Scrapy-redis分布式爬虫爬取豆瓣电影详情页
平时爬虫一般都使用Scrapy框架,通常都是在一台机器上跑,爬取速度也不能达到预期效果,数据量小,而且很容易就会被封禁IP或者账号,这时候可以使用代理IP或者登录方式爬,然而代理IP很多时候都很鸡肋,除非使用付费版IP,但是和真实IP差别很大。这时候便有了Scrapy-redis分布式爬虫框架,它基于Scrapy改造,把Scrapy的调度器(scheduler)换成了Scrapy-redis的调度器,可以轻松达到目的,利用多台服务器来爬取数据,而且还可以自动去重,效率高。爬取的数据默认保存在redis缓存中,速度很快。
Scrapy工作原理:

Scrapy-redis工作原理:
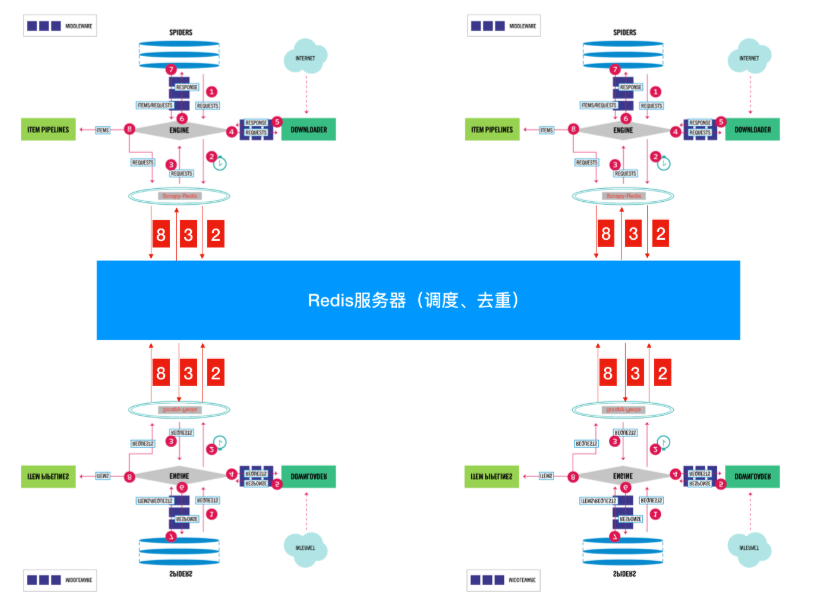
中间的就是调度器
豆瓣电影简易分布式爬虫
我这里直接使用start_urls的方式,数据存入到Mysql中
class DoubanSpider(RedisSpider):
name = 'douban'
redis_key = 'douban:start_urls'
allowed_domains = ['douban.com']
def start_requests(self):
urls = get_urls()
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# item_loader = MovieItemLoader(item=MovieItem, response=response)
#
# item_loader.add_xpath('title', '')
item = MovieItem()
print(response.url)
item['movieId'] = int(response.url.split('subject/')[1].replace('/', ''))
item['title'] = response.xpath('//h1/span/text()').extract()[0]
item['year'] = response.xpath('//h1/span/text()').extract()[1].split('(')[1].split(')')[0] or '2019'
item['url'] = response.url
item['cover'] = response.xpath('//a[@class="nbgnbg"]/img/@src').extract()[0]
try:
item['director'] = response.xpath('//a[@rel="v:directedBy"]/text()').extract()[0] or '无'
except Exception:
item['director'] = '暂无'
item['major'] = '/'.join(response.xpath('//a[@rel="v:starring"]/text()').extract())
item['category'] = ','.join(response.xpath('//span[@property="v:genre"]/text()').extract())
item['time'] = ','.join(response.xpath('//span[@property="v:initialReleaseDate"]/text()').extract())
try:
item['duration'] = response.xpath('//span[@property="v:runtime"]/text()').extract()[0]
except Exception:
item['duration'] = '暂无'
item['score'] = response.xpath('//strong[@property="v:average"]/text()').extract()[0]
item['comment_nums'] = response.xpath('//span[@property="v:votes"]/text()').extract()[0] or 0
item['desc'] = response.xpath('//span[@property="v:summary"]/text()').extract()[0].strip()
actor_list = response.xpath('//ul[@class="celebrities-list from-subject __oneline"]/li/a/@title').extract()
actor_img_list = response.xpath('//ul[@class="celebrities-list from-subject __oneline"]/li/a/div/@style').extract()
actor_img_list = [i.split('url(')[1].replace(')', '') for i in actor_img_list]
item['actor_name_list'] = '----'.join(actor_list)
item['actor_img_list'] = '----'.join(actor_img_list)
yield item
settings.py文件
BOT_NAME = 'MovieSpider'
SPIDER_MODULES = ['MovieSpider.spiders']
NEWSPIDER_MODULE = 'MovieSpider.spiders'
# REDIS_HOST = '127.0.0.1'
# REDIS_PORT = 6379
REDIS_URL = 'redis://username:password@xxx.xxx.xxx.xxx:6379'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300,
'MovieSpider.pipelines.MysqlPipeline': 200,
}
这里只是为了多台服务器一起爬取,没有手动在redis中推入起始的URL
此时将爬虫项目上传到其他服务器上,一起开始
效果如下:
Scrapy-redis分布式爬虫爬取豆瓣电影详情页的更多相关文章
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 9:58 # @Author : 秋泊酱 # @File : 获取豆瓣电影第一页 # @Project : 爬 ...
- python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter= 分析网址'?'符号后的参数,第一个参数's ...
- Python爬虫爬取豆瓣电影名称和链接,分别存入txt,excel和数据库
前提条件是python操作excel和数据库的环境配置是完整的,这个需要在python中安装导入相关依赖包: 实现的具体代码如下: #!/usr/bin/python# -*- coding: utf ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- HTTPS和SSL证书
1. HTTPS工作原理 HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,(目的是安全的获得对称密钥用户后续传输加密)过程的简单描述如下: a).浏览器讲自己支持的多个加 ...
- ASP.NET 中Textbox只能输入数字,不能输入其他字符
解决办法如下: <asp:TextBox ID="txtpage" runat="server" Width="61px" ...
- wcf问题集锦
1.处理程序“svc-Integrated”在其模块列表中有一个错误模块“ManagedPipelineHandler” HTTP 错误 404.3 - Not Found 由于扩展配置问题而无法提供 ...
- 斗鱼扩展初识Chrome扩展(一)
看斗鱼有些时间了,也写了不少辅助的js,但是昨天不小心把硬盘分区表搞没了,自己写了好久的代码不见了,DiskGenius 也没恢复成功,所以要重写一次,大家要引以为鉴,常备份代码,github是个不错 ...
- webpack.config.js====配置babel
参考:https://www.jianshu.com/p/9808f550c6a91. 安装依赖babel-loader: 负责 es6 语法转化babel-preset-env: 包含 es6.7 ...
- 从零开始的全栈工程师——js篇2.15(offsetLeft)
元素的属性 Div.attributes 是所有标签属性构成的数据集合 Div.classList 是所有class名构成的数组集合 在classList的原型链上看以看到add()和remove() ...
- Django--对表的操作
一丶多表创建 1.创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之 ...
- javascript动态修改对象的属性名
在做东钿业务系统的时候,经常碰到写很多重复的ajax对接,于是就想封装一个方法,但是接收data的字段名不一样,所以就需要用到动态对象属性名这个写法了.其实很简单.直接看一下代码吧.
- iis6.0 建立站点
公司网站的服务器甚多 其中还包括早期的iis6.0 的网站服务器 由于之前没有接触过 特此记录建立站点过程和注意事项 1.每个站点最好都新建一个用户名 方便管理 这里操作系统是 winXP 现在运行界 ...
- 【Oracle】曾经的Oracle学习笔记(1-3) 数据库常见用语,常见命令,创建测试表
一.数据库的登录 二.数据库常用语 三.测试表的创建,测试数据初始化 四.常见命令介绍 五.测试 user:jeffreysn:jeffrey user:systemsn:jeffrey 浏览器中输入 ...