ELK-EFK-v7.12.0日志平台部署
ELK和EFK是什么
- ELK和EFK是四个开源产品的组合:
Elasticsearch一个基于Lucene搜索引擎的NoSQL数据库Logstatsh一个日志管道工具,接受数据输入,执行数据转换,然后输出数据Filebeat一个转发和集中日志数据的轻量级传送工具Kibana一个界面层,在Elasticsearch之上工作
关于Elasticsearch
ElasticSearch 重要特性
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
ElasticSearch 基本概念
ElasticSearch与关系性数据库的类比
| RDBMS(MySQL) | Elasticsearch |
|---|---|
| Databases 数据库 | indices 索引 |
| Table 表 | Index(Type) 类型 |
| Row 行 | Doucment 文档 |
| Column 列 | Field 字段 |
| Schema 结构 | Mapping 映射 |
| SQL | DSL |
文档(Document)
- Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位。
文档的存在场景
- 日志文件中的日志项
- 一部电影的具体信息/一张唱片的详细信息
- MP3 播放器里的一首歌/一篇PDF文档中的具体信息
文档的格式
- 文档会被序列化JSON格式,保存在Elasticsearch中
- JSON对象由字段组成
- 每个字段都有对应的字段类型 (字符串/数值/布尔/日期/二进制/范围类型)
文档 ID
- 每个文档都有一个Unique ID
- 你可以自己指定ID
- 或者通过Elasticsearch自动生成
文档的元数据
_ index文档所属的索引名_type文档所属的类型名_id文档唯–Id_source文档的原始Json数据_ all整合所有字段内容到该字段,已被废除_ version文档的版本信息_score相关性打分
索引(Index)
Index - 索引是文档的容器,是一类文档的结合
Index体现了逻辑空间的概念: 每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型Shard体现了物理空间的概念:索引中的数据分散在Shard上
索引的Mapping 与 Settings
Mapping定义文档字段的类型Setting定义不同的数据分布
索引管理
文档,索引是对开发或者使用人员来说的。接下来的概念都是对于运维相关人员的
- 为了高可用性,需要分布式系统的可用和扩展性。随着请求量的提升。数据也不断的提升。
映射(Mapping)
之前的版本中,索引和文档中间还有个类型的概念,每个索引下可以建立多个类型,文档存储时需要指定index和type。
- 从6.0.0开始单个索引中只能有一个类型
- 7.0.0以后将将不建议使用
- 8.0.0 以后完全不支持。
类型用于定义文档属性,包括类型、分词器等。
弃用该概念的原因:
在之前的版本中把Index比作 RDB 的 Database,Type 比作 RDB 的 Table。这种不太恰当,RDB 中,Table 之前相互独立,同名的字段在两个表中毫无关系。但是在ES中,同一个 Index 下不同的 Type 如果有同名的字段,他们会被 Luecence 当作同一个字段 ,并且他们的定义必须相同。所以,实际上之前的说法是不对的。因此 ES 官方将逐渐弃用 Type 的概念,每个Index只能定义一个 Mapping Type。
节点
- 节点是一个Elasticsearch的实例
- 本质上就是一个JAVA进程
- 一台机器可以运行多个Elasticsearch进程,但是生产环境一般建议还是一台机器运行一个Elasticsearch实例。
- 每个节点都有名字,通过配置文件配置,或者启动的时候 -E node.name=node1 指定
- 每个节点在启动之后,会分配一个UID,保存在data目录下。
Master-eligible 节点 和 Master 节点
- 每个节点启动后,默认就是一个Master eligible 节点。
- Master-eligible节点可以参加选主流程,成为Master节点
- 当第一个节点启动的时候,它会将自己选举成Master节点
- 每个节点上都保存了集群的状态,但是只有Master节点才能修改集群的状态信息
- 集群状态(Cluster State),维护了一个集群中,必要的信息。
- 所有的节点信息
- 所有的索引和其相关的Mapping 与 Setting 信息
- 分片的路由信息
- 集群状态(Cluster State),维护了一个集群中,必要的信息。
Data 节点 和 Coordinating 节点
- Data 节点
- 可以保存数据的节点,叫做Data Node。负责保存分片数据,在数据扩展上起到了至关重要的作用。
- Coordinating 节点
- 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇聚到一起。
- 每个节点默认都起到了Coordinating Node 的职责。
其他节点
- Hot & Warm 节点
- 不同硬件配置的Data Node,用来实现 Hot & Warm 结构,降低集群部署的成本。
- Machine Learning Node
- 负责跑机器学习的Job
配置节点的类型
- 开发环境中可以一个节点承担多个角色。
- 生产环境中,应该设置单一的角色的节点(dedicated node)
- 在 配置文件 .yaml 中指定
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 默认节点都为 coordinating 节点 |
| machine learning | node.ml | true (需要enbale x-pack) |
分片(Primary Shard & Replica Shard)
一个索引可以存储大量的数据,甚至超出单个节点的磁盘存储空间。例如一个索引存储了数十亿文档,这些文件占用超过1T的磁盘空间,单台机器无法存储或者由于太多而无法提供搜索服务。
为了解决这个问题,ES 提供了将单个索引分割成多个分片的功能。创建索引时,可以指定任意数量的分片。每个分片都是一个功能齐全且独立的“index”,且可以被托管到集群中的任意节点上。
主分片:用以解决数据水平扩展的问题,通过主分片,可以将数据分布到集群的所有节点之上。- 一个分片是一个运行的 Lucene 的实例
- 主分片在索引创建时指定,后续不允许修改,除非 Reindex
分片有两个重要作用:
- 提供了容量水平扩展的能力;
- 多个分片云允许分布式并发操作,可以大大提高性能;
副本:用以解决数据高可用的问题,副本是主分片的拷贝。- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务可用性(读取的吞吐)
副本有两个重要作用:
- 服务高可用:分片异常时,可以通过副本继续提供服务。因此分片副本不会与主分片分配到同一个节点
- 扩展性能 :由于查询操作可以在分片副本上执行,因此可以提升系统的查询吞吐量
关于Logstash
- Logstash 是一个开源的服务器端
数据处理流水线,它可以同时从多个数据源获取数据,并将其转换为最喜欢的"存储"(Ours is Elasticsearch, naturally.),主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
Logstash 相关术语
Pipeline
- input-filter-output 的三阶段处理流程
- 队列管理
- 插件生命周期管理
logstash 收集日志基本流程: input–>codec–>filter–>codec–>output
input从哪里收集日志。filter发出去前进行过滤output输出至Elasticsearch或Redis消息队列codec输出至前台,方便边实践边测试- 数据量不大日志按照月来进行收集
Logstash Event
- 内部流转的数据表现形式
- 原始数据在input被转换为Event,在output event被转换为目标格式数据
- 在配置文件中可以对Event中的属性进行增删改查
Logstash架构图
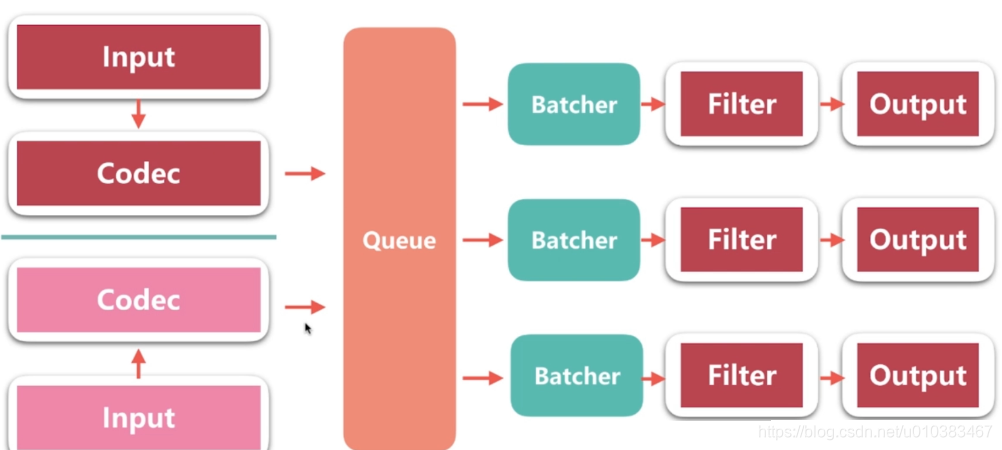
- Batcher 负责批量的从 queue 中取数据
Queue分类
In Memory无法处理进程Crash、机器宕机等情况,会导致数据丢失Persistent Queue In Disk可处理进程Crash等情况,保证数据不丢失,保证数据至少消费一次,充当缓冲区,可以替代kafka等消息队列的作用
持久队列的基本配置
queue.type:persisted默认是memoryqueue.max_bytes:4gb队列存储最大数据量
线程相关配置
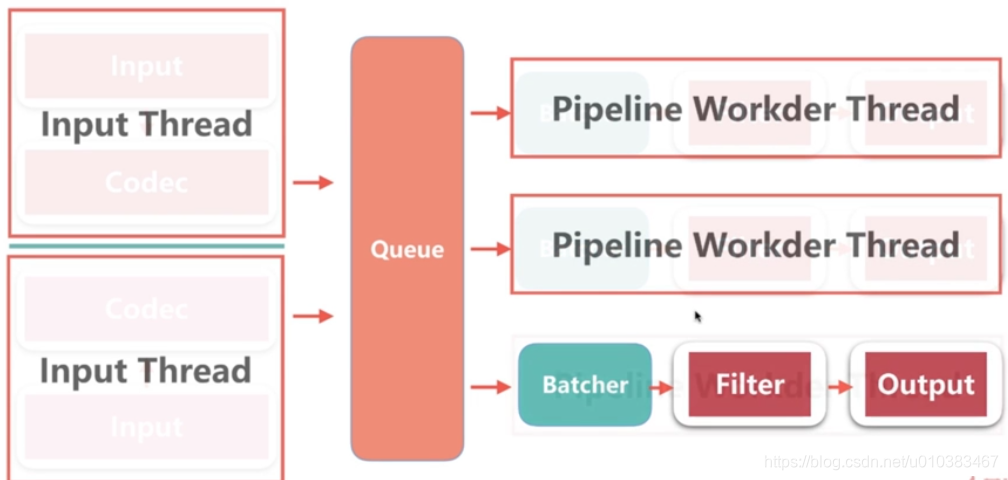
pipeline.worksers | -w
# pipeline线程数,即filter_output的处理线程数,默认是cpu核数
pipeline.batch.size | -b
# Batcher一次批量获取的待处理文档数,默认是125,可以根据输出进行调整,越大会占用越多的 heap 空间,可以通过 jvm.options 调整
pipeline.batch.delay | -u
# Batcher 等待的时长,单位为 ms
Logstash 配置文件
logstash设置相关的配置文件(在conf文件夹中,setting files)
- logstash.yml:logstash相关配置,比如node.name、path.data、pipeline.workers、queue.type等,这其中的配置可以被命令行参数中的相关参数覆盖
- jvm.options:修改jvm的相关参数,比如修改heap size等
pipeline 配置文件:定义数据处理流程的文件,以 .conf 结尾
logstash.yml 配置项
node.name # 节点名称,便于识别
path.data # 持久化存储数据的文件夹,默认是logstash home目录下的data
path.config # 设定pipeline配置文件的目录(如果指定文件夹,会默认把文件夹下的所有.conf文件按照字母顺序拼接为一个文件)
path.log # 设定pipeline日志文件的目录
pipeline.workers # 设定pipeline的线程数(filter+output),优化的常用项
pipeline.batch.size/delay # 设定批量处理数据的数据和延迟
queue.type # 设定队列类型,默认是memory
queue.max_bytes # 队列总容量,默认是1g
logstash 命令行配置项
--node.name
-f --path.config # pipeline路径,可以是文件或者文件夹
--path.settings # logstash配置文件夹路径,其中要包含logstash.yml
-e --config.string # 指明pipeline内容,多用于测试使用
-w --pipeline.workers
-b --pipeline.batch.size
--path.data
--debug
-t --config.test_and_exit
- 建议:线上环境推荐采用配置文件的方式来设定logstash的相关配置,这样可以减少犯错的机会,而且文件便于进行版本化管理;命令行形式多用来进行快速的配置测试、验证、检查等
logstash 多实例运行方式
bin/logstash --path.settings instance1
bin/logstash --path.settings instance2
# 不同instance中修改logstash.yml,自定义path.data,确保其不相同即可
logstash监控运维
- API:Logstash提供了丰富的api来查看Logstash的当前状态
http://192.168.76.101:9600
http://192.168.76.101:9600/_node
http://192.168.76.101:9600/_node/stats
http://192.168.76.101:9600/_node/hot_threads
[root@logstash ~]# curl http://192.168.76.101:9600/_node/stats?pretty
- x-pack
- X-Pack是一个Elastic Stack扩展,将安全性,警报,监控,报告,机器学习和图形功能捆绑到一个易于安装的软件包中。
- 要访问此功能,您必须 在Elasticsearch中安装X-Pack,要安装x-pack必须要和Elasticsearch的版本相匹配,
- 如果您是在现有群集上首次安装X-Pack,则必须执行完整群集重新启动。
- 安装X-Pack后,必须在群集中的所有节点上启用安全性和安全性才能使群集正常运行
关于Filebeat
- Filebeat是Beats中的一员
- Beats:GO开发的,所以高效、很快
- Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
- 目前Beats包含六种工具:
Packetbeat网络数据(收集网络流量数据)Metricbeat指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)Filebeat日志文件(收集文件数据)Winlogbeatwindows事件日志(收集Windows事件日志数据)Auditbeat审计数据(收集审计日志)Heartbeat运行时间监控(收集系统运行时的数据)
Filebeat 和 Logstash
- Logstash 和 Filebeat都具有日志收集功能
- Filebeat 更轻量,占用资源更少
- Logstash 具有filter功能,能过滤分析日志
关于Kibana
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
搭建 Kibana 非常简单。您可以分分钟完成 Kibana 的安装并开始探索 Elasticsearch 的索引数据 — 没有代码、不需要额外的基础设施。
一张图片胜过千万行日志
- Kibana 让您能够自由地选择如何呈现您的数据。或许您一开始并不知道自己想要什么。不过借助Kibana 的交互式可视化,您可以先从一个问题出发,看看能够从中发现些什么。
从基础入手
- Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、环形图,等等。它们充分利用了Elasticsearch 的聚合功能。
将地理数据融入任何地图
- 利用我们的 Elastic Maps Services 来实现地理空间数据的可视化,或者发挥创意,在您自己的地图上实现自定义位置数据的可视化。
时间序列也在菜单之列
- 您可以利用 Timelion,对您 Elasticsearch 中的数据执行高级时间序列分析。您可以利用功能强大、简单易学的表达式来描述查询、转换和可视化。
利用 graph 功能探索关系
- 凭借搜索引擎的相关性功能,结合 graph 探索,揭示您 Elasticsearch 数据中极其常见的关系。
ELK架构
ELK栈中的各个组件之间相互协作,不需要太多额外的配置,当然对于不同使用场景,架构也会有区别。
对于小型开发环境,通常架构如下:
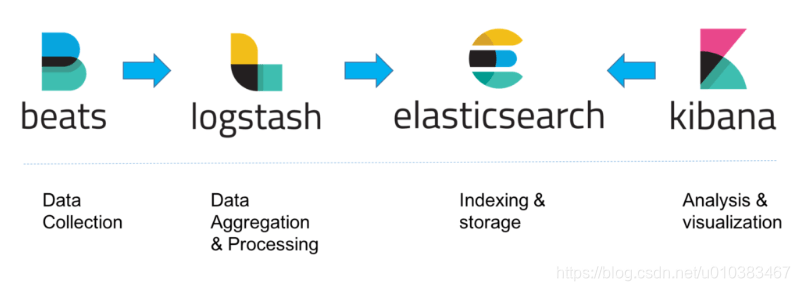
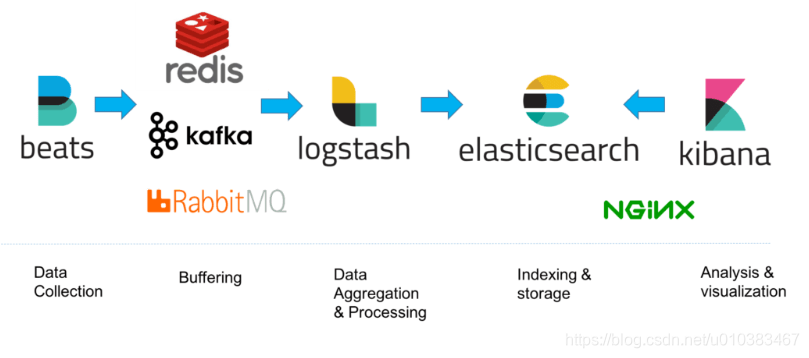
- 对于有大量数据的生产环境,可能会在日志体系结构中添加其他部分,例如:提高弹性(添加Kafka、RabbitMQ、Redis)和安全性(添加nginx):
集群部署
| IP | HOSTNAME | SERVICE | VERSION |
|---|---|---|---|
| 192.168.72.5 | kibana | Kibana | 7.12.0 |
| 192.168.72.60 | es-01 | Elasticsearch | 7.12.0 |
| 192.168.72.61 | es-02 | Elasticsearch | 7.12.0 |
| 192.168.72.62 | es-03 | Elasticsearch | 7.12.0 |
| 192.168.72.63 | logstash | Logstash | 7.12.0 |
| 192.168.72.64 | filebeat | Filebeat | 7.12.0 |
注:
Elasticsearch、Logstash、Kibana都是依赖JDK环境的,建议机器内存不要低于2G(2G已经有点憋屈了),否则服务会启动不了(建议不要低于3G)
ELK 7.x系列依赖JAVA 13版本的,7.x系列之前的,可以使用JAVA 8版本的,不过JAVA 8之后的版本不属于开源了,如果是企业部署,一定要注意,避免带来了律师函,当然,如果是个人学习,那就随便造(因为个人不值钱)
ELK 7.12.0和JAVA 13都可以从各自的官网下载,但是官网的速度比较慢,我上传了一份到百度云,
仅供个人学习使用,切勿用于商业场景,因此带来的法律责任,与本人无关!!!
环境准备
本次部署用到的tar包,我都上传到百度云了,es官网下载速度实在太慢了,如果担心包的安全问题,也可以自行去官网下载(毕竟百度网盘没有会员,可能比官网还慢)
链接:https://pan.baidu.com/s/1oNIEblyIyTdOGdlqj-ndJQ
提取码:okv9
注意: 确保 IP 地址为静态地址
所有节点修改主机名
# hostnamectl set-hostname kibana
# hostnamectl set-hostname es-01
# hostnamectl set-hostname es-02
# hostnamectl set-hostname es-03
# hostnamectl set-hostname logstash
# hostnamectl set-hostname filebeat
所有节点修改hosts文件
# cat >> /etc/hosts <<-EOF
192.168.72.5 kibana
192.168.72.60 es-01
192.168.72.61 es-02
192.168.72.62 es-03
192.168.72.63 logstash
192.168.72.64 filebeat
EOF
所有节点关闭防火墙、selinux
关闭防火墙
# systemctl disable firewalld.service --now
关闭selinux
# sed -i "s/SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
# setenforce 0
所有节点时间同步
切记,部署集群一类的服务,一定要做时间同步的操作
时间同步服务器有ntp和chrony两种,这里使用的是chrony
# yum -y install chrony
# vim /etc/chrony.conf # 编辑配置文件
server4 time1.aliyun.com iburst # 配置时间服务器地址
# systemctl restart chronyd.service # 重启进程
# systemctl enable chronyd.service # 开机自启
# chronyc sources -v # 查看时间信息
安装JAVA 13
Elasticsearch、Logstash、Kibana所在节点均需要安装JAVA环境
JAVA环境需要提前下载,并上传至服务器
Elasticsearch的tar包自带JDK环境(解压后,在jdk目录下,7.12.0自带的jdk是15版本的,但是是openjdk,关于是选择甲骨文的jdk,还是openjdk,就需要根据自己的情况去选择了)
使用低于11版本的java,启动Elasticsearch会出现下面的报错
ES官方推荐使用
ES_JAVA_HOME来定义JAVA的路径,如果需要使用Elasticsearch自带的JAVA,本地不要设置JAVA_HOME这个变量
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME
Future versions of Elasticsearch will require Java 11; your Java version from [/usr/local/jdk1.8.0_211/jre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
# cd /usr/local/src/
# tar xvf jdk-13.0.2_linux-x64_bin.tar.gz -C /usr/local/
# cat >> /etc/profile.d/java13.sh <<EOF
export JAVA_HOME=/usr/local/jdk-13.0.2
export PATH=\$JAVA_HOME/bin:\$PATH
EOF
# source /etc/profile.d/java13.sh
# java -version
java version "13.0.2" 2020-01-14
Java(TM) SE Runtime Environment (build 13.0.2+8)
Java HotSpot(TM) 64-Bit Server VM (build 13.0.2+8, mixed mode, sharing)
修改文件限制
Elasticsearch、Logstash、Kibana所在节点均需要操作
# cat >> /etc/security/limits.conf <<-EOF
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
elk soft memlock unlimited
elk hard memlock unlimited
EOF
soft xxx代表警告的设定,可以超过这个设定值,但是超过后会有警告。
hard xxx代表严格的设定,不允许超过这个设定的值。
soft nproc单个用户可用的最大进程数量(超过会警告)hard nproc单个用户可用的最大进程数量(超过会报错)soft nofile可打开的文件描述符的最大数(超过会警告)hard nofile可打开的文件描述符的最大数(超过会报错)
# cat >> /etc/systemd/system.conf<<-EOF
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
EOF
调整虚拟内存&最大并发连接
Elasticsearch、Logstash、Kibana所在节点均需要操作
# cat >>/etc/sysctl.conf<<-EOF
vm.max_map_count=655360
fs.file-max=655360
vm.swappiness=0
EOF
# sysctl -p
- max_map_count 文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
- fs.file-max:决定了系统级别所有进程可以打开的文件描述符的数量限制。
- swappiness的值的大小对如何使用swap分区是有着很大的联系的。swappiness=0的时候表示最大限度使用物理内存,然后才是 swap空间,swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。linux的基本默认设置为60
给 ELK 用户添加免密 sudo
Elasticsearch、Logstash、Kibana所在节点均需要操作
Elasticsearch、Logstash、Kibana都需要使用普通用户部署和启动,root用户会报错(需要–allow-root参数),用户名可以自己定义
Fliebeat可以直接使用root用户,不需要普通用户
# useradd elk
# visudo # 添加以下内容
elk ALL=(ALL) NOPASSWD: ALL
部署Elasticsearch集群
以下操作,都需要使用
elk用户进行
# su - elk
下载Elasticsearch的tar包
$ cd /usr/local/src/
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz
$ tar xvf elasticsearch-7.12.0-linux-x86_64.tar.gz -C /home/elk/
Elasticsearch配置文件说明
cluster.name: my-application
# 配置的集群名称,默认是my-application,es服务会通过广播方式自动连接在同一网段下的es服务,通过多播方式进行通信,同一网段下可以有多个集群,通过集群名称这个属性来区分不同的集群。
node.name: "node-1"
# 当前配置所在机器的节点名,你不设置就默认随机指定一个name列表中名字,该name列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。
node.attr.rack: r1
# 向节点添加自定义属性
node.max_local_storage_nodes: 3
# 这个配置限制了单节点上可以开启的ES存储实例的个数,我们需要开多个实例,因此需要把这个配置写到配置文件中,并为这个配置赋值为2或者更高
node.master: true
# 指定该节点是否有资格被选举成为node(注意这里只是设置成有资格, 不代表该node一定就是master),默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
node.data: true
# 指定该节点是否存储索引数据,默认为true。
index.number_of_shards: 5
# 设置默认索引分片个数,默认为5片。
index.number_of_replicas: 1
# 设置默认索引副本个数,默认为1个副本。如果采用默认设置,而你集群只配置了一台机器,那么集群的健康度为yellow,也就是所有的数据都是可用的,但是某些复制没有被分配
# (健康度可用 curl 'localhost:9200/_cat/health?v' 查看, 分为绿色、黄色或红色。绿色代表一切正常,集群功能齐全,黄色意味着所有的数据都是可用的,但是某些复制没有被分配,红色则代表因为某些原因,某些数据不可用)。
path.conf: /path/to/conf
# 设置配置文件的存储路径,默认是es根目录下的config文件夹。
path.data: /path/to/data
# 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:
# path.data: /path/to/data1,/path/to/data2
path.work: /path/to/work
# 设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.logs: /path/to/logs
# 设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: /path/to/plugins
# 设置插件的存放路径,默认是es根目录下的plugins文件夹, 插件在es里面普遍使用,用来增强原系统核心功能。
bootstrap.memory_lock: true
# 设置为true来锁住内存不进行swapping。因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内# # 存,linux下启动es之前可以通过`ulimit -l unlimited`命令设置。
network.host: 192.168.0.1
# 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,绑定这台机器的任何一个ip。
# 其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址
transport.tcp.port: 9300
# 设置节点之间交互的tcp端口,默认是9300。
transport.tcp.compress: true
# 设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.port: 9200
# 设置对外服务的http端口,默认为9200。
http.enabled: false
# 是否使用http协议对外提供服务,默认为true,开启。
gateway.recover_after_nodes: 1
# 设置集群中N个节点启动时进行数据恢复,默认为1。
gateway.recover_after_time: 5m
# 设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.expected_nodes: 2
# 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
cluster.routing.allocation.node_initial_primaries_recoveries: 4
# 初始化数据恢复时,并发恢复线程的个数,默认为4。
cluster.routing.allocation.node_concurrent_recoveries: 2
# 添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
indices.recovery.max_size_per_sec: 0
# 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
indices.recovery.concurrent_streams: 5
# 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
discovery.zen.minimum_master_nodes: 1
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.ping.timeout: 3s
# 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.multicast.enabled: false
# 设置是否打开多播发现节点,默认是true。
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
# 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
# head 插件需要这打开这两个配置
# 是否开启跨域访问
http.cors.enabled: true
# 开启跨域访问后的地址限制,*表示无限制
http.cors.allow-origin: "*"
# 开启 xpack 功能,如果要禁止使用密码,请将以下内容注释,直接启动不需要设置密码
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
配置Elasticsearch.yml
$ cd /home/elk/elasticsearch-7.12.0/config/
$ cp elasticsearch.yml{,-$(date +%F-%R)} # 配置文件一定要先备份一份,免得修改的时候有问题,还能还原
Elasticsearch节点分别修改配置文件
$ cat > elasticsearch.yml <<EOF
cluster.name: myes-test
node.name: es-01
node.master: true
node.data: true
bootstrap.memory_lock: true
network.host: 192.168.72.60
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["192.168.72.60", "192.168.72.61","192.168.72.62"]
discovery.zen.minimum_master_nodes: 2
cluster.initial_master_nodes: ["es-01"]
EOF
$ cat > elasticsearch.yml <<EOF
cluster.name: myes-test
node.name: es-02
node.master: true
node.data: true
bootstrap.memory_lock: true
network.host: 192.168.72.61
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["192.168.72.60", "192.168.72.61","192.168.72.62"]
discovery.zen.minimum_master_nodes: 2
cluster.initial_master_nodes: ["es-01"]
EOF
$ cat > elasticsearch.yml <<EOF
cluster.name: myes-test
node.name: es-03
node.master: true
node.data: true
bootstrap.memory_lock: true
network.host: 192.168.72.62
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["192.168.72.60", "192.168.72.61","192.168.72.62"]
discovery.zen.minimum_master_nodes: 2
cluster.initial_master_nodes: ["es-01"]
EOF
node.name三个节点的名称不能一样
network.host写三个节点的本机IP就可以了
关于jvm.options
- 默认情况下,Elasticsearch的JVM使用堆大小为2GB
- Elasticsearch 在 jvm.options 中指定了Xms(最小)和Xmx(最大)的堆的设置。所设置的值取决于你的服务器的可用内存大小。好的规则应满足:
- 最小堆的大小和最大堆的大小应该相等。
- Elasticsearch可获得越多的堆,并且内存也可以使用更多的缓存。但是需要注意,分配了太多的堆给你的项目,将会导致有长时间的垃圾搜集停留。
- 设置最大堆的值不能超过你物理内存的50%,要确保有足够多的物理内存来保证内核文件缓存。
- 不要将最大堆设置高于JVM用于压缩对象指针的截止值。确切的截止值是有变化,但接近32gb。
- 最好尝试保持在基于零压缩oops的阈值以下;当确切的截止值在大多数时候处于26GB是安全的。但是在大多数系统中也可以等于30GB。
配置systemctl管理
Elasticsearch节点都需要操作
$ sudo vim /etc/systemd/system/elasticsearch.service
[Unit]
Description=elasticsearch
[Service]
User=elk
Group=elk
LimitMEMLOCK=infinity
LimitNOFILE=100000
LimitNPROC=100000
ExecStart=/home/elk/elasticsearch-7.12.0/bin/elasticsearch
[Install]
WantedBy=multi-user.target
如果使用的用户不是elk,注意修改
User和Group两个字段的用户名称如果安装的路径和我的不一样,切记修改
ExecStart字段的路径
启动Elasticsearch集群
$ sudo systemctl daemon-reload
$ sudo systemctl enable elasticsearch.service --now
我的虚拟机给的4G内存,由此可见2G内存是真的很憋屈
es-01:~ # free -h
total used free shared buff/cache available
Mem: 3.8G 1.5G 123M 11M 2.2G 1.8G
Swap: 3.9G 0B 3.9G
验证Elasticsearch集群
java程序可以使用jps查看进程
$ jps
27152 Elasticsearch
32556 Jps
检查端口是否起来了
$ ss -nltp | egrep "9200|9300"
LISTEN 0 128 [::ffff:192.168.72.61]:9200 [::]:* users:(("java",pid=31038,fd=335))
LISTEN 0 128 [::ffff:192.168.72.61]:9300 [::]:* users:(("java",pid=31038,fd=281))
查看集群节点信息
es-01:~ $ curl -XGET "http://192.168.72.60:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.72.62 27 97 8 0.35 0.23 0.13 cdfhilmrstw - es-03
192.168.72.61 43 97 9 0.18 0.14 0.09 cdfhilmrstw - es-02
192.168.72.60 36 97 9 0.17 0.25 0.20 cdfhilmrstw * es-01
查看集群健康信息
$ curl -XGET "http://192.168.72.60:9200/_cluster/health?pretty"
{
"cluster_name" : "myes-test", # 配置文件中定义的集群名称
"status" : "green", # 集群的状态红绿灯,绿:健康,黄:亚健康,红:病态
"timed_out" : false,
"number_of_nodes" : 3, # 节点数量
"number_of_data_nodes" : 3, # 数据节点数量
"active_primary_shards" : 0, # 主分片数量
"active_shards" : 0, # 可用的分片数量
"relocating_shards" : 0, # 正在重新分配的分片数量,在新加或者减少节点的时候会发生
"initializing_shards" : 0, # 正在初始化的分片数量,新建索引或者刚启动会存在,时间很短
"unassigned_shards" : 0, # 没有分配的分片,一般就是那些名存实不存的副本分片。
"delayed_unassigned_shards" : 0, # 延迟未分配的分片数量
"number_of_pending_tasks" : 0, # 等待执行任务数量
"number_of_in_flight_fetch" : 0, # 正在执行的数量
"task_max_waiting_in_queue_millis" : 0, # 任务在队列中等待的较大时间(毫秒)
"active_shards_percent_as_number" : 100.0 # 任务在队列中等待的较大时间(毫秒)
}
- Elasticsearch 集群健康状态分为三种
green最健康得状态,说明所有的分片包括备份都可用; 这种情况Elasticsearch集群所有的主分片和副本分片都已分配, Elasticsearch集群是 100% 可用的。yellow基本的分片可用,但是备份不可用(或者是没有备份); 这种情况Elasticsearch集群所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。red部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好; 这种情况Elasticsearch集群至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
curl 查看ES集群支持的选项
$ curl -XGET 'http://192.168.72.60:9200/_cat'
/_cat/allocation 查看磁盘的分配情况
/_cat/shards 查看节点包含哪些分片的详细视图
/_cat/shards/{index} 查看指定索引节点包含哪些分片的详细视图
/_cat/master 返回关于主节点的相关信息
/_cat/nodes 查看集群的节点情况
/_cat/tasks 查看es集群内部任务执行的情况
/_cat/indices 查看集群的索引健康状态
/_cat/indices/{index} 查看集群的索引健康状态(指定索引)
/_cat/segments 查询集群中Lucene数据段的信息,segment是ES中一个数据段,每次refresh都会生成一个新的segmen。elasticsearch有一个后台进程专门负责segment的合并,它会把小segments合并成更大的segments,然后反复这样
/_cat/segments/{index} 查询集群中Lucene数据段的信息(指定索引)
/_cat/count 返回集群中文档的计数
/_cat/count/{index} 返回指定索引的文档计数
/_cat/recovery 查看索引回复的情况
/_cat/recovery/{index} 查看指定索引回复的情况
/_cat/health 查看集群健康状态
/_cat/pending_tasks 查询集群中被挂起的任务
/_cat/aliases 查看集群别名列表
/_cat/aliases/{alias} 查看指定索引的别名情况
/_cat/thread_pool 查询es内部线程池的情况
/_cat/thread_pool/{thread_pools} 查询es内部线程池中指定线程的情况
/_cat/plugins 查询es插件列表
/_cat/fielddata 查询集群中每个节点中的fileddata所使用的堆内存
/_cat/fielddata/{fields} 查询集群中每个节点中的fields所使用的堆内存
/_cat/nodeattrs 查看集群节点的属性值
/_cat/repositories 查看集群的快照存储库
/_cat/snapshots/{repository} 返回有关存储在一个或多个存储库中的快照的信息
/_cat/templates 集群中索引模板的信息
部署Logstash
Logstash也需要进入到elk用户操作
# su - elk
下载Logstash的tar包
$ cd /usr/local/src/
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.0-linux-x86_64.tar.gz
$ tar xvf logstash-7.12.0-linux-x86_64.tar.gz -C /home/elk/
配置logstash.yml
# 节点名称,便于识别
node.name: test
# 持久化存储数据的文件夹,默认是logstash home目录下的data
path.data: /logstash/data
# 设定pipeline配置文件的目录(如果指定文件夹,会默认把文件夹下的所有.conf文件按照字母顺序拼接为一个文件)
path.config: /logstash/conf
# 设定pipeline日志文件的目录
path.log: /logstash/logs
# 设定pipeline的线程数(filter+output),优化的常用项
pipeline.workers: 2
# 设定批量处理数据的数据和延迟
pipeline.batch.size: 125
pipeline.batch.delay: 50
# 设定队列类型,默认是memory
queue.type: persisted
# #队列存储路径;如果队列类型为persisted,则生效
path.queue: /logstash/data/queue
# 队列为持久化,单个队列大小
queue.page_capacity: 64mb
# 当启用持久化队列时,队列中未读事件的最大数量,0为不限制
queue.max_events: 0
# 队列最大容量
queue.max_bytes: 1024mb
#在启用持久队列时强制执行检查点的最大数量,0为不限制
queue.checkpoint.acks: 1024
# 在启用持久队列时强制执行检查点之前的最大数量的写入事件,0为不限制
queue.checkpoint.writes: 1024
#当启用持久队列时,在头页面上强制一个检查点的时间间隔
queue.checkpoint.interval: 1000
还有许多配置,可以查看官方文档
由于我全部使用默认的,因此就不修改配置文件了
配置输入输出
$ cd /home/elk/logstash-7.12.0/config/
$ vim demo-test.conf
input {
file {
path => ["/home/elk/test.log"]
}
}
output {
stdout {
codec => "json"
}
}
配置 pipelines.yml
$ cp pipelines.yml{,-$(date +%F-%R)}
$ vim pipelines.yml
- pipeline.id: id1
pipeline.workers: 1
path.config: "/home/elk/logstash-7.12.0/config/demo-test.conf"
配置systemctl管理
$ sudo vim /etc/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
User=elk
Group=elk
LimitMEMLOCK=infinity
LimitNOFILE=100000
LimitNPROC=100000
ExecStart=/home/elk/logstash-7.12.0/bin/logstash
[Install]
WantedBy=multi-user.target
如果使用的用户不是elk,注意修改
User和Group两个字段的用户名称如果安装的路径和我的不一样,切记修改
ExecStart字段的路径
启动Logstash
$ sudo systemctl daemon-reload
$ sudo systemctl enable logstash.service --now
验证Logstash
java程序可以使用jps查看进程
$ jps
33813 Logstash
34693 Jps
检查端口是否起来了
logstash:~/logstash-7.12.0 $ ss -nltp | grep 9600
LISTEN 0 50 [::ffff:127.0.0.1]:9600 [::]:* users:(("java",pid=33813,fd=79))
查看内存使用情况,Logstash也是使用的4G内存,再不处理日志的情况下,也勉强要用到3G
$ free -h
total used free shared buff/cache available
Mem: 3.8G 762M 1.3G 11M 1.8G 2.8G
Swap: 3.9G 0B 3.9G
关于Logstash的使用,可以查看这位大佬的博客:Logstash组件详解(input、codec、filter、output)
部署Filebeat
下载Fliebeat的tar包
# cd /usr/local/src/
# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.12.0-linux-x86_64.tar.gz
# tar xvf filebeat-7.12.0-linux-x86_64.tar.gz -C /usr/local/
关于filebeat.yml
Filebeat的配置非常的灵活,需要以自身的需求进行配置,相关的配置可以查看官方文档,配置完成后再启动服务即可
配置systemctl管理
# cat > /etc/systemd/system/filebeat.service <<EOF
[Unit]
Description=filebeat server daemon
Documentation=/usr/local/filebeat/filebeat -help
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Environment="BEAT_CONFIG_OPTS=-c /usr/local/filebeat-7.12.0-linux-x86_64/filebeat.yml"
ExecStart=/usr/local/filebeat-7.12.0-linux-x86_64/filebeat \$BEAT_CONFIG_OPTS
Restart=always
[Install]
WantedBy=multi-user.target
EOF
启动Filebeat
# systemctl daemon-reload
# systemctl enable filebeat.service --now
部署Kibane
Kibana也需要进入到elk用户操作
# su - elk
下载Kibana的tar包
$ cd /usr/local/src/
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.0-linux-x86_64.tar.gz
$ tar xvf kibana-7.12.0-linux-x86_64.tar.gz -C /home/elk/
关于kibana.yml
kibana的参数也有很多,一些自定义的需求,可以查看官方文档
配置kibana.yml
$ cd /home/elk/kibana-7.12.0-linux-x86_64/config/
$ cp kibana.yml{,-$(date +%F-%R)}
$ vim kibana.yml
server.host: "192.168.72.5"
elasticsearch.hosts: ["http://192.168.72.60:9200"]
i18n.locale: "zh-CN"
server.hostKibana所在节点的IP
elasticsearch.hosts对接的es集群的IP
i18n.localeKibana页面显示的默认语言
server.port自定义Kibana端口,默认为5601,可以不配置
配置systemctl管理
$ sudo vim /etc/systemd/system/kibana.service
[Unit]
Description=kibana
[Service]
User=elk
Group=elk
LimitMEMLOCK=infinity
LimitNOFILE=100000
LimitNPROC=100000
ExecStart=/home/elk/kibana-7.12.0-linux-x86_64/bin/kibana
[Install]
WantedBy=multi-user.target
启动Kibana
$ sudo systemctl daemon-reload
$ sudo systemctl enable kibana.service --now
验证Kibana
检查端口是否起来了
$ ss -nltp | grep 5601
LISTEN 0 128 192.168.72.5:5601 *:* users:(("node",pid=111993,fd=40))
ibana/current/settings.html
配置kibana.yml
$ cd /home/elk/kibana-7.12.0-linux-x86_64/config/
$ cp kibana.yml{,-$(date +%F-%R)}
$ vim kibana.yml
server.host: "192.168.72.5"
elasticsearch.hosts: ["http://192.168.72.60:9200"]
i18n.locale: "zh-CN"
server.hostKibana所在节点的IP
elasticsearch.hosts对接的es集群的IP
i18n.localeKibana页面显示的默认语言
server.port自定义Kibana端口,默认为5601,可以不配置
配置systemctl管理
$ sudo vim /etc/systemd/system/kibana.service
[Unit]
Description=kibana
[Service]
User=elk
Group=elk
LimitMEMLOCK=infinity
LimitNOFILE=100000
LimitNPROC=100000
ExecStart=/home/elk/kibana-7.12.0-linux-x86_64/bin/kibana
[Install]
WantedBy=multi-user.target
启动Kibana
$ sudo systemctl daemon-reload
$ sudo systemctl enable kibana.service --now
验证Kibana
检查端口是否起来了
$ ss -nltp | grep 5601
LISTEN 0 128 192.168.72.5:5601 *:* users:(("node",pid=111993,fd=40))
打开浏览器,访问192.168.72.5:5601,就可以访问到Kibana的页面了
Kibana也带有了一些数据,可以选择添加数据,也可以自己使用es手动插入索引来验证最终的展示效果
ELK-EFK-v7.12.0日志平台部署的更多相关文章
- Kubernetes-v1.12.0基于kubeadm部署
1.主机规划 #master节点(etcd/apiserver/scheduler/controller manager)master.example.cometh0: 192.168.0.135et ...
- 通过ELK快速搭建集中化日志平台
ELK就是ElasticSearch + LogStash + Kibana 1.准备工作 ELK下载:https://www.elastic.co/downloads/ jdk version:1. ...
- 亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统.日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」 废话不多说,老司机们座好了, ...
- elk实时日志分析平台部署搭建详细实现过程
原文:http://blog.csdn.net/mchdba/article/details/52132663 1.ELK平台介绍 在搜索ELK资料的时候,发现这篇文章比较好,于是摘抄一小段:以下内容 ...
- ELK6.0部署:Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 1.ELK简介 ELK是Elasticsearch+Logstash+Kibana的简称 ElasticSearch是一个基于Lucene的分布式全文搜索引擎,提供 RESTful API进 ...
- ELK Stack企业日志平台文档
ELK Stack企业日志平台文档 实验环境 主机名 IP地址 配置 系统版本 用途 controlno ...
- Springboot项目搭配ELK日志平台
上一篇讲过了elasticsearch和kibana的可视化组合查询,这一篇就来看看大名鼎鼎的ELK日志平台是如何搞定的. elasticsearch负责数据的存储和检索,kibana提供图形界面便于 ...
- Centos7.5搭建ELK-6.5.0日志分析平台
Centos7.5搭建ELK-6.5.0日志分析平台 1. 简介 工作工程中,不论是开发还是运维,都会遇到各种各样的日志,主要包括系统日志.应用程序日志和安全日志,对于开发人员来说,查看日志,可以实时 ...
- 基于Kafka+ELK搭建海量日志平台
早在传统的单体应用时代,查看日志大都通过SSH客户端登服务器去看,使用较多的命令就是 less 或者 tail.如果服务部署了好几台,就要分别登录到这几台机器上看,等到了分布式和微服务架构流行时代,一 ...
随机推荐
- live-server使用指南
一.安装 npm -g install live-server 二.配置 --port=NUMBER` - 选择要使用的端口,默认值:PORT env var或8080--host=ADDRESS` ...
- SYCOJ570传纸条
题目-传纸条 (shiyancang.cn) 算法(线性DP) O(n3)O(n3)首先考虑路径有交集该如何处理.可以发现交集中的格子一定在每条路径的相同步数处.因此可以让两个人同时从起点出发,每次同 ...
- 《剑指offer》面试题59 - I. 滑动窗口的最大值
问题描述 给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值. 示例: 输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3 输出: [3,3,5,5 ...
- Scratch 3 矢量编辑器——“临摹”一只哆啦A梦
利用Scratch来制作一些小作品,常常需要到网上去找图片,而网上下载的图片一般都是位图,往往存在两个问题: 图片不够清晰,当图片放大后会出现"马赛克"现象: 图片中存在不必要的背 ...
- C# winform Visual Studio Installer打包教程,安装包
//具体打包过程,参考下面网址 https://www.cnblogs.com/dongh/p/6868638.html VS 扩展和更新-联机 搜索 Microsoft Visual Studio ...
- entity framework无法写入数据库.SaveChanges()失败
参考https://stackoverflow.com/questions/26745184/ef-cant-savechanges-to-db/28256645 https://www.codepr ...
- golang中GPM模型原理与调度器设计策略
一.GMP模型原理first: 1. 全局队列:存放待运行的G2. P的本地队列:同全局队列类似,存放待运行的G,存储的数量有限:256个,当创建新的G'时,G'优先加入到P的本地队列,如果队列已满, ...
- 数据库备份还原 mysqldump
1.备份全部数据库的数据和结构mysqldump -uroot -p123456 --all-databases >all.bakmysqldump -uroot -p123456 -A > ...
- Java语法专题1: 类的构造顺序
合集目录 Java语法专题1: 类的构造顺序 问题 下面的第二个问题来源于Oracle的笔试题, 非常经典的一个问题, 我从07年开始用了十几年. 看似简单, 做对的比例不到2/10. 描述一下多级继 ...
- plsql 视图中 为什么使用替代触发器
/* 什么是视图? 视图:数据库对象,存的是一个查询命令:当作一个虚拟的数据表来使用: 应用场景: 简化查询操作:不能直接在视图上进行create,insert,update操作: 创建视图? 需要管 ...