RealFormer: 残差式 Attention 层的Transformer 模型
原创作者 | 疯狂的Max
01 背景及动机
Transformer是目前NLP预训练模型的基础模型框架,对Transformer模型结构的改进是当前NLP领域主流的研究方向。
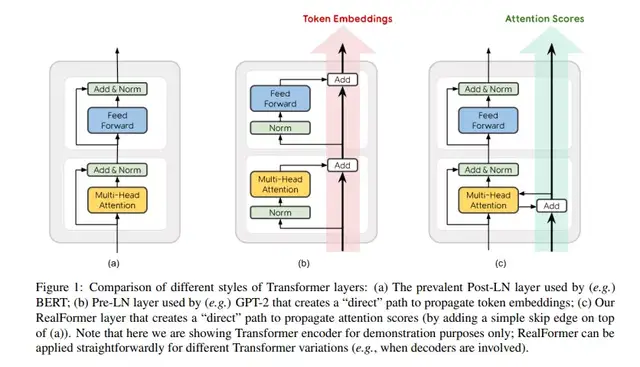
Transformer模型结构中每层都包含着残差结构,而残差结构中最原始的结构设计是Post-LN结构,即把Layer Norm (LN) 放在每个子层处理之后,如下图Figure 1(a)所示;而其他的一些预训练模型如GPT-2,则将LN改到每个子层处理之前,被定义为Pre-LN,如下图Figure 1(b),有论文[5]结果表明“Pre-LN”对梯度下降更加友好,收敛更快,更易于超参优化,但其性能总差于“Post-LN”。
为解决这个问题,本文作者提出 RealFormer 模型(Residual Attention Layer Transformer),如下图Figure 1(c)所示,将残差结构运用到attention层,使得模型对训练超参更具鲁棒性的同时,保证模型性能的提升。
而残差结构来源于图像领域经典的Resnet模型[6],可以有效解决深层神经网络中的梯度弥散/扩散和网络退化的问题[7],NLP领域Transformer经典结构[2]同图像领域模型一样,也拥有“窄而深”的模型,因此也当然可以通过残差结构来达到优化网络的目的,这也是Transformer结构中本身就设计了残差结构的原因。
具体来说,RealFormer相较于前面提到的两种结构(“Pre-LN”和“Post-LN”)不同在于,模型在每层中计算所有头的attention score时,加上了残差结构,即本层的attention score加上之前层的attention score。
值得注意的是,直接在attention计算时增加跳连连接并不会增加指数级的运算量,因此其效率是相对可观的。
本文的主要贡献在于:
1)RealFormer是一种在原始Transformer结构上的简单改进,只需要修改几行代码并且不需要过多的超参调整;
2)RealFormer的表现在不同规模的模型上都优于Post-LN和Pre-LN结构的模型;
3)RealFormer在包括GLUE在内的各种下游任务中提升了原始BERT的表现,并且当训练轮数只有一半时也可以到达相应的最强基线模型标准;
4)作者通过量化分析的方式证明了RealFormer与基线BERT模型相比,每层的attention更为稀疏和强关联,这样的正则化效果也有利于模型的稳定训练,并使得模型对超参调节更具有鲁棒性。
02 模型方法
1.标准Transformer模型结构
Transformer由encoder和decoder组成,两者的结构相似,以其encoder中一层来进行说明。Transformer层由2个子层构成,第一个子层包含多头注意力模块和对应的残差连接,第二个子层包含一个全连接的前向网络模块和对应的残差链接。Post-LN和Pre-LN的区别在于,Layer Norm在残差连接之前或之后。
2.残差式Attention层的Transformer结构
RealFormer沿用了Post-LN的模型设计,只是在每个Transformer层计算多头注意力事,加入前一层的Attention Scores矩阵。即计算第n层的注意力矩阵时,从公式(1)变为了公式(2)。
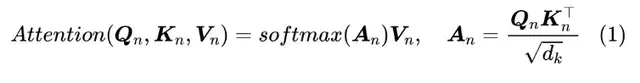
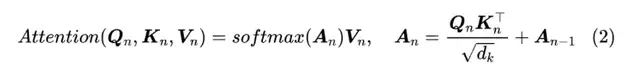
实现以上计算方式的改变只需要在Transformer的模型代码中做很少的代码改动,并且网络中不止一种类型的attention模块时也适用。
比如,在机器翻译模型中的encoder-encoder self-attention,encoder-decoder attention,decoder-decoder self-attention的模块都可以直接运用这样的计算改进方案。
作者特别提到,之所以沿用Post-LN的结构,是因为在同等合理算力的限制下,Post-LN比Pre-LN表现更好,这也正如本文[1]Section 4部分阐述实验结果时所论述的一样。
03 实验结果
作者将RealFormer模型,Post-LN结构模型、Pre-LN结构模型在预训练任务和下游任务的表现进行了对比分析。
1.预训练任务实验结果
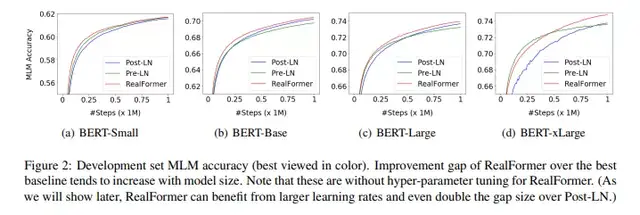
首先,从预训练任务的表现结果来看,在不同规模的模型之下,RealFormer模型表现都优于其他两种结构。而随着模型规模的扩大,RealFormer结构的优势表现的更为明显,如下表Table 2所示。
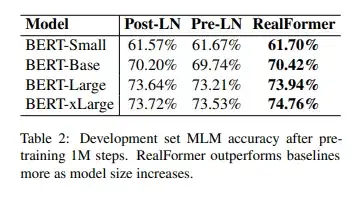
另外,作者推测越大的模型更难以训练,而Post-LN的结构存在不稳定性。并且在xLarge的规模之下甚至会不收敛。RealFormer结构有助于模型的正则化和使得训练更加稳定,如下图Figure 2所示。
2.下游任务实验结果
三种模型在下游任务实验结果如下表Table 4所示:
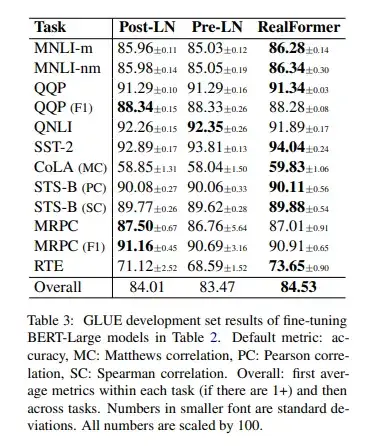
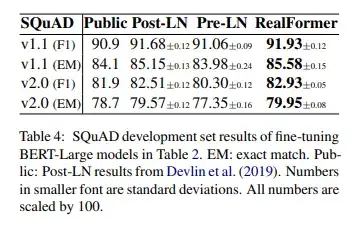
在GLUE的各项下游任务和SQuAD下游任务的实验结果来看,RealFormer的表现是最佳的。
3.研究问题
1)在只有一半预训练算力预算的基础下,RealFormer效果如何?
在1M训练步数的情况下,RealFormer的表现超越了Post-LN和Pre-LN。那么在训练算力限制更为严格的情况下,RealFormer表现是否也会更佳,因此作者进行了相关对比实验,结果如下图所示。
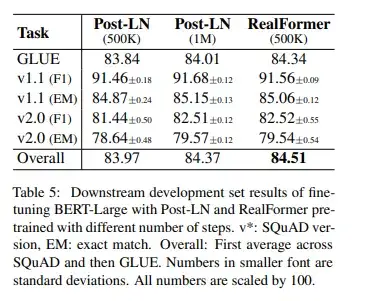
结果表明,在训练步数被限制为500K时,RealFormer在GLUE下游任务上的甚至优于训练1M的Post-LN模型,而SQuAD下游任务上的表现也相差不多。
2)使用更大的学习率,RealFormer表现如何?
之前的一些论文表明Pre-LN相较Post-LN,更能从增加学习率中受益。受此启发,作者沿用之前预训练的步骤训练BERT-Large,只是将学习率增加到2e-4,并用3种模型结构进行实验。模型在MLM预训练任务上的准确率如下图所示:
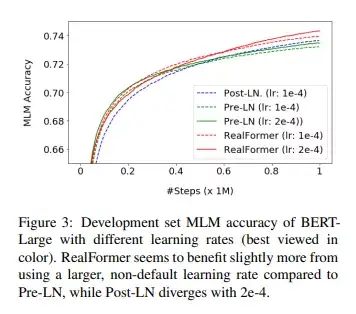
可以看出:一方面,使用更大的学习率,Pre-LN和RealFormer表现都略有提升;另一方面,比起Pre-LN从73.21%提升到73.64%,RealFormer从73.94%提升到74.31%,提升获益更为明显。
3)如何量化RealFormer和基线Transformers的不同?
作者通过量化计算RealFormer结构中每层attention矩阵的交叉熵分布,并与Pre-LN和Post-LN进行了对比,得出结论:1)RealFormer 在所有层中都比另外两个模型方差更小,这就意味着其attention density更加不依赖于输入;2)在RealFormer第9-11层的顶层中的attentions更为稀疏。作者推测正是以上两点不同带来了RealFormer结构的稳定性和更受益于微调训练。
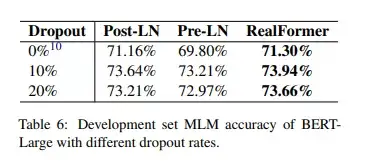
4)为正则化大模型,dropout是否会比RealFormer中的残差式注意力更为有效?
作者实验了在提高dropout率的情况下,三种模型的表现,其结果如下图所示,RealFormer仍然表现优于另外两种结构。但模型表现并不会随着dropout的增加而提升,因此RealFormer的残差结构的正则效果并不能被dropout所取代。
04 实验结果
RealFormer模型在预训练任务和GLUE和SQuAD两个下游任务上的表现都超越了Post-LN和Pre-LN两种模型结构。另外,在下游任务的表现上,RealFormer超越了训练轮数2倍预训练基线模型。通过量化分析,RealFormer无论是相比邻的层之间的attention还是不同头的attention,都更为稀疏。此外,RealFormer相对能从超参调整中更大程度提升模型效果。
参考文献
[1] He R , Ravula A , Kanagal B , et al. RealFormer: Transformer Likes Residual Attention[J]. 2020.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
[4] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509.
[5] Xiong R , Yang Y , He D , et al. On Layer Normalization in the Transformer Architecture[J]. 2020.
[6] He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[7]残差网络解决了什么,为什么有效?
https://zhuanlan.zhihu.com/p/80226180
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
RealFormer: 残差式 Attention 层的Transformer 模型的更多相关文章
- 详解Transformer模型(Atention is all you need)
1 概述 在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention.其实质上就是Encoder中隐层输出的加权和,公式如下: 将Attention机制从Enc ...
- Transformer模型---encoder
一.简介 论文链接:<Attention is all you need> 由google团队在2017年发表于NIPS,Transformer 是一种新的.基于 attention 机制 ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- transformer模型解读
最近在关注谷歌发布关于BERT模型,它是以Transformer的双向编码器表示.顺便回顾了<Attention is all you need>这篇文章主要讲解Transformer编码 ...
- transformer模型简介
Transformer模型由<Attention is All You Need>提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成.论文地 ...
- Transformer模型---decoder
一.结构 1.编码器 Transformer模型---encoder - nxf_rabbit75 - 博客园 2.解码器 (1)第一个子层也是一个多头自注意力multi-head self-atte ...
- Transformer模型总结
Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 它是由编码组件.解码组件和它们之间的连接组成. 编码组件部分由一堆编码器(6个 enco ...
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
随机推荐
- Globally-Robust Neural Networks
目录 概 主要内容 代码 Leino K., Wang Z. and Fredrikson M. Globally-robust neural networks. In International C ...
- Sharpness-Aware Minimization for Efficiently Improving Generalization
目录 概 主要内容 代码 Foret P., Kleiner A., Mobahi H., Neyshabur B. Sharpness-aware minimization for efficien ...
- IT6516替代方案|CS5212替代IT6516|CapstoneCS5212
IT6516/IT6516BFN:是一款DP显示端口转VGA转换器的嵌入式MCU单片机. IT6516/IT6516BFN结合DisplayPort接收器和三重DAC,通过转换功能支持DisplayP ...
- pod存在,但是deployment和statefulset不存在
pod存在,但是deployment和statefulset不存在 这样的话,可以看一下是不是ReplicaSet, kubectl get ReplicaSet -n iot
- MySQL启用SSL连接
1.手动创建自认证证书 1.1 创建CA证书 openssl genrsa 2048 > ca-key.pem openssl req -new -x509 -nodes -days 3600 ...
- ActiveMQ基础教程(一):认识ActiveMQ
ActiveMQ是Apache软件基金会所研发开源的消息中间件,为应用程序提供高效的.可扩展的.稳定的和安全的企业级消息通信. 现在的消息队列有不少,RabbitMQ.Kafka.RocketMQ,Z ...
- CAS学习笔记二:CAS单点登录流程
背景 由于公司项目甲方众多,各甲方为了统一登录用户体系实现单点登录(SSO)开始要求各乙方项目对接其搭建的CAS单点登录服务,有段时间对CAS的流程很迷,各厂商还有基于CAS进行二次开发的情况,所以对 ...
- js 中&&的使用
遇到下列代码goHome && (await router.replace(PageEnum.BASE_HOME)); &&这个逻辑与的作用是,当goHome为true ...
- Nginx_配置文件nginx.conf配置详解
user nginx nginx ; # Nginx用户及组:用户 组.window下不指定 worker_processes 8; # 工作进程:数目.根据硬件调整,通常等于CPU数量或者2倍于CP ...
- vuex获取数据
cmd窗口vue add vuex后出现store文件夹,在里面的index.js里面设置state属性,可以在视图页面home.vue文件中获取. 方法1: //在项目当中引入router以后 就多 ...