Python之将Python字符串生成PDF
笔者在今天的工作中,遇到了一个需求,那就是如何将Python字符串生成PDF。比如,需要把Python字符串‘这是测试文件’生成为PDF, 该PDF中含有文字‘这是测试文件’。
经过一番检索,笔者决定采用wkhtmltopdf这个软件,它可以将HTML转化为PDF。wkhtmltopdf的访问网址为:https://wkhtmltopdf.org/downloads.html ,读者可根据自己的系统下载对应的文件并安装。安装好wkhtmltopdf,我们再安装这个软件的Python第三方模块——pdfkit,安装方式如下:
pip install pdfkit
我们再讨论如下问题:
- 如何将Python字符串生成PDF;
- 如何生成PDF中的表格;
- 解决PDF生成速度慢的问题。
如何将Python字符串生成PDF
该问题的解决思路还是利用将Python字符串嵌入到HTML代码中解决,注意换行需要用<br>标签,示例代码如下:
import pdfkit
# PDF中包含的文字
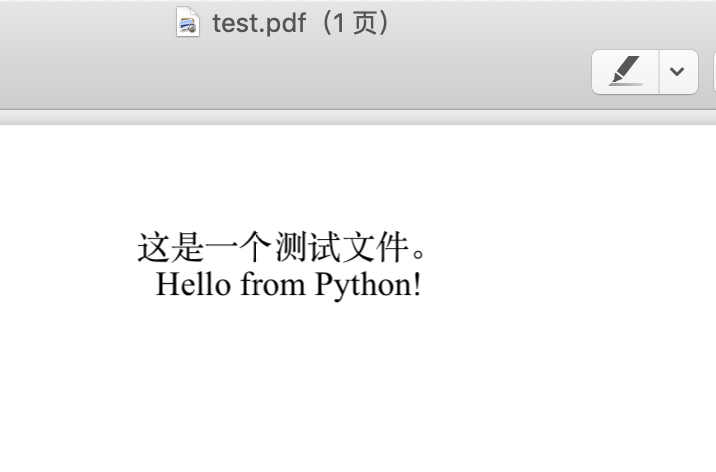
content = '这是一个测试文件。' + '<br>' + 'Hello from Python!'
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center"><p>%s</p></div></body></html>'%content
# 转换为PDF
pdfkit.from_string(html, './test.pdf')
输出的结果如下:
Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
生成的test.pdf如下:
如何生成PDF中的表格
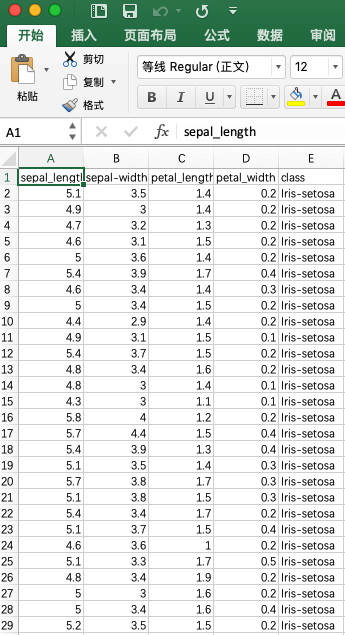
接下来我们考虑如何将csv文件转换为PDF中的表格,思路还是利用HTML代码。示例的iris.csv文件(部分)如下:
将csv文件转换为PDF中的表格的Python代码如下:
import pdfkit
# 读取csv文件
with open('iris.csv', 'r') as f:
lines = [_.strip() for _ in f.readlines()]
# 转化为html中的表格样式
td_width = 100
content = '<table width="%s" border="1" cellspacing="0px" style="border-collapse:collapse">' % (td_width*len(lines[0].split(',')))
for i in range(len(lines)):
tr = '<tr>'+''.join(['<td width="%d">%s</td>'%(td_width, _) for _ in lines[i].split(',')])+'</tr>'
content += tr
content += '</table>'
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './iris.pdf')
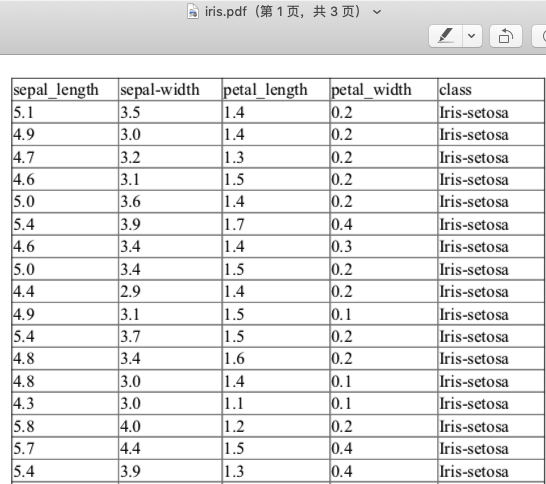
生成的PDF文件为iris.pdf,部分内容如下:
解决PDF生成速度慢的问题
用pdfkit生成PDF文件虽然方便,但有一个比较大的缺点,那就是生成PDF的速度比较慢,这里我们可以做个简单的测试,比如生成100份PDF文件,里面的文字为“这是第*份测试文件!”。Python代码如下:
import pdfkit
import time
start_time = time.time()
for i in range(100):
content = '这是第%d份测试文件!'%(i+1)
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './test/%s.pdf'%(i+1))
end_time = time.time()
print('一共耗时:%s 秒.' %(end_time-start_time))
在这个程序中,生成100份PDF文件一共耗时约192秒。输出结果如下:
......
Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
一共耗时:191.9226369857788 秒.
如果想要加快生成的速度,我们可以使用多线程来实现,主要使用concurrent.futures模块,完整的Python代码如下:
import pdfkit
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
start_time = time.time()
# 函数: 生成PDF
def convert_2_pdf(i):
content = '这是第%d份测试文件!'%(i+1)
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './test/%s.pdf'%(i+1))
# 利用多线程生成PDF
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers,即线程的个数
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(convert_2_pdf, i) for i in range(100)]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
end_time = time.time()
print('一共耗时:%s 秒.' %(end_time-start_time))
在这个程序中,生成100份PDF文件一共耗时约41秒,明显快了很多~
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~
Python之将Python字符串生成PDF的更多相关文章
- asp.net MVC设计模式中使用iTextSharp实现html字符串生成PDF文件
因个人需求,需要将html格式转换成PDF并加上水印图片.于是乎第一次接触这种需求的小菜鸟博主我,在某度搜索引擎上不断的查阅关键字资料.踩坑,终于有了一个相应的解决方案.以下是解决步骤,记录下来方便以 ...
- html 字符串 生成 pdf 完美解决中文不显示
//maven <dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf< ...
- 使用puppeteer生成pdf与截图
之前写过一篇 vue cli2 使用 wkhtmltopdf 踩坑指南,由于wkhtmltopdf对vue的支持并不友好,而且不支持css3,经过调研最终选择puppeteer,坑少,比较靠谱. 一. ...
- c#实例化继承类,必须对被继承类的程序集做引用 .net core Redis分布式缓存客户端实现逻辑分析及示例demo 数据库笔记之索引和事务 centos 7下安装python 3.6笔记 你大波哥~ C#开源框架(转载) JSON C# Class Generator ---由json字符串生成C#实体类的工具
c#实例化继承类,必须对被继承类的程序集做引用 0x00 问题 类型“Model.NewModel”在未被引用的程序集中定义.必须添加对程序集“Model, Version=1.0.0.0, Cu ...
- Python数据生成pdf文件
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- python之reportlab生成PDF文件
项目需要,需要自动生成PDF测试报告.经过对比之后,选择使用了reportlab模块. 项目背景:开发一个测试平台,供测试维护测试用例,执行测试用例,并且生成测试报告(包含PDF和excel),将生成 ...
- Python之路-python数据类型(列表、字典、字符串、元祖)操作
一.列表: 列表的语法,以中括号开通和结尾,元素以逗号隔开.例如:name = [] 列表是以下标取值,第一个元素下标是0,第二个元素下标是1,最后一个元素下标是-1. 1.增加 #name = ...
- Python内置的字符串处理函数整理
Python内置的字符串处理函数整理 作者: 字体:[增加 减小] 类型:转载 时间:2013-01-29我要评论 Python内置的字符串处理函数整理,收集常用的Python 内置的各种字符串处理 ...
- Python核心编程第二版(中文).pdf 目录整理
python核心编程目录 Chapter1:欢迎来到python世界!-页码:7 1.1什么是python 1.2起源 :罗萨姆1989底创建python 1.3特点 1.3.1高级 1.3.2面向 ...
随机推荐
- 大家都是怎么看待STO的?
STO,全称为「Security Token Offer」,即证券型通证发行.STO是2017年底从美国开始流行的,对于在美国注册的公司,STO是一个合法合规的ICO. 对于STO,大家都是怎么看待的 ...
- Java图像处理最快技术:ImageJ 学习第一篇
ImageJ是世界上最快的纯Java的图像处理程序. 它能够过滤一个2048x2048的图像在0.1秒内(*). 这是每秒40万像素!ImageJ的扩展通过使用内置的文本编辑器和Java编译器的Ima ...
- VIM中使用tab键自动完成(vim tab键自动补全 )插件supertab
supertab.vmb 这个插件好好用, Tab自动补全 http://www.vim.org/scripts/script.php?script_id=1643 安装步骤: 1.下载 supert ...
- 安装pymysqlpool并使用(待补充)
pip3 install PyMysqlPool 第一个错,提示没有装c++ 14.0,下载安装报下一个错 error: Setup script exited with error: Microso ...
- POJ - 1321 棋盘问题 【DFS】
题目链接 http://poj.org/problem?id=1321 思路 和N皇后问题类似 但是有一点不同的是 这个是只需要摆放K个棋子就可以了 所以 我们要做好 两个出口 并且要持续往下一层找 ...
- BFC和haslayout(IE6-7)(待总结。。。)
支持BFC的浏览器(IE8+,firefox,chrome,safari) Block Formatting Context(块格式化上下文)是W3C CSS2.1规范中的一个慨念,在CSS3中被修改 ...
- TS流分析
http://blog.csdn.net/zxh821112/article/details/17587215 一 从TS流开始 数字电视机顶盒接收到的是一段段的码流,我们称之为TS(Transpor ...
- Linux学习之路(二)文件处理命令之下
分区格式化: 一块分区想要使用的话,要格式化.格式化主要有两个工作,1,把分区分成等大小的数据块,每个数据块一般为4KB.2在分区之前建一个分区表,给第一个文件建一行相关数据,在分区表里保存了它的io ...
- Android SDK离线安装方法详解(加速安装)
AndroidSDK在国内下载一直很慢··有时候通宵都下不了一点点,最后只有选择离线安装,现在发出离线安装地址和方法,希望对大家有帮助 一,首先下载SDK的安装包,android-sdk_r10-wi ...
- Jmeter-配置原件-HTTP Cookie管理器
线程组右键 -- 添加 -- 配置原件 -- HTTP Cookie管理器 如何定位到自己的cookie?以Google Chrome浏览器为例: 1.打开浏览器,打开开发者工具 2.登录站点 3 ...