(原)torch中微调某层参数
转载请注明出处:
http://www.cnblogs.com/darkknightzh/p/6221664.html
参考网址:
https://github.com/torch/nn/issues/873
http://stackoverflow.com/questions/37459812/finetune-a-torch-model
https://github.com/torch/nn/blob/master/doc/module.md
https://github.com/torch/torch7/blob/master/doc/utility.md
=====================================================
170928更新(可以微调层):
参考网址:
http://www.thedataware.com/post/the-torch-adventures-setting-layer-wise-training-parameters
https://github.com/NVIDIA/DIGITS/tree/master/examples/fine-tuning
https://github.com/NVIDIA/DIGITS/blob/master/examples/fine-tuning/lenet-fine-tune.lua#L56
https://stackoverflow.com/questions/37459812/finetune-a-torch-model
https://www.zhihu.com/question/44376850
说明:目前就第一个网址的能finetune参数。
深度学习中目前有参数的为:卷积层-conv(weight+bias),batchnorm层:bn(weight+bias),全连接层-linear(weight+bias)。
因而在torch中使用local params, gradParams = model:parameters()的话,默认得到的#params为上面这三种类型的层的数量之和再乘以2。如果对应没有bias,则该层参数参数数量为1。
使用http://www.thedataware.com/post/the-torch-adventures-setting-layer-wise-training-parameters的方法,可以更新某个层。该文章是每个层设置不同的学习率,如果只某些特定的层学习率不为0,其它层学习率均为0(或者先定义fineTuneLayerIdx={10,11,12},而后for i = 1, #params改成for i = 1, #fineTuneLayerIdx来减少计算量),则会只更新这些层的参数。需要注意的是,如果fine tune最后几层还好,可以print(params),来看一下参数,然后计算一下哪些参数是需要更新的,如果更新中间的层。。。只能自己去对应了(特别是如Inception,Resnet这种网络中间层的参数,对应起来更加蛋疼了吧)。
该网址中对每层都设置学习率的代码如下:
local params, gradParams = model:parameters() -- Set the learning rate to 0.01
local learningRates = torch.Tensor(#params):fill(0.01)
-- Set the learning rate of the second layer to 0.001
learningRates[] = 0.001 optimState = {}
for i = , #params do
table.insert(optimState, {
learningRate = learningRates[i],
learningRateDecay = 0.0001,
momentum = 0.9,
dampening = 0.0,
weightDecay = 5e-4
})
end for e = , epochs do
-- Get MNIST batch
X, Y = get_mnist_batch(batch_size) -- forward -> backward (outside of feval)
model:zeroGradParameters()
out = model:forward(X)
err = criterion:forward(out, Y)
gradOutputs = criterion:backward(out, Y)
model:backward(X, gradOutputs) -- layer-wise optimization
for i = , #params do
local feval = function(x)
return err, gradParams[i]
end -- run optimizer
optim.sgd(feval, params[i], optimState[i])
end end
-- model trained
如果使用fineTuneLayerIdx,即只微调部分层,代码如下:
local params, gradParams = model:parameters() -- 需要finetune的参数层(不是网络层。网络层:内部可能还有更小的网络,比如densenet,resnext等;
-- 参数层:正常情况下,一个conv,bn,linear等各有2个参数层,所以参数曾可能比网络成多很多)
local fineTuneLayerIdx = {,,} -- Set the learning rate to 0.01
local learningRates = torch.Tensor(#fineTuneLayerIdx):fill(0.01)
-- Set the learning rate of the second layer to 0.001
learningRates[] = 0.001 optimState = {}
for i = , #fineTuneLayerIdx do
table.insert(optimState, {
learningRate = learningRates[i],
learningRateDecay = 0.0001,
momentum = 0.9,
dampening = 0.0,
weightDecay = 5e-4
})
end for e = , epochs do
-- Get MNIST batch
X, Y = get_mnist_batch(batch_size) -- forward -> backward (outside of feval)
model:zeroGradParameters()
out = model:forward(X)
err = criterion:forward(out, Y)
gradOutputs = criterion:backward(out, Y)
model:backward(X, gradOutputs) -- layer-wise optimization
for i = , #fineTuneLayerIdx do
local feval = function(x)
return err, gradParams[fineTuneLayerIdx[i]]
end -- run optimizer
optim.sgd(feval, params[fineTuneLayerIdx[i]], optimState[i])
end end
-- model trained
需要注意的是,如果使用model:parameters(),需要optimState为多个table,不能为下面这样简单的一个table:
optimState = { -- 使用model:parameters()时,使用这种optimState有问题
learningRate = learningRates,
learningRateDecay = 0.0001,
momentum = 0.9,
dampening = 0.0,
weightDecay = 5e-4
}
否则在第二次运行到optim.sgd(feval, params[fineTuneLayerIdx[i]], optimState[i])时,可能会提示维度不一样。
另外,https://www.zhihu.com/question/44376850中“知乎用户”的回答也和这个类似,只不过不知道那个网址中的和这个网址中的谁先谁后吧。
如果使用https://stackoverflow.com/questions/37459812/finetune-a-torch-model中的方法,即:
for i=, x do
c = model:get(i)
c.updateGradInput = function(self, inp, out) end
c.accGradParameters = function(self,inp, out) end
end
我这边有conv、bn,linear这三种层,会提示下面bn层的错误,不清楚是我这边程序的问题,还是怎么回事。
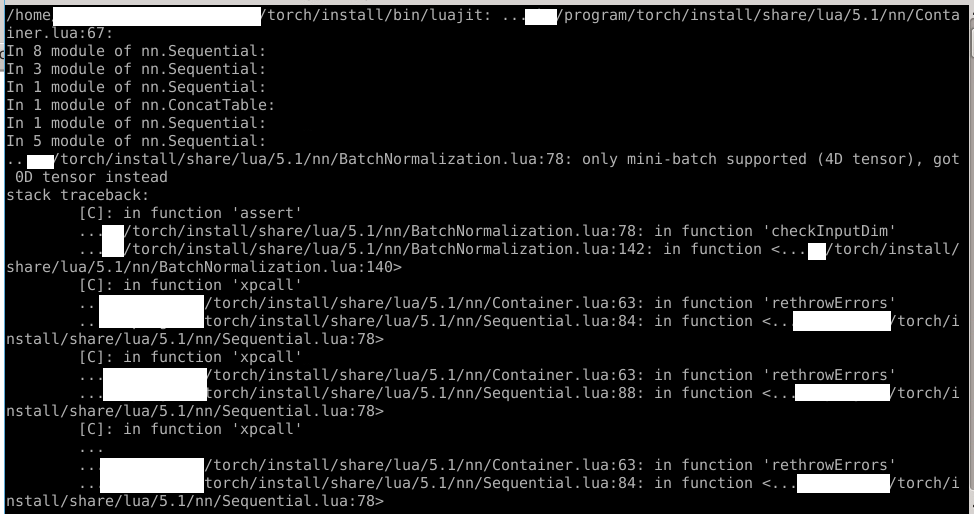
如果使用https://github.com/NVIDIA/DIGITS/blob/master/examples/fine-tuning/lenet-fine-tune.lua#L56这种方法,其实和上面的类似,只不过没有设置每层的updateGradInput这个。只设置一个的话,同样的输入,每次输出不一样(我把所有的conv,bn,linear都设置了= function(self, inp, out) end,为了看一下输出是否一致。理论上如果这些层参数都不更新,同样的输入,最终的输出应该相同),即感觉没能fine tune特定的层。
170928更新结束
=====================================================
161229更新:
感谢@linzhineng 。
即便按照本文这样设置,实际上在微调时,其它层的参数还是会变化。现在凌乱了,不清楚如何微调了/(ㄒoㄒ)/~~
难道只能手动修改更新过程吗?
161229更新结束:
=====================================================
由于torch每个模块均有train参数,当其为true时进行训练,当期为false时进行测试。因而,如果要对训练好的模型进行微调,如只对某模块调整参数,其他模块参数固定,则可以使用第一个参考网址中soumith的方法(该方法固定某模块,和本文目的是反的):
model:training()
model:apply(function(m) if torch.type(m):find("BatchNormalization") then m:evaluate() end end)
说明:一般来说,在训练时,需要设置model:training(),在测试时,需要设置model:evaluate()。因而微调参数时,上面代码加在训练代码中model:training()后面就可以了(需要适当的修改)。
第四个网址给出了[string] torch.type(object)。因而,对上面的代码修改如下:如果要达到微调某一模块参数(如全连接层Linear),只需要使用:
model:evaluate()
model:apply(function(m)
if torch.type(m):find('Linear') then
m:training()
end
end)
说明:上面代码测试后成功。但是遇到了一个很诡异的问题。如果第一行改为model:training(),在找到对应的层后,改为m: evaluate (),没有成功(对应的torch.type(m):find('Linear')==nil),所以才使用了上面的代码。还有一点,如果判断torch.type(m):find('Linear')==nil,最后没有成功改了m的train变量的值,具体不太清楚,最终使用了上面给出的代码。
上面torch.type(m)会返回模块的名字,如:
nn.Sequential
nn.SpatialConvolution
nn.SpatialBatchNormalization
nn.ReLU
nn.SpatialMaxPooling
nn.SpatialConvolution
nn.SpatialBatchNormalization
nn.ReLU
上面torch.type(m):find("BatchNormalization"),如果在某层找到了BatchNormalization,则返回找到的起始和结束位置,否则返回nil。
还有,微调时,一般都只微调某一层,但是torch中很多层名字相同,如果要改特定的一层,如conv层,还要继续修改代码,判断是否是需要的那个conv层,否则会将所有的conv层参数都修改。
注意:如果网络定义使用了Inception层,此处不光返回Inception,还会返回Inception里面各个层(如nn.Sequential,nn.InceptionHisign,nn.DepthConcat等)。
在torch/install/share/lua/5.1/nn/Module.lua中,有如下代码:
function Module:training()
self.train = true
end function Module:evaluate()
self.train = false
end
直觉上,torch中这种方式不如caffe的fine tuning时,设置对应层lr_mult=0容易。
第三个网址有对apply,training,evaluate的较详细的说明。
此外,第二个网址通过updateGradInput和accGradParameters来达到固定某层参数的效果,不过没有试过。
(原)torch中微调某层参数的更多相关文章
- (原)torch和caffe中的BatchNorm层
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6015990.html BatchNorm具体网上搜索. caffe中batchNorm层是通过Batc ...
- (原)torch中threads的addjob函数使用方法
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6549452.html 参考网址: https://github.com/torch/threads#e ...
- java web项目中后台控制层对参数进行自定义验证 类 Pattern
Pattern pattern = Pattern.compile("/^([1-9]\d+元*|[0]{0,1})$/");//将给定的正则表达式编译到模式中 if(!" ...
- Caffe常用层参数介绍
版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn.net/Cheese_pop/article/details/52024980 DATA crop:截取原图像中一个 ...
- CNN中减少网络的参数的三个思想
CNN中减少网络的参数的三个思想: 1) 局部连接(Local Connectivity) 2) 权值共享(Shared Weights) 3) 池化(Pooling) 局部连接 局部连接是相对于全连 ...
- Java原子类中CAS的底层实现
Java原子类中CAS的底层实现 从Java到c++到汇编, 深入讲解cas的底层原理. 介绍原理前, 先来一个Demo 以AtomicBoolean类为例.先来一个调用cas的demo. 主线程在f ...
- Tensorflow训练和预测中的BN层的坑
以前使用Caffe的时候没注意这个,现在使用预训练模型来动手做时遇到了.在slim中的自带模型中inception, resnet, mobilenet等都自带BN层,这个坑在<实战Google ...
- (8)视图层参数request详解
PS:浏览器页面请求的都是get请求 PS:post请求是通过form表单,阿贾克斯发 request里面的常用方法 def index(request): print(request.META) # ...
- torch中的多线程threads学习
torch中的多线程threads学习 torch threads threads 包介绍 threads package的优势点: 程序中线程可以随时创建 Jobs被以回调函数的形式提交给线程系统, ...
随机推荐
- LINUX的命令(未完待续)
遇到忘了的Linux命令,复习之后,把它记在这里,供以后复习. ^C:刚开始在看视频的时候发现上面有cd ^C,还以为这是个什么命令,其实^C这不是输入进去的,当你按了Ctrl+C之后就会出现^C,C ...
- java-map-EnumMap
在平常的项目中,enumMap是比较少用到的一种map,一般都不会使用到这种容器,那么我将从如下几个方面来阐述我对enumMap的理解 1.使用场景 在key是比较固定的情况下,使用enumMap是最 ...
- navicat:cannot create oci environment
1.请注意红色箭头处的配置是从oracle官网下载的安装包 ,当然百度也是很强大的.(建议是在navicat安装目录下解压) 2.红色方框内的是你本地的oracle数据库的sqlplus.exe启动地 ...
- LPC1758串口ISP下载程序
最近手上拿到一块人家公司做的3D打印机的板子,用的核心芯片是LPC1758,板上引出了ISP下载接口.那接口共4个引出脚,如下图所示: 其中ME_EN引脚又连接到了芯片的P2[10]引脚,那个引脚 ...
- MongoDB insert/update/one2many案例
以博文与评论为例,博文有标题内容,对应多个评论,评论有评论人.评论内容等. ()插入一条博文: db.blog.insert( {','title':'this is blog title1','co ...
- poj 3277 Mountains
http://poj.org/problem?id=3227 #include <cstdio> #include <cstring> #include <cmath&g ...
- Altium Designer 蛇行等长布线
一. 设置需要等长的网络组 点击主菜单 Design --> Classes,在弹出的窗口中单击 Net Classes,并右键,点 Add Class 会增加一个 New Class,在该网络 ...
- 【转】24. android dialog ——ProgressDialog 进度条对话框详解
原文网址:http://blog.csdn.net/jamesliulyc/article/details/6375598 首先在onCreateDialog方法里创建一个ProgressDialog ...
- HDU_2013——蟠桃记,反向推理
Problem Description 喜欢西游记的同学肯定都知道悟空偷吃蟠桃的故事,你们一定都觉得这猴子太闹腾了,其实你们是有所不知:悟空是在研究一个数学问题!什么问题?他研究的问题是蟠桃一共有多少 ...
- 为什么 HTTP 有时候比 HTTPS 好?
做为一家安全公司,我们在站点Stormpath上经常被开发者问到的是有关安全方面最优做法的问题.其中一个被经常问到的问题是: 我是否应当在站点上运行HTTPS? 很不幸,查遍整个因特网,你大多数情况下 ...