Scrapy-redis分布式爬虫爬取豆瓣电影详情页
平时爬虫一般都使用Scrapy框架,通常都是在一台机器上跑,爬取速度也不能达到预期效果,数据量小,而且很容易就会被封禁IP或者账号,这时候可以使用代理IP或者登录方式爬,然而代理IP很多时候都很鸡肋,除非使用付费版IP,但是和真实IP差别很大。这时候便有了Scrapy-redis分布式爬虫框架,它基于Scrapy改造,把Scrapy的调度器(scheduler)换成了Scrapy-redis的调度器,可以轻松达到目的,利用多台服务器来爬取数据,而且还可以自动去重,效率高。爬取的数据默认保存在redis缓存中,速度很快。
Scrapy工作原理:

Scrapy-redis工作原理:
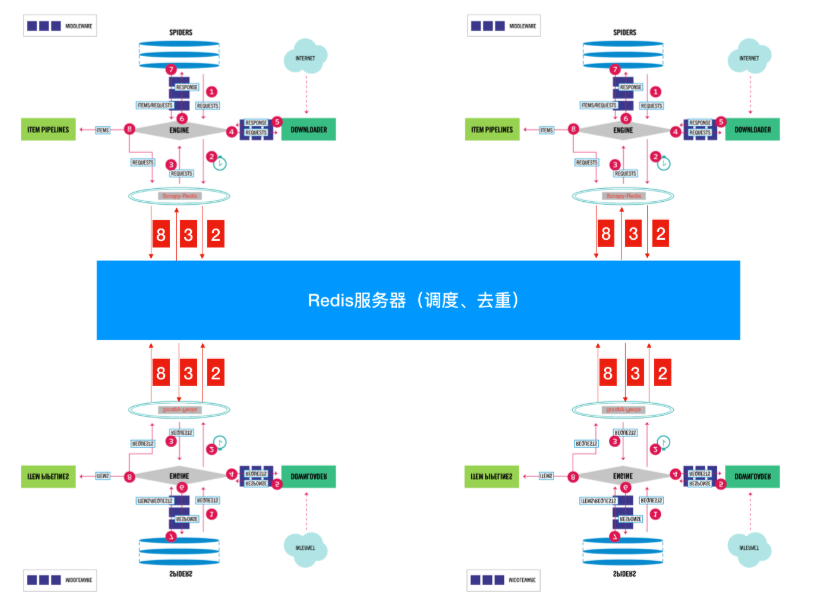
中间的就是调度器
豆瓣电影简易分布式爬虫
我这里直接使用start_urls的方式,数据存入到Mysql中
class DoubanSpider(RedisSpider):
name = 'douban'
redis_key = 'douban:start_urls'
allowed_domains = ['douban.com']
def start_requests(self):
urls = get_urls()
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# item_loader = MovieItemLoader(item=MovieItem, response=response)
#
# item_loader.add_xpath('title', '')
item = MovieItem()
print(response.url)
item['movieId'] = int(response.url.split('subject/')[1].replace('/', ''))
item['title'] = response.xpath('//h1/span/text()').extract()[0]
item['year'] = response.xpath('//h1/span/text()').extract()[1].split('(')[1].split(')')[0] or '2019'
item['url'] = response.url
item['cover'] = response.xpath('//a[@class="nbgnbg"]/img/@src').extract()[0]
try:
item['director'] = response.xpath('//a[@rel="v:directedBy"]/text()').extract()[0] or '无'
except Exception:
item['director'] = '暂无'
item['major'] = '/'.join(response.xpath('//a[@rel="v:starring"]/text()').extract())
item['category'] = ','.join(response.xpath('//span[@property="v:genre"]/text()').extract())
item['time'] = ','.join(response.xpath('//span[@property="v:initialReleaseDate"]/text()').extract())
try:
item['duration'] = response.xpath('//span[@property="v:runtime"]/text()').extract()[0]
except Exception:
item['duration'] = '暂无'
item['score'] = response.xpath('//strong[@property="v:average"]/text()').extract()[0]
item['comment_nums'] = response.xpath('//span[@property="v:votes"]/text()').extract()[0] or 0
item['desc'] = response.xpath('//span[@property="v:summary"]/text()').extract()[0].strip()
actor_list = response.xpath('//ul[@class="celebrities-list from-subject __oneline"]/li/a/@title').extract()
actor_img_list = response.xpath('//ul[@class="celebrities-list from-subject __oneline"]/li/a/div/@style').extract()
actor_img_list = [i.split('url(')[1].replace(')', '') for i in actor_img_list]
item['actor_name_list'] = '----'.join(actor_list)
item['actor_img_list'] = '----'.join(actor_img_list)
yield item
settings.py文件
BOT_NAME = 'MovieSpider'
SPIDER_MODULES = ['MovieSpider.spiders']
NEWSPIDER_MODULE = 'MovieSpider.spiders'
# REDIS_HOST = '127.0.0.1'
# REDIS_PORT = 6379
REDIS_URL = 'redis://username:password@xxx.xxx.xxx.xxx:6379'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300,
'MovieSpider.pipelines.MysqlPipeline': 200,
}
这里只是为了多台服务器一起爬取,没有手动在redis中推入起始的URL
此时将爬虫项目上传到其他服务器上,一起开始
效果如下:
Scrapy-redis分布式爬虫爬取豆瓣电影详情页的更多相关文章
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 9:58 # @Author : 秋泊酱 # @File : 获取豆瓣电影第一页 # @Project : 爬 ...
- python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter= 分析网址'?'符号后的参数,第一个参数's ...
- Python爬虫爬取豆瓣电影名称和链接,分别存入txt,excel和数据库
前提条件是python操作excel和数据库的环境配置是完整的,这个需要在python中安装导入相关依赖包: 实现的具体代码如下: #!/usr/bin/python# -*- coding: utf ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- 车牌号校验js
var regExp = /(^[\u4E00-\u9FA5]{1}[A-Z0-9]{6}$)|(^[A-Z]{2}[A-Z0-9]{2}[A-Z0-9\u4E00-\u9FA5]{1}[A-Z0-9 ...
- nginx 添加https支持
自行颁发不受浏览器信任的SSL证书为晒晒IQ网颁发证书.ssh登陆到服务器上,终端输入以下命令,使用openssl生成RSA密钥及证书. # 生成一个RSA密钥 $ openssl genrsa -d ...
- java CountDownLatch 等待多线程完成
CountDownLatch允许一个或多个线程等待其他线程完成操作. package com.test; import java.util.concurrent.CountDownLatch; pub ...
- sqlserver2008执行200M以上的大脚本文件,打开脚本总是报“未能完成操作,存储空间不足”
用sqlcmd命令行工具. 1.win7下快捷键:win+R 2.输入cmd,确定 3.输入命令:sqlcmd -S <数据库> -i C:\<数据文件>.sql 例:sql ...
- C 碎片六 函数
一.程序编译执行过程 程序的编译执行过程分为4个阶段:预处理阶段.编译阶段.汇编阶段.连接阶段 1. 预处理阶段:预处理器(cpp)处理以头文件.宏.条件编译(字符#开头)等内容的替换.此阶段不进行语 ...
- i++ ++i i=i+1 和i+=1
这几个运算符的差别总是过一段时间就爱搞混,每次需要百度,还是自己记录一下方便查阅. int i=0; System.out.println(i++); 输出:0 int i=0; System.out ...
- Android RecycleView实现混合Item布局
首先来看看效果吧: 效果预览.png 本实例来自于慕课网的视屏http://www.imooc.com/video/13046,实现步骤可以自己去观看视屏,这里只记录了下实现的代码. 添加依赖: (1 ...
- linux 后渗透测试
学习参考: http://weibo.com/1869235073/B9Seswf9R?type=comment http://weibo.com/p/1001603723521007220513 h ...
- 倍增LCA
前言 在做树上问题时,我们经常会遇到 \(LCA\)(最近公共祖先)问题.曾经的我遇到这类问题只会\(O(n)\)暴力求解,学了倍增\(LCA\),就可以\(O(logn)\)解决了. 简介 倍增\( ...
- 在ListBox控件间交换数据
实现效果: 知识运用: ListBox控件的SelectedItem属性 //获取或设置ListBox控件中当前选定的数据项 public Object SelectedItem{ get;set; ...