R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当然了这个方法和潜增长和增长曲线模型在做法并没有实际区别,都是用的hlme这个函数。但是文献中的叫法和花样就比较多了。
像本文写的latent class trajectory models,之前写的潜类别增长模型LCGA和增长曲线模型GMM都是潜类别线性混合模型latent class linear mixed models (LCLMM)的分支。
The major difference between LCGA and GMM is that LCGA does not allow within-class variation whereas GMM does allow within-class variation
像这一类的模型都是用hlme这个函数跑,这篇文章也可以看作是作为之前的潜增长和增长曲线文章的一个实际应用的延续。
应用背景
很多的同学关心某个变量的纵向发展轨迹,并且还感兴趣不同轨迹对某个结局的影响如何。如果你的研究也涉及到这样的问题,你就可以考虑用潜类别轨迹模型了,参考文献也甩给大家,大家感兴趣可以去瞅瞅下面这个文章:
Mirza, S. S., Wolters, F. J., Swanson, S. A., Koudstaal, P. J., Hofman, A., Tiemeier, H., & Ikram, M. A. (2016). 10-year trajectories of depressive symptoms and risk of dementia: a population-based study. The Lancet Psychiatry, 3(7), 628-635.
文章作者通过潜类别轨迹模型将人群抑郁症状发展轨迹分成了5类,最终发现只有特定类轨迹才和随后的痴呆有关系,这对痴呆的干预和抑郁痴呆的关系的认识都是有重要意义的。
今天我就仿照这篇文章给大家写写如何做潜类别轨迹模型。
潜类别轨迹的报告内容
做之前我们还是看看这篇文献中是如何介绍这个方法的。
We used latent class trajectory models to identify trajectories of depressive symptoms over time. This is a specialised form of finite mixture modelling, and is designed to identify latent classes of individuals following similar progressions of a determinant over time or with age.
可以看到这个方法在重要作用是识别那些随着时间或者年龄拥有相似症状和疾病进程的人群类别。比如做抑郁的潜类别轨迹就是要识别出人群中可能的抑郁进程亚组。文章中也说明了这个模型就是一个特殊的混合模型specialised form of finite mixture modelling。
在拟合症状随着时间或者年龄变化的时候,我们允许或者说我们需要去考虑症状和时间的曲线关系的,就是说不能简单第认为某个症状的纵向变化一定是线性的,意思就是我们要考虑时间变量的高次项,一般来讲二次就够了。作者的论文中也是加了时间的二次项的。然后根据BIC确定最优类别数,同时确保后验概率大于0.7,类别人数大于0.02.
最终作者出图如下:
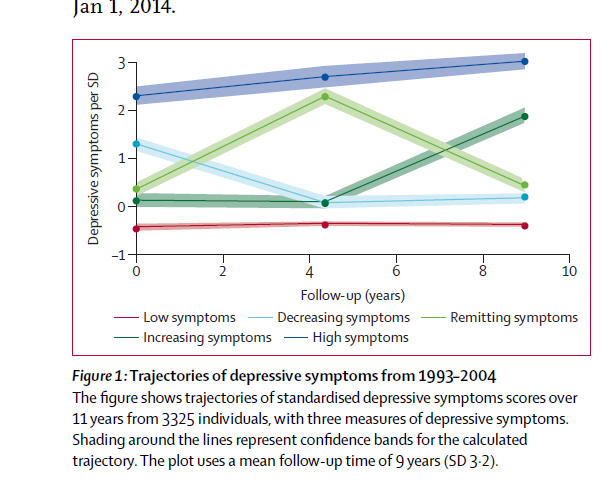
作者根据这个轨迹走势,还给每个类别进行了命名,打上标签,包括Low symptoms,Decreasing symptoms,Remitting symptoms,Increasing symptoms, High symptoms,然后将轨迹标签作为预测变量进行了后续的生存分析。
对于轨迹部分结果的报告,因为这个文章轨迹只是一部分而并非主要目的,所以报告很少,只有每一个轨迹的人群数量和占比。
接下来给大家分享如何做这么一个潜类别轨迹。
潜类别轨迹的做法
潜类别轨迹有专门的R包可以做,感兴趣的同学可以去看这篇文章:
Lennon H, Kelly S, Sperrin M, et al Framework to construct and interpret latent class trajectory modelling BMJ Open 2018;8:e020683. doi: 10.1136/bmjopen-2017-020683
上面这篇文章给出了潜类别轨迹模型的做法框架,共8步:

本文的绝大部分步骤也都是参考的上面的文章。
现在我手上的数据长这样:
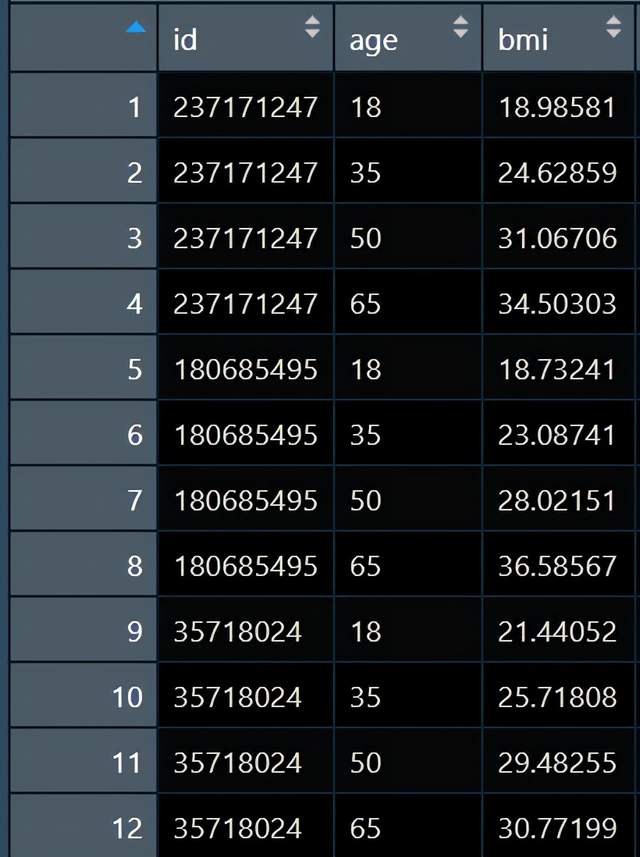
一个纵向的长型数据,包括每个人不同年龄段测得的bmi,我现在就想看看随着年龄的增长,人群bmi轨迹是不是存在异质性亚组。接下来我就用潜类别轨迹模型回答这个问题,并且出图,并得到每个轨迹类别的人数和占比。
首先我们写出轨迹类别数量为1时候的潜类别轨迹的代码:
m.1 <- hlme(bmi ~ 1+ age + I(age^2),
random = ~ 1 + age,
ng = 1,
data = data.frame(bmi), subject = "id")关于hlme之前给大家写过各个参数的意思,上面的代码就是要拟合bmi随着年龄变化的轨迹,同时考虑年龄的随机效应(截距+斜率),并声明嵌套的高水平subject = "id"。运行上面的代码我们就拟合了一个轨迹类别为1的模型。
之后我们还需要拟合2到7个类别的模型,这个7是上面文献推荐的哈,我们可以写个循环语句,一次搞定(为什么不从模型1循环到7呢?是因为ng参数为1时我们并不需要设定mixture参数,所以2到7写了循环,1单独做):
lin <- c(m.1$ng, m.1$BIC)
for (i in 2:7) {
mi <- hlme(fixed = bmi ~ 1+ age + I(age^2),
mixture = ~ 1 + age + I(age^2),
random = ~ 1 + age,
ng = i, nwg = TRUE,
data = data.frame(bmi), subject = "id")
lin <- rbind(lin, c(i, mi$BIC))
}7个模型跑完,我们需要对比每个模型的BIC(这个也是参考的The Lancet Psychiatry那篇文章的做法),所以我们对模型和相应的BIC进行展示:

从上图就可以看得出我们轨迹数量确定为5个时,模型的BIC最小,由此可以确定轨迹数量为5。
按照论文报告的要求我们需要出图,根据图中每条轨迹的走势确定轨迹类别标签,还有每个轨迹类别的人群数量和占比,具体方法如下:
首先,进行图形的绘制,我们解决这类问题(包括机器学习模型)的基本思路依然是通过自我数据得到模型,通过模型拟合新数据出图,代码如下:
plotpred <- predict(m5, datnew, var.time ="age", draws = TRUE)
plot(plotpred, lty=2,xlab="Age", ylab="BMI", legend.loc = "topleft", cex=0.75)上面的代码中m5为我们拟合的5个轨迹类别的模型对象。
运行代码得到图如下:
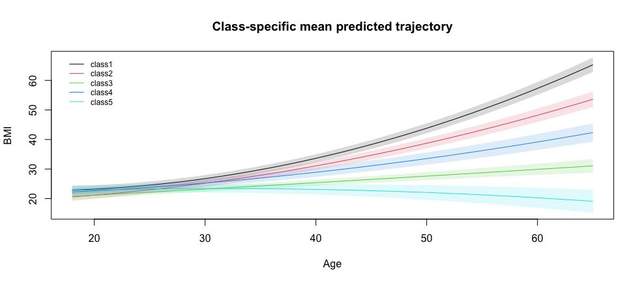
然后我们就可以根据图的走势给每个潜类别轨迹打上有临床意义的标签了,有了标签就可以进行后续的建模了。
然后我们还需要报告每个轨迹类别的人数和占比,方法如下:
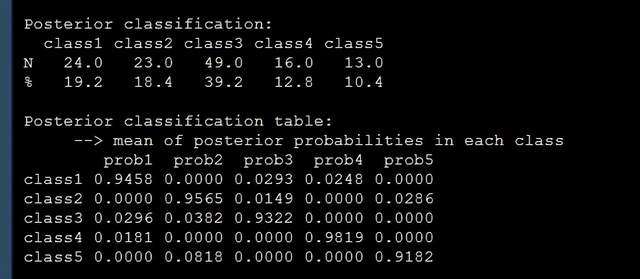
m5$pprob运行代码即可得到,每个个案到底属于哪个轨迹类别,以及其属于每个轨迹类别的概率,如下图:
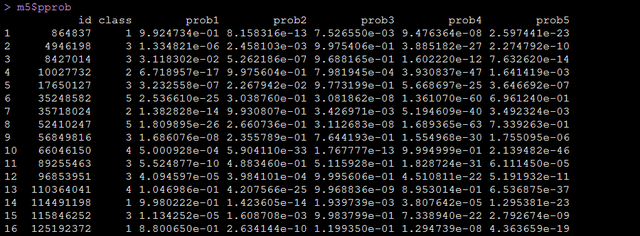
到这儿我们的模型基本跑完了,论文中有提到后验概率大于0.7,类别人数大于0.02,这个在模型总结中也是可以调出来的:
基本上掌握了上面的方法,柳叶刀精神病学那篇文章的前半部分统计分析就完成了,如果你想将某个症状或者疾病发展的轨迹作为自变量的相关研究都可以进行了,好了今天要给大家分享的潜类别轨迹模型的做法就是这样。
后记:写完这篇文章,我越来越觉得潜类别轨迹模型和增长混合模型就是一个东西,只不过不同的学者用词不一样,不知各位看官怎么看,可以私信我交流。
另外,还特别建议大家好好去看lcmm包的说明文档,相信大家看完之后还会有更大收获。
小结
今天给大家写了潜类别轨迹的做法,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另欢迎私信。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、模型构建,科研统计设计等发愁,如果你在使用SPSS, R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供最好的,最详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #Reports, #Composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
往期精彩
R数据分析:什么是人群归因分数Population Attributable Fraction
R数据分析:随机截距交叉滞后RI-CLPM与传统交叉滞后CLPM
R数据分析:潜类别轨迹模型LCTM的做法,实例解析的更多相关文章
- R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临 ...
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:跟随top期刊手把手教你做一个临床预测模型
临床预测模型也是大家比较感兴趣的,今天就带着大家看一篇临床预测模型的文章,并且用一个例子给大家过一遍做法. 这篇文章来自护理领域顶级期刊的文章,文章名在下面 Ballesta-Castillejos ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- 潜类别模型(Latent Class Modeling)
1.潜类别模型概述 潜在类别模型(Latent Class Model, LCM; Lazarsfeld & Henry, 1968)或潜在类别分析(Latent Class Analysis ...
- R数据分析:纵向数据如何做中介,交叉滞后中介模型介绍
看似小小的中介,废了我好多脑细胞,这个东西真的不简单,从7月份有人问我,我多重中介,到现在的纵向数据中介,从一般的回归做法,到结构方程框架下的路径分析法,到反事实框架做法,从中介变量和因变量到是连续变 ...
- Python 和 R 数据分析/挖掘工具互查
如果大家已经熟悉python和R的模块/包载入方式,那下面的表查找起来相对方便.python在下表中以模块.的方式引用,部分模块并非原生模块,请使用 pip install * 安装:同理,为了方便索 ...
- 精心整理(含图版)|你要的全拿走!(R数据分析,可视化,生信实战)
本文首发于“生信补给站”公众号,https://mp.weixin.qq.com/s/ZEjaxDifNATeV8fO4krOIQ更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号. 为 ...
- R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了.想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍 ...
随机推荐
- FastAPI(45)- JSONResponse
背景 创建 FastAPI 路径操作函数时,通常可以从中返回任何数据:字典.列表.Pydantic 模型.数据库模型等 默认情况下,FastAPI 会使用 jsonable_encoder 自动将该返 ...
- 位运算符的用法 ----非(!),与(&),或(|),异或(^)
位运算符的用法 ----非(!),与(&),或(|),异或(^) 三种运算符均针对二进制 非!:是一元运算符.对一个二进制的整数按位取反,输入0则输出1,输入1则输出0. 例: 0100 -( ...
- go语言游戏服务端开发(四)——RPC机制
五邑隐侠,本名关健昌,12年游戏生涯. 本教程以Go语言为例. RPC指远程方法调用,游戏里引入RPC目的是降低跨进程交互的复杂度. 游戏业务设计为多go routine,一个玩家一个go routi ...
- 1.JDBC编程六步走以及实现案例
1.注册驱动:通知Java程序我们要连接的是哪个品牌的数据库 2.获取数据库连接:Java进程和Mysql进程之间的通道开启了 3.获取数据库操作对象:这个对象是用来执行sql语句的 4.执行SQL语 ...
- js高阶
1. 面向对象编程介绍 1.1 两大编程思想 --- 面向过程 --- 面向对象 1.2 面向过程编程 POP 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候在一 ...
- 洛谷2151[SDOI2009]HH去散步(dp+矩阵乘法优化)
一道良好的矩阵乘法优化\(dp\)的题. 首先,一个比较\(naive\)的想法. 我们定义\(dp[i][j]\)表示已经走了\(i\)步,当前在点\(j\)的方案数. 由于题目中限制了不能立即走之 ...
- js 面向对象 动态添加标签
有点逻辑 上代码 thml布局 点击查看代码 <!DOCTYPE html> <html lang="en"> <head> <meta ...
- 简单的 Go 入门教程
Go(又称 Golang )是 Google 开发的一种静态强类型.编译型.并发型,并具有垃圾回收功能的编程语言 Docker 和 Kubernetes 都是使用 Go 进行开发的,这几年 Go 越来 ...
- Frida高级逆向-Hook Native(Java So)
Frida Hook Native Frida Hook Java Jni demo: function hook_java() { Java.perform(function () { const ...
- python web1
***本篇中的测试均需要使用python3完成. 攻击以下面脚本运作的服务器. 针对脚本的代码逻辑,写出生成利用任意代码执行漏洞的恶意序列的脚本: 打开攻击机端口, 将生成的东西输入网页cookie: ...