩阵Z
算法步骤:
1)依据公式计算di,.^2,dj,.^2,d.,.^2
2)依据公式计算降维后空间的内积矩阵B
3)对矩阵B进行特征值分解
4)依据求得的对角矩阵和特征向量矩阵,依据公式计算Z
实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold def load_data():
iris=datasets.load_iris()
return iris.data,iris.target def test_MDS(*data):
X,Y=data
for n in [4,3,2,1]:
mds=manifold.MDS(n_components=n)
mds.fit(X)
print("stress(n_components=%d):%s"%(n,str(mds.stress_))) def plot_MDS(*data):
X,Y=data
mds=manifold.MDS(n_components=2)
X_r=mds.fit_transform(X)
# print(X_r) fig=plt.figure()
ax=fig.add_subplot(1,1,1)
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)
for label,color in zip(np.unique(Y),colors):
position=Y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target=%d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[0]")
ax.legend(loc="best")
ax.set_title("MDS")
plt.show() X,Y=load_data()
test_MDS(X,Y)
plot_MDS(X,Y)
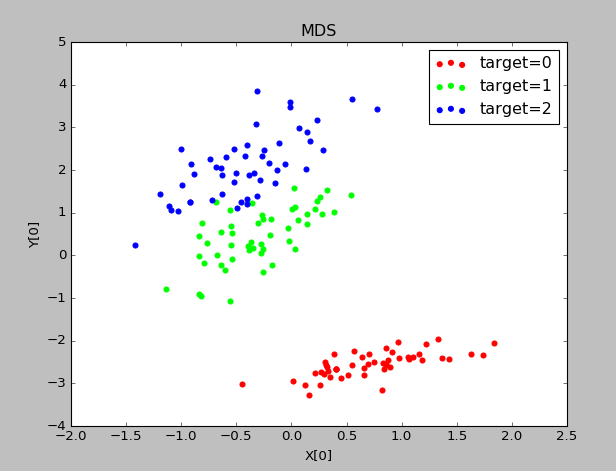
实验结果:
stress表示原始数据降维后的距离误差之和

6、等度量映射(Isomap)降维
输入:样本集D,近邻参数k,低维空间维数n’
输出:样本集在低维空间中的矩阵Z
算法步骤:
1)对每个样本点x,计算它的k近邻;同时将x与它的k近邻的距离设置为欧氏距离,与其他点的距离设置为无穷大
2)调用最短路径算法计算任意两个样本点之间的距离,获得距离矩阵D
3)调用多维缩放MDS算法,获得样本集在低维空间中的矩阵Z
注:新样本难以将其映射到低维空间中,因此需要训练一个回归学习器来对新样本的低维空间进行预测
建立近邻图时,要控制好距离的阈值,防止短路和断路
实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold def load_data():
iris=datasets.load_iris()
return iris.data,iris.target def test_Isomap(*data):
X,Y=data
for n in [4,3,2,1]:
isomap=manifold.Isomap(n_components=n)
isomap.fit(X)
print("reconstruction_error(n_components=%d):%s"%(n,isomap.reconstruction_error())) def plot_Isomap_k(*data):
X,Y=data
Ks=[1,5,25,Y.size-1]
fig=plt.figure()
# colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)
for i,k in enumerate(Ks):
isomap=manifold.Isomap(n_components=2,n_neighbors=k)
X_r=isomap.fit_transform(X)
ax=fig.add_subplot(2,2,i+1)
colors = ((1, 0, 0), (0, 1, 0), (0, 0, 1), (0.5, 0.5, 0), (0, 0.5, 0.5), (0.5, 0, 0.5), (0.4, 0.6, 0), (0.6, 0.4, 0),
(0, 0.6, 0.4), (0.5, 0.3, 0.2),)
for label,color in zip(np.unique(Y),colors):
position=Y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target=%d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[0]")
ax.legend(loc="best")
ax.set_title("k=%d"%k)
plt.suptitle("Isomap")
plt.show() X,Y=load_data()
test_Isomap(X,Y)
plot_Isomap_k(X,Y)
实验结果:

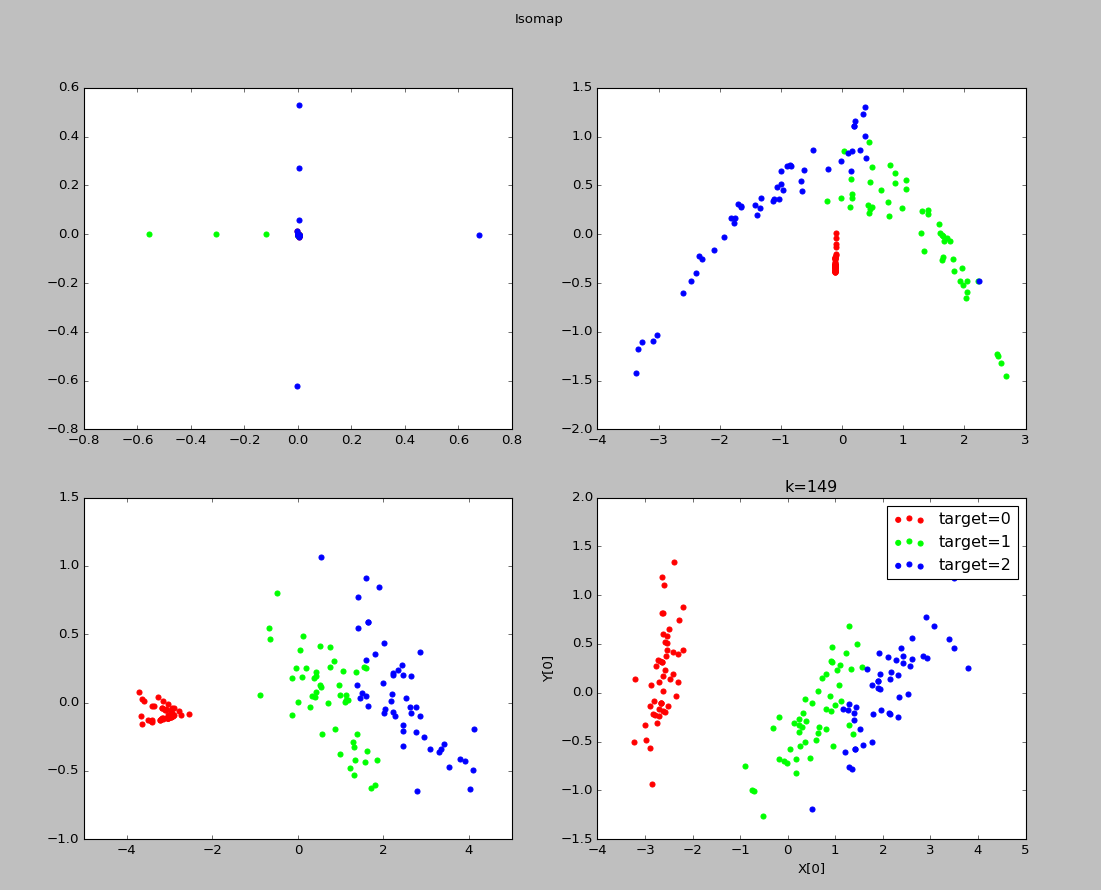
可以看出k=1时,近邻范围过小,此时发生断路现象
7、局部线性嵌入(LLE)
其目标是保持邻域内样本之间的线性关系
输入:样本集D,近邻参数k,低维空间维数n'
输出:样本集在低维空间中的矩阵Z
算法步骤:
1)对于样本集中的每个点x,确定其k近邻,获得其近邻下标集合Q,然后依据公式计算Wi,j
2)根据Wi,j构建矩阵W
3)依据公式计算M
4)对M进行特征值分解,取其最小的n'个特征值对应的特征向量,即得到样本集在低维空间中的矩阵Z
实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold def load_data():
iris=datasets.load_iris()
return iris.data,iris.target def test_LocallyLinearEmbedding(*data):
X,Y=data
for n in [4,3,2,1]:
lle=manifold.LocallyLinearEmbedding(n_components=n)
lle.fit(X)
print("reconstruction_error_(n_components=%d):%s"%(n,lle.reconstruction_error_)) def plot_LocallyLinearEmbedding_k(*data):
X,Y=data
Ks=[1,5,25,Y.size-1]
fig=plt.figure()
# colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)
for i,k in enumerate(Ks):
lle=manifold.LocallyLinearEmbedding(n_components=2,n_neighbors=k)
X_r=lle.fit_transform(X)
ax=fig.add_subplot(2,2,i+1)
colors = ((1, 0, 0), (0, 1, 0), (0, 0, 1), (0.5, 0.5, 0), (0, 0.5, 0.5), (0.5, 0, 0.5), (0.4, 0.6, 0), (0.6, 0.4, 0),
(0, 0.6, 0.4), (0.5, 0.3, 0.2),)
for label,color in zip(np.unique(Y),colors):
position=Y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target=%d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[0]")
ax.legend(loc="best")
ax.set_title("k=%d"%k)
plt.suptitle("LocallyLinearEmbedding")
plt.show() X,Y=load_data()
test_LocallyLinearEmbedding(X,Y)
plot_LocallyLinearEmbedding_k(X,Y)
实验结果:

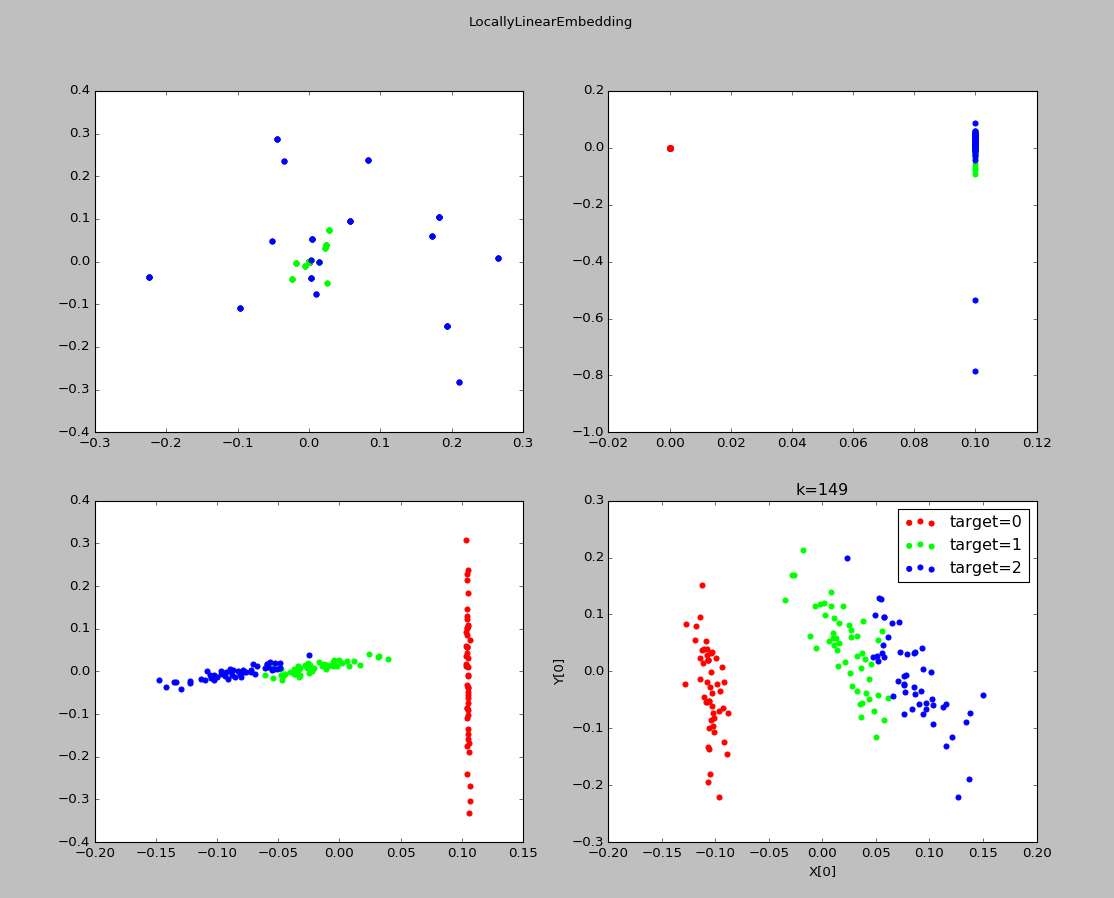
8、总结:
对原始数据采取降维的原因通常有两个:缓解“维度灾难”或者对数据进行可视化。
降维的好坏没有一个直接的标准(包括上面提到的重构误差也只能作为一个中性的指标)。通常通过对数据进行降维,然后用降维后的数据进行学习,再根据学习的效果选择一个恰当的降维方式和一个合适的降维模型参数。
python大战机器学习——数据降维的更多相关文章
- python大战机器学习——数据预处理
数据预处理的常用流程: 1)去除唯一属性 2)处理缺失值 3)属性编码 4)数据标准化.正则化 5)特征选择 6)主成分分析 1.去除唯一属性 如id属性,是唯一属性,直接去除就好 2.处理缺失值 ( ...
- python大战机器学习——模型评估、选择与验证
1.损失函数和风险函数 (1)损失函数:常见的有 0-1损失函数 绝对损失函数 平方损失函数 对数损失函数 (2)风险函数:损失函数的期望 经验风险:模型在数据集T上的平均损失 根据大 ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- python大战机器学习——半监督学习
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数.它是一类可以自动地利用未标记的数据来提升学习性能的算法 1.生成式半监督学习 优点:方法简单,容易实现.通常在有标记数据极少时, ...
- python大战机器学习——人工神经网络
人工神经网络是有一系列简单的单元相互紧密联系构成的,每个单元有一定数量的实数输入和唯一的实数输出.神经网络的一个重要的用途就是接受和处理传感器产生的复杂的输入并进行自适应性的学习,是一种模式匹配算法, ...
- python大战机器学习——支持向量机
支持向量机(Support Vector Machine,SVM)的基本模型是定义在特征空间上间隔最大的线性分类器.它是一种二类分类模型,当采用了核技巧之后,支持向量机可以用于非线性分类. 1)线性可 ...
- python大战机器学习——聚类和EM算法
注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子集(称为一个簇cluster),每个簇潜在地对应 ...
- Python大战机器学习——基础知识+前两章内容
一 矩阵求导 复杂矩阵问题求导方法:可以从小到大,从scalar到vector再到matrix. x is a column vector, A is a matrix d(A∗x)/dx=A d( ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
随机推荐
- linux 进程学习笔记-进程跟踪
进程跟踪 long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data); Linux用ptrace来进行进 ...
- CodeForces - 660F:Bear and Bowling 4(DP+斜率优化)
Limak is an old brown bear. He often goes bowling with his friends. Today he feels really good and t ...
- CF785CAnton and Permutation(分块 动态逆序对)
Anton likes permutations, especially he likes to permute their elements. Note that a permutation of ...
- requirejs的打包工具r.js
不建议用命令行,还是用配置文件比较方便--build.js. 我的build.js文件内容大概如下: ( { appDir : './', baseUrl : './scripts', dir : ' ...
- hdu 2222 Keywords Search——AC自动机
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2222 第一道AC自动机! T了无数边后终于知道原来它是把若干询问串建一个自动机,把模式串放在上面跑:而且只 ...
- js css3实现钟表效果
原理: 利用transform-origin改变旋转的圆心,实现秒数和分钟数的刻度线,利用transfrom translate实现钟表小时刻度的显示 html: <div class=&quo ...
- docker 学习(八) docker file
一 什么是Dockerfile: Dockerfile是由一系列命令和参数构成的脚本,这些命令应用于基础镜像并最终创建一个新的镜像.它们简化了从头到尾的流程并极大的简化了部署工作.Dockerfile ...
- 904E
$dp$ 凉凉.jpg 看到题就想决策单调性,想了一个多小时也没想出来,排名$200+$,$gg$ 事实上,我们只可能每$c$个或每一个分一段,假设我们分了一段长为$c$,如果添加一个新元素,如果新的 ...
- 1、CDH集群搭建
一.准备工作 1.系统环境 系统centos6.5 节点三台: 192.168.1.130 192.168.1.131 192.168.1.132 1.所有节点关闭防火墙 service iptabl ...
- 25.ProfileService实现(调试)
上一节课拿到的AccessToken和IdToken 实现ProfileService类 在服务端 添加ProfileService类 需要继承IProfileServiuce 用到的画图工具 Ipr ...