Flink(二)【架构原理,组件,提交流程】
一.运行架构
1.架构
基于yarn模式
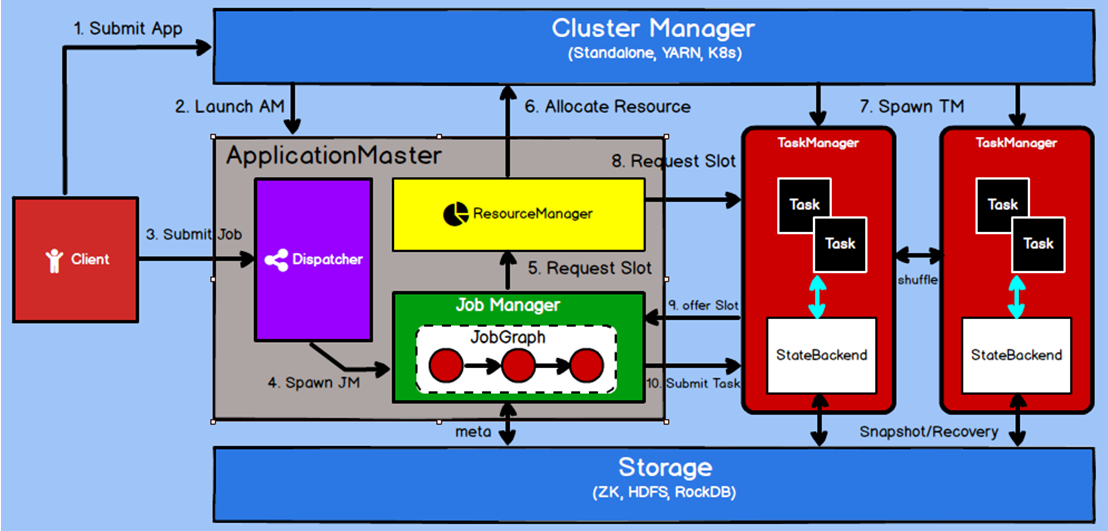
0) Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
1) 向Yarn ResourceManager提交任务,
2) ResourceManager分配Container资源,Yarn通知NodeManager启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境,然后启动JobManager
3) Client提交Job给Dispatcher
4) Dispatcher将JobGraph转发给JobManager
5) JobManager向Flink ResourceManager申请资源启动
6) Flink ResourceManager向Yarn申请资源TaskManager
7) Yarn ResourceManager分配Container资源。
8) Flink ResourceManager向通知资源所在的NodeMananger启动TaskManager
9) NodeManager加载Flink的jar和配置环境启动TaskManager,反向JobManager发送心跳包,等待任务
10) JobManager将执行的任务发送给TaskManager执行。
2.组件
Application Master 部分包含了三个组件:
1) Dispatcher
负责接收用户提供的作业,并且负责为这个新提交的作业启动一个新的 JobManager 组件
2) ResourceManager
负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager
3) JobManager
负责管理作业的执行,在一个 Flink 集群中可能有多个作业同时执行,每个作业 都有自己的 JobManager 组件
还有其他组件:
1) TaskManager
主要负责执行具体的task任务,从JobManager处接收需要部署的 Task,部署 启 动后,与自己的上游建立连接,接收数据并处理。
2) Cluster Manager
集群管理器,比如Standalone、YARN、K8s等。
3) Client
提交Job的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交Job后,Client可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
二.核心概念
TaskManager 、 Slots
Taskmanager 类比 Spark 的Excutor
1个Taskmanager,1个JVM进程,运行多个线程Task,Task的个数等于Slot的个数。类似Spark的Excutor。
Slot 类比 Spark的Core
相同点
1个Slot启动1个线程,Slot的个数决定最大并行的Task数
不同点
①Slot多个Job共享,当空闲时其他Job可以使用(Yarn Session-Cluster模式);
Core只能当前Job内部使用,其他Job无法使用
②TaskManager的内存均分给Slot,意味Slot是内存空间,不是Spark的Core。
Parallelism(并行度)
正在执行的task数,就是当前的并行度
- 设置并行度
Spark:调用特殊算子(repartition)或者Shuffle。
Flink:可以直接给算子设置并行度,或者全局设置
注意:某些数据源数据的采集是无法改变并行度,如Socket
某个算子并行度2那么这个算子对应得task会拆分成2个subtask,一个特定算子的subtask的个数被称之为其并行度(parallelism),一般情况下,一个流程序的并行度是其所有算子中最大的并行度。
Task 、Subtask
- Task
可以理解为Spark的一个Stage中的并行度将不同算子的subtask组成的1个任务链,作为1个task执行
- Subtask
可以理解为1个算子有2个并行度,那么这个算子所在的Task就会拆分成两个SubTask。
Operator Chains(任务链)
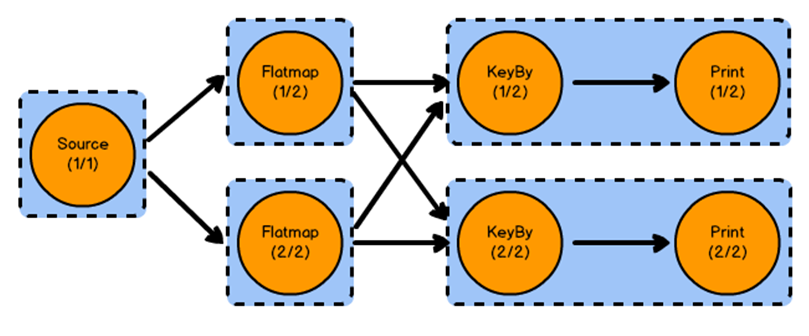
可以理解为Spark中的一个Stage的同一分区的多个转换算子在1个task运行。
任务链形成条件:one-to-one的数据传输并且并行度相同
ExecutionGraph(执行图)任务生成过程
①client生成Sream Graph(数据流图)
②client 根据Sream Graph(数据流图)满足one to one 就转换成操作链,转换为 JobGraph(任务图)
③client将JobGraph(任务图)提交给JobManager,JobManager根据JobGraph(任务图)生成ExecutionGraph(执行图),然后展开并行度,转换为物理执行图,提交给TaskManager运行。
提交流程
通用的提交流程
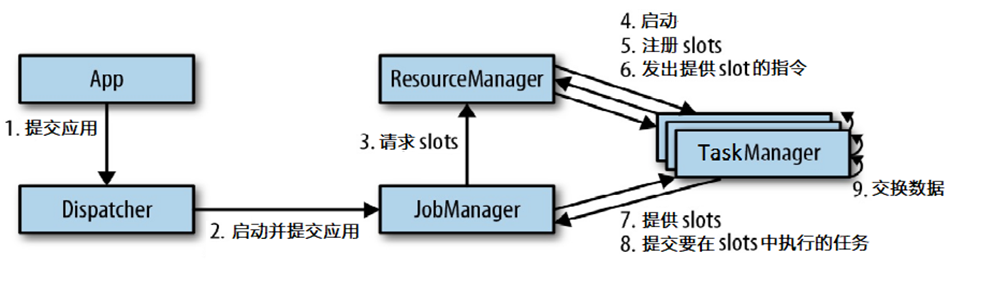
基于yarn的提交流程
Flink(二)【架构原理,组件,提交流程】的更多相关文章
- Spark运行架构及作业提交流程
1.yarn-cluster模式: (1)client客户端提交spark Application应用程序到yarn集群. (2)ResourceManager收到了请求后,在集群中选择一个NodeM ...
- Flink提交流程和架构
一.Flink提交任务的流程 Flink任务提交后,Client向HDFS上传Flink的jar包和配置,之后向Yarn ResourceManager提交任务,ResourceManager分配Co ...
- 小记---------spark架构原理&主要组件和进程
spark的主要组件和进程 driver (进程): 我们编写的spark程序就在driver上,由driver进程执行 master(进程): 主要负责资源的 ...
- Mybatis架构原理(二)-二级缓存源码剖析
Mybatis架构原理(二)-二级缓存源码剖析 二级缓存构建在一级缓存之上,在收到查询请求时,Mybatis首先会查询二级缓存,若二级缓存没有命中,再去查询一级缓存,一级缓存没有,在查询数据库; 二级 ...
- SpringMVC架构&组件&执行流程
SpringMVC架构: 组件: DIspatcherServlet:前端控制器.相当于mvc模式的c,是整个流程控制的中心,负责调用其他组件处理用户的请求,降低了组件之间的耦合性. HandlerM ...
- Flink源码剖析:Jar包任务提交流程
Flink基于用户程序生成JobGraph,提交到集群进行分布式部署运行.本篇从源码角度讲解一下Flink Jar包是如何被提交到集群的.(本文源码基于Flink 1.11.3) 1 Flink ru ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- Flink资料(3)-- Flink一般架构和处理模型
Flink一般架构和处理模型 本文翻译自General Architecture and Process Model ----------------------------------------- ...
随机推荐
- LeetCode Weekly Contest 266
第一题 题解:模拟题 class Solution { public: int countVowelSubstrings(string w) { int n = w.length(); int i = ...
- 线程私有数据TSD——一键多值技术,线程同步中的互斥锁和条件变量
一:线程私有数据: 线程是轻量级进程,进程在fork()之后,子进程不继承父进程的锁和警告,别的基本上都会继承,而vfork()与fork()不同的地方在于vfork()之后的进程会共享父进程的地址空 ...
- HTML 简单介绍
1.什么是HTML > HTML是用来描述网页的一种语言 > HTML指的是超文本标记语言(Hyper Text Markup Language) > 标记语言是一套标记标签(mar ...
- 攻防世界 Misc 新手练习区 stegano CONFidence-DS-CTF-Teaser Writeup
攻防世界 Misc 新手练习区 stegano CONFidence-DS-CTF-Teaser Writeup 题目介绍 题目考点 隐写术 摩斯密码 Writeup 下载附件是PDF文件打开,研究一 ...
- C++ 变量声明 定义 作用域 链接性总结
变量定义 变量的定义用于为变量分配存储空间,还可以为变量指定初始值.在一个程序中,变量有且仅有一个定义. 变量声明 用于向程序表明变量的类型和名字.程序中变量可以声明多次,但只能定义一次. 变量的类型 ...
- hudi clustering 数据聚集(三 zorder使用)
目前最新的 hudi 版本为 0.9,暂时还不支持 zorder 功能,但 master 分支已经合入了(RFC-28),所以可以自己编译 master 分支,提前体验下 zorder 效果. 环境 ...
- 大一C语言学习笔记(2)---快捷键篇
大家好,博主呢,是一位刚刚步入大一的软件工程专业的大学生,之所以写博客,是想要与同样刚刚接触程序员一行的朋友们一起讨论,进步,在这里记录我的一些学习笔记及心得,希望通过这些点点滴滴的努力,可以让我们离 ...
- js--history 对象详解
前言 我们浏览一个网页时可能不太会注意网页前进后退这些操作,但是在开发时你是否想过页面之间的跳转经历了什么,浏览器时怎么保存的页面信息,重新返回上一个页面的时候是否需要重新加载页面呢,会有很对疑问,要 ...
- 痞子衡嵌入式:再测i.MXRT1060,1170上的普通GPIO与高速GPIO极限翻转频率
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT1060/1170上的普通GPIO与高速GPIO极限翻转频率. 按照上一篇文章 <实测i.MXRT1010上的普通GP ...
- [nowcoder5668I]Sorting the Array
令$f(n,b,m)=a[1..n]$(这里下标从1开始),考虑一些性质: 性质1.对于$\forall 1\le i\le n-m+1$,若$\exists 1\le j<i,a[j]> ...