Python web框架开发 - WSGI协议
浏览器进行http请求的时候,不单单会请求静态资源,还可能需要请求动态页面。
那么什么是静态资源,什么是动态页面呢?
静态资源 : 例如html文件、图片文件、css、js文件等,都可以算是静态资源
动态页面:当请求例如登陆页面、查询页面、注册页面等可能会变化的页面,则是动态页面。
浏览器请求动态页面过程
通过下图来了解一下页面HTTP请求的过程,如下:
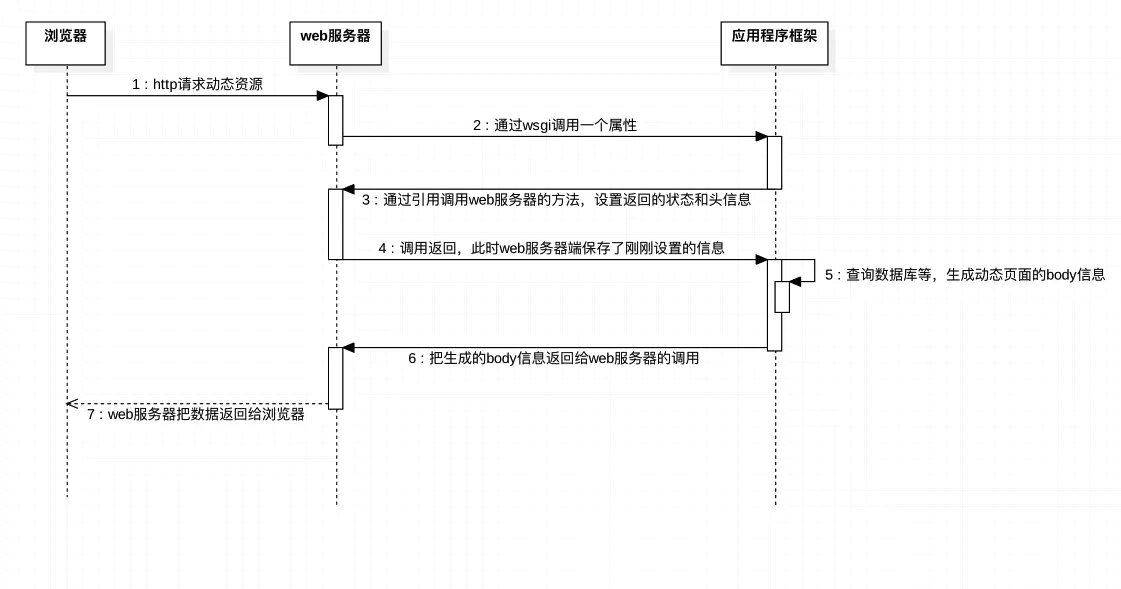
可以看到web服务器是用wsgi协议调用应用程序框架的,这里我们先不讲什么是wsgi协议,先看看我之前写的静态web服务端。
多进程web服务端代码 - 面向过程
#coding=utf-8
from socket import *
import re
import multiprocessing def handle_client(client_socket):
"""为一个客户端服务"""
# 接收对方发送的数据
recv_data = client_socket.recv(1024).decode("utf-8") # 1024表示本次接收的最大字节数
# 打印从客户端发送过来的数据内容
#print("client_recv:",recv_data)
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line) # 返回浏览器数据
# 设置内容body
# 使用正则匹配出文件路径
print("------>",request_header_lines[0])
print("file_path---->","./html/" + re.match(r"[^/]+/([^\s]*)",request_header_lines[0]).group(1))
ret = re.match(r"[^/]+/([^\s]*)",request_header_lines[0])
if ret:
file_path = "./html/" + ret.group(1)
if file_path == "./html/":
file_path = "./html/index.html"
print("file_path *******",file_path) try:
# 设置返回的头信息 header
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 读取html文件内容
file_name = file_path # 设置读取的文件路径
f = open(file_name,"rb") # 以二进制读取文件内容
response_body = f.read()
f.close()
# 返回数据给浏览器
client_socket.send(response_headers.encode("utf-8")) #转码utf-8并send数据到浏览器
client_socket.send(response_body) #转码utf-8并send数据到浏览器
except:
# 如果没有找到文件,那么就打印404 not found
# 设置返回的头信息 header
response_headers = "HTTP/1.1 404 not found\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
response_body = "<h1>sorry,file not found</h1>"
response = response_headers + response_body
client_socket.send(response.encode("utf-8")) #client_socket.close() def main():
# 创建套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 设置服务端提供服务的端口号
server_socket.bind(('', 7788))
# 使用socket创建的套接字默认的属性是主动的,使用listen将其改为被动,用来监听连接
server_socket.listen(128) #最多可以监听128个连接
# 开启while循环处理访问过来的请求
while True:
# 如果有新的客户端来链接服务端,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# server_socket就可以省下来专门等待其他新的客户端连接while True:
client_socket, clientAddr = server_socket.accept()
# handle_client(client_socket)
# 设置子进程
new_process = multiprocessing.Process(target=handle_client,args=(client_socket,))
new_process.start() # 开启子进程 # 因为子进程已经复制了父进程的套接字等资源,所以父进程调用close不会将他们对应的这个链接关闭的
client_socket.close() if __name__ == "__main__":
main()
先来回顾一下运行的情况:
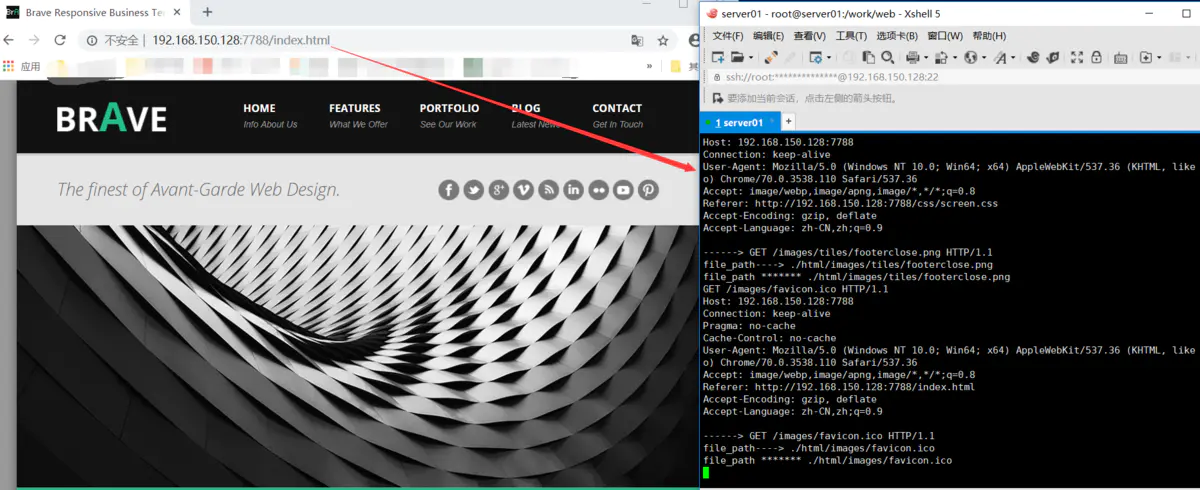
好了,看到运行也是正常的,那么下面就要来分析一下,如何将代码封装为对象。
封装对象分析
首先我需要定义一个webServer类,然后将访问静态资源的功能都封装进去。
#coding=utf-8
from socket import *
import re
import multiprocessing class WebServer: def __init__(self):
# 创建套接字
self.server_socket = socket(AF_INET, SOCK_STREAM)
# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
self.server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 设置服务端提供服务的端口号
self.server_socket.bind(('', 7788))
# 使用socket创建的套接字默认的属性是主动的,使用listen将其改为被动,用来监听连接
self.server_socket.listen(128) #最多可以监听128个连接 def start_http_service(self):
# 开启while循环处理访问过来的请求
while True:
# 如果有新的客户端来链接服务端,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# self.server_socket就可以省下来专门等待其他新的客户端连接while True:
client_socket, clientAddr = self.server_socket.accept()
# handle_client(client_socket)
# 设置子进程
new_process = multiprocessing.Process(target=self.handle_client,args=(client_socket,))
new_process.start() # 开启子进程
# 因为子进程已经复制了父进程的套接字等资源,所以父进程调用close不会将他们对应的这个链接关闭的
client_socket.close() def handle_client(self,client_socket):
"""为一个客户端服务"""
# 接收对方发送的数据
recv_data = client_socket.recv(1024).decode("utf-8") # 1024表示本次接收的最大字节数
# 打印从客户端发送过来的数据内容
#print("client_recv:",recv_data)
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line) # 返回浏览器数据
# 设置内容body
# 使用正则匹配出文件路径
print("------>",request_header_lines[0])
print("file_path---->","./html/" + re.match(r"[^/]+/([^\s]*)",request_header_lines[0]).group(1))
ret = re.match(r"[^/]+/([^\s]*)",request_header_lines[0])
if ret:
file_path = "./html/" + ret.group(1)
if file_path == "./html/":
file_path = "./html/index.html"
print("file_path *******",file_path) try:
# 设置返回的头信息 header
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 读取html文件内容
file_name = file_path # 设置读取的文件路径
f = open(file_name,"rb") # 以二进制读取文件内容
response_body = f.read()
f.close()
# 返回数据给浏览器
client_socket.send(response_headers.encode("utf-8")) #转码utf-8并send数据到浏览器
client_socket.send(response_body) #转码utf-8并send数据到浏览器
except:
# 如果没有找到文件,那么就打印404 not found
# 设置返回的头信息 header
response_headers = "HTTP/1.1 404 not found\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
response_body = "<h1>sorry,file not found</h1>"
response = response_headers + response_body
client_socket.send(response.encode("utf-8")) def main():
webserver = WebServer()
webserver.start_http_service() if __name__ == "__main__":
main()
好了,从上面的代码来看,我已经将前面面向过程的代码修改为面向对象了。
运行一下看看有没有错误:
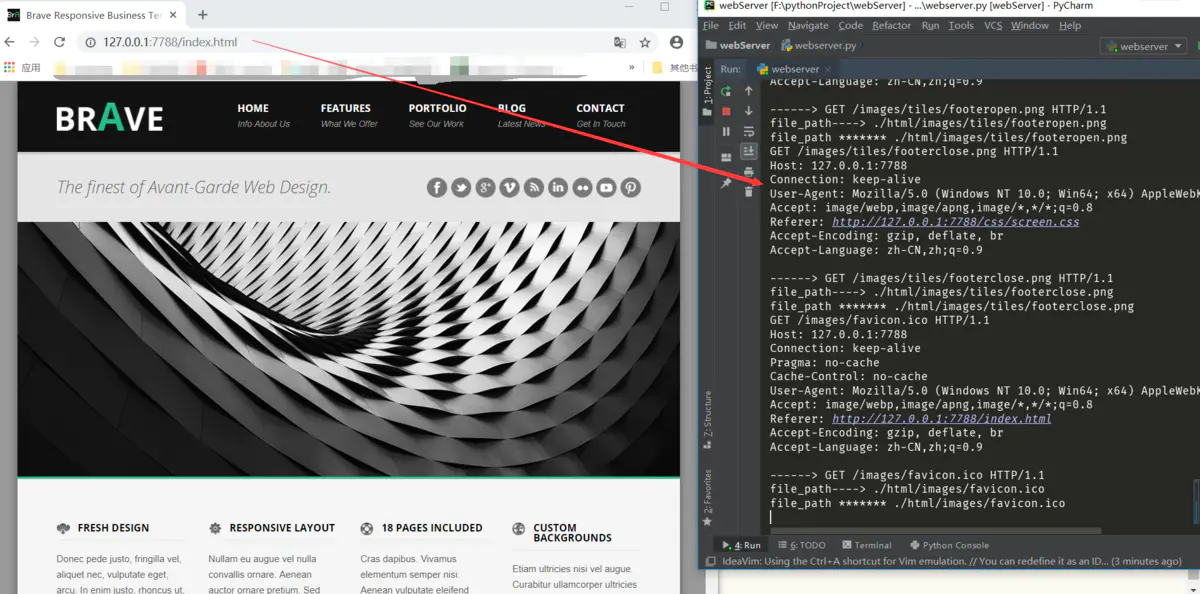
思考:已经封装为对象了,下一步还要优化什么呢?
请求静态资源的页面已经可以了,那么如果请求动态的页面呢?
如果web服务端是java写的话,通常http请求就是http:xxxx/xxx.jsp
如果web服务端是php写的话,通常http请求就是http:xxxx/xxx.php
那么,既然这次我使用python来写,就可以定义动态资源的请求为http:xxxx/xxx.py
那么如果来识别并执行 http:xxxx/xxx.py 的请求呢?
增加识别动态资源请求的功能
需求:识别并返回http:xxxx/xxx.py 的请求
那么让我想一下,先做个简单的,例如:我请求一个http的请求 http:xxxx/time.py 则返回一个当前服务端的时间给浏览器。
那么如果http请求了一个py结尾的请求,我需要在哪里处理呢?
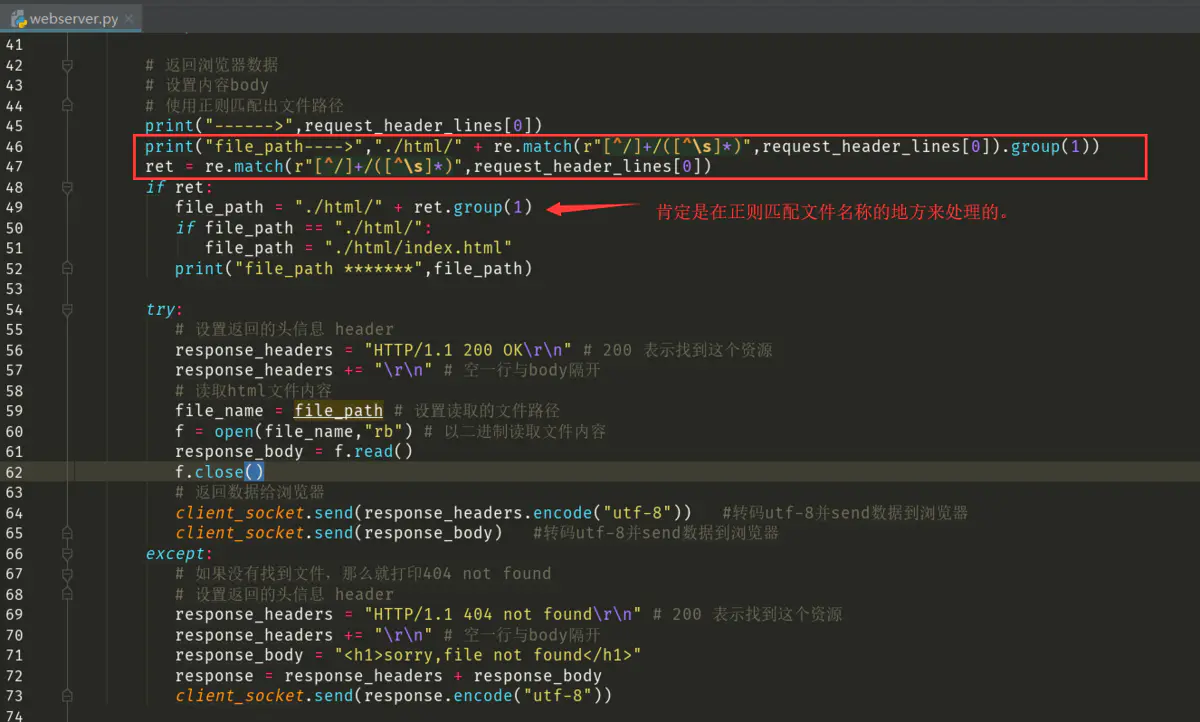
还有我可以用什么方法来判断 .py 后缀的文件呢?
用正则匹配?
其实可以使用endswith("文件后缀")的方法来判断处理。
In [1]: file_name = "time.py" # 匹配后缀为 .html ,直接报False
In [3]: file_name.endswith(".html")
Out[3]: False # 匹配后缀为 .py ,则报True
In [4]: file_name.endswith(".py")
Out[4]: True
那么下面就可以来写写这里判断的处理分支了。
测试执行一下:
首先请求HTML等静态资源页面
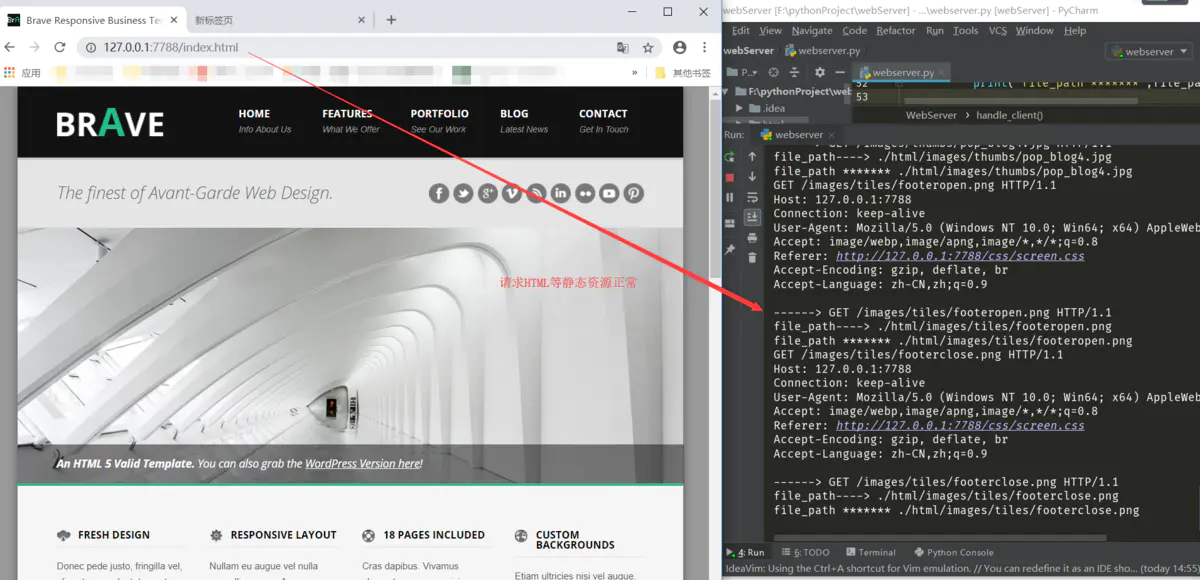
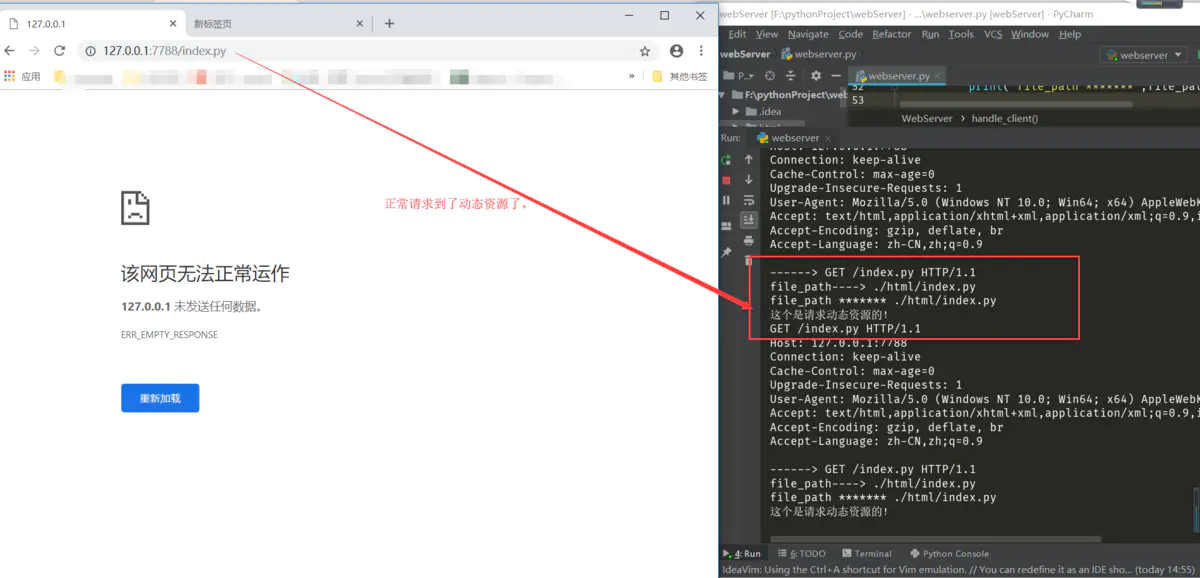
请求动态资源页面
先简单地写一串HTML+当前服务器时间的内容吧。
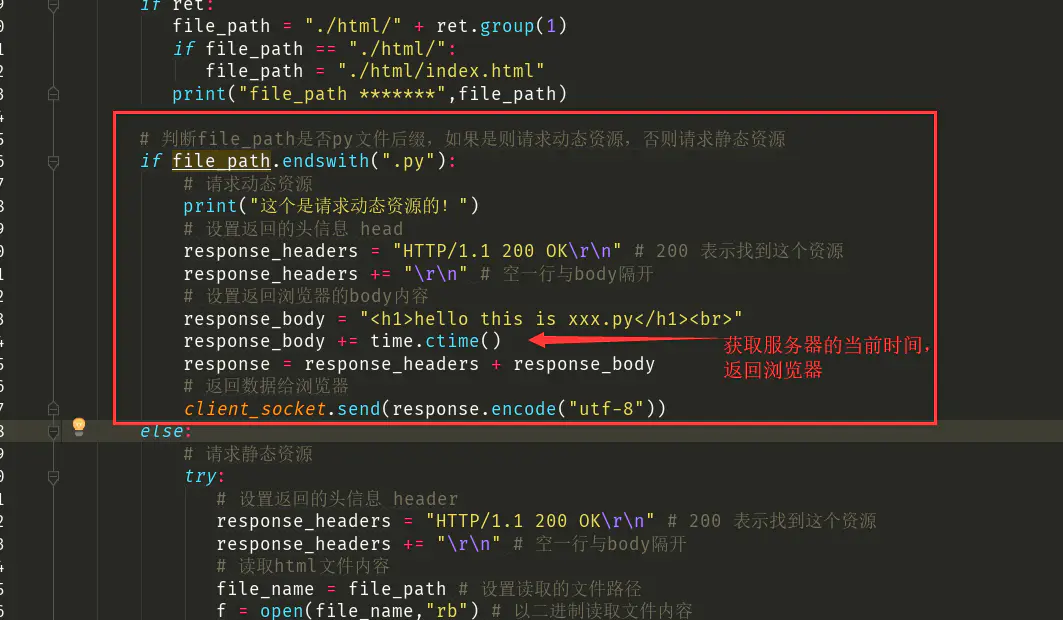

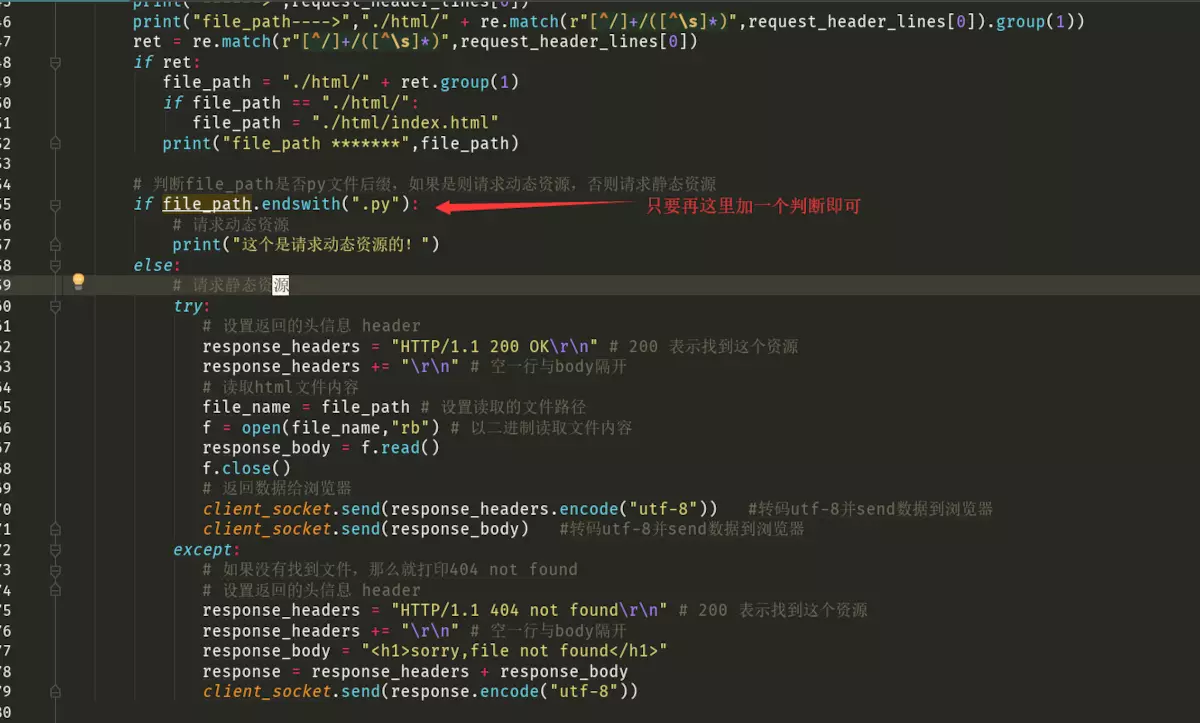
if file_path.endswith(".py"):
# 请求动态资源
print("这个是请求动态资源的!")
# 设置返回的头信息 head
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 设置返回浏览器的body内容
response_body = "<h1>hello this is xxx.py</h1><br>"
response_body += time.ctime()
response = response_headers + response_body
# 返回数据给浏览器
client_socket.send(response.encode("utf-8"))
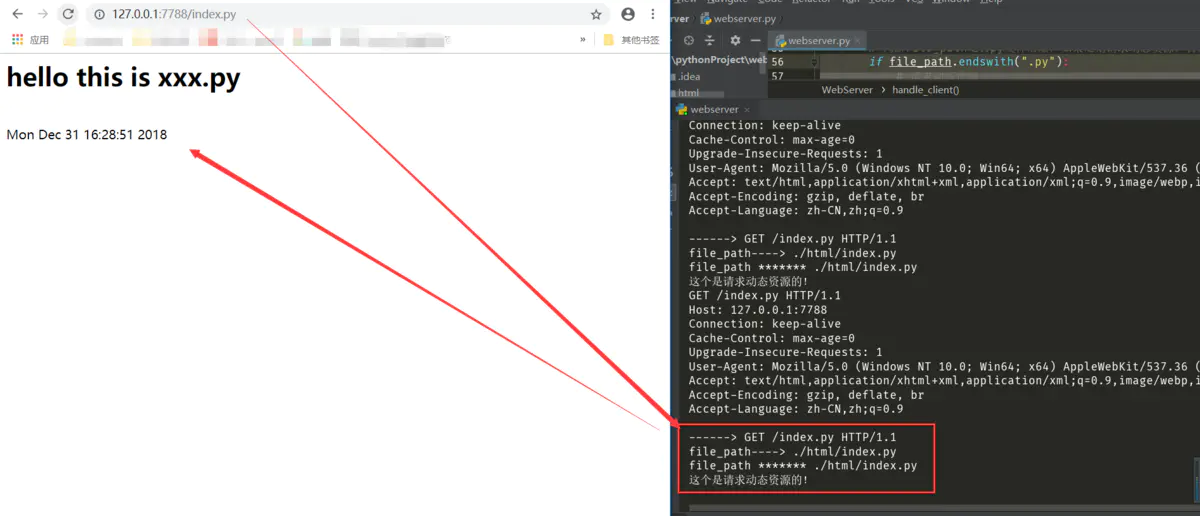
从这里已经可以正常返回动态页面的内容的了。
思考 :如果将动态处理页面的代码在web服务端不断地写,代码就会很庞大。是否可以拆分出来,服务端只接受浏览器的消息,判断静态还是动态以及其他业务功能放到另一个模块进行编写呢?
这里就涉及到 web服务端 与 业务处理服务端 之间的一个协议了,这个业界内通用的协议就是 WSGI协议。
为什么需要 WSGI协议
在讲WSGI协议之前,我先把处理动态页面的功能拆分到另一个模块文件中。
import time def application(client_socket):
# 请求动态资源
print("这个是请求动态资源的!")
# 设置返回的头信息 head
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 设置返回浏览器的body内容
response_body = "<h1>hello this is xxx.py</h1><br>"
response_body += time.ctime()
response = response_headers + response_body
# 返回数据给浏览器
client_socket.send(response.encode("utf-8"))
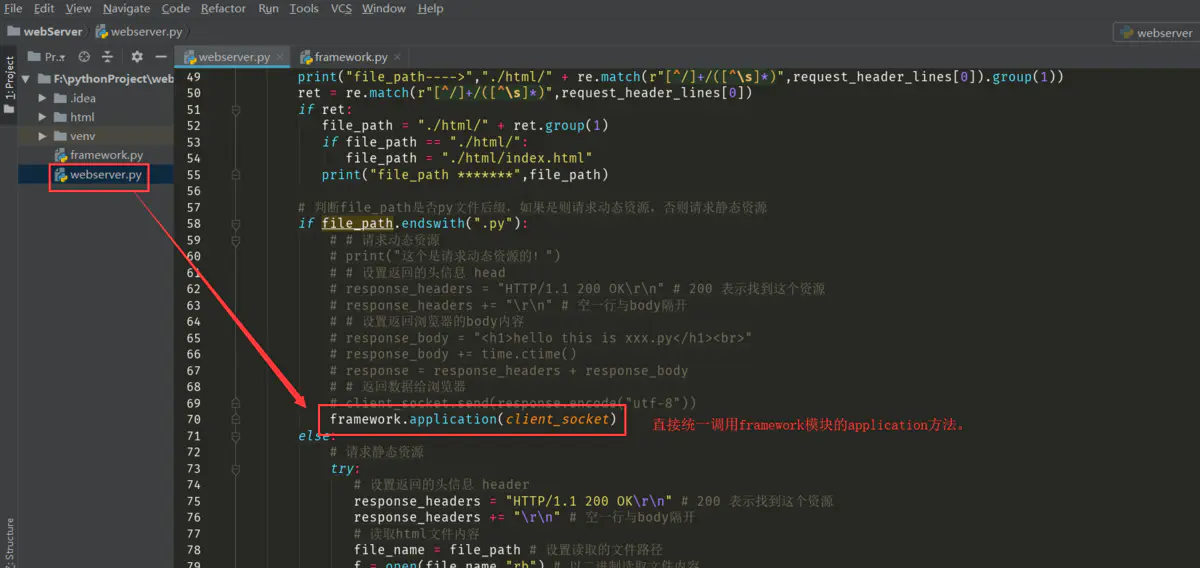
那么在原来的webserver.py模块只要import该模块文件,使用application()方法就可以处理刚才的业务了。
好了,做了这个解耦的操作之后,下面来运行测试一下:
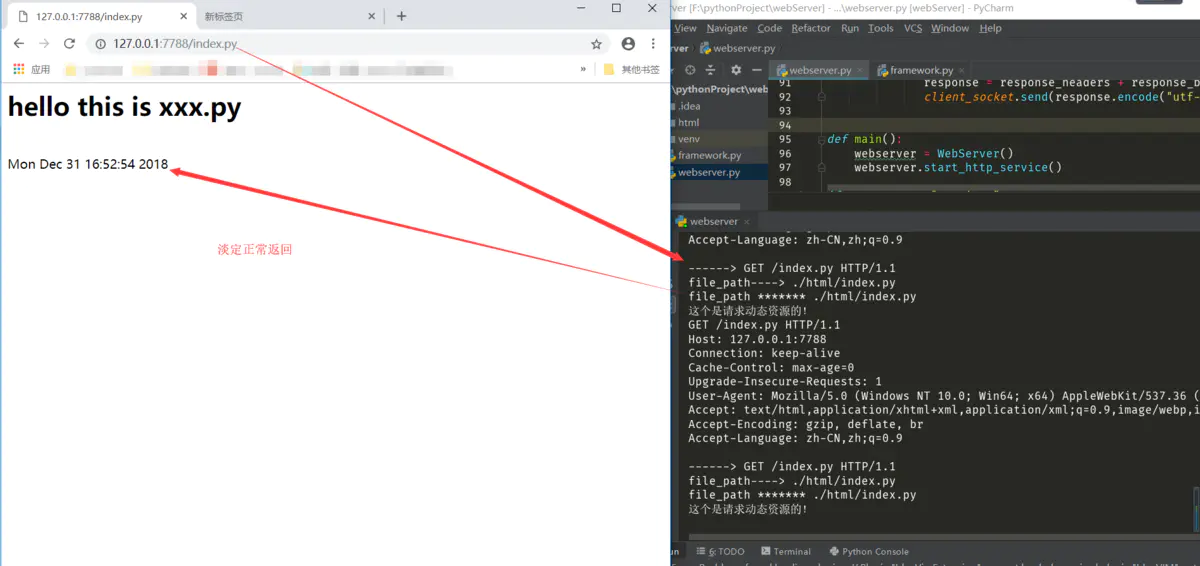
从上面的调用结果来看,的确是调用成功啦,理解大概如下图:
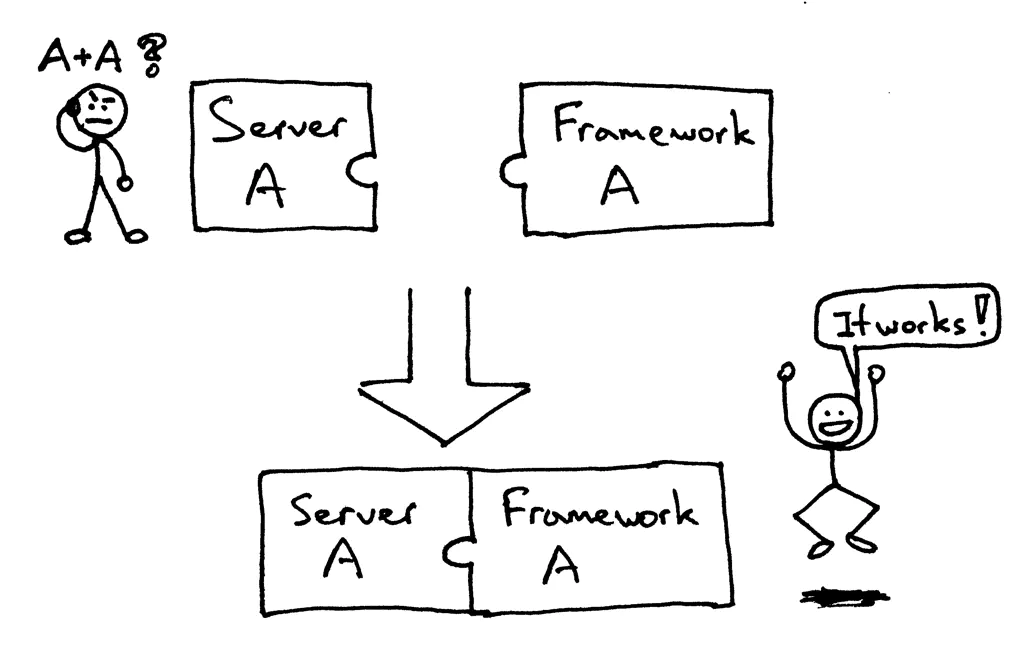
可以看出来,webserver想要调用 framework处理业务的话,就要这样去写,如下:
framework.application(client_socket)
这种方式虽然可行,但是在业界中是不通用的。也就是说这种调用方法扔给别人写的框架,就无法兼容了。
例如:假设我后面改用Django、Flask框架来处理业务,此时一定就不是用这种方式来通讯调用的。

那么该用什么方式呢?
是否可以修改服务器和架构代码而确保可以在多个架构下,保证与web服务器之间的通讯调用呢?
答案就是 Web Server Gateway Interface (或简称 WSGI,读作“wizgy”)。
WSGI协议的介绍
WSGI允许开发者将选择web框架和web服务器分开。可以混合匹配web服务器和web框架,选择一个适合的配对。
比如,可以在Gunicorn 或者 Nginx/uWSGI 或者 Waitress上运行 Django, Flask, 或 Pyramid。真正的混合匹配,得益于WSGI同时支持服务器和架构。
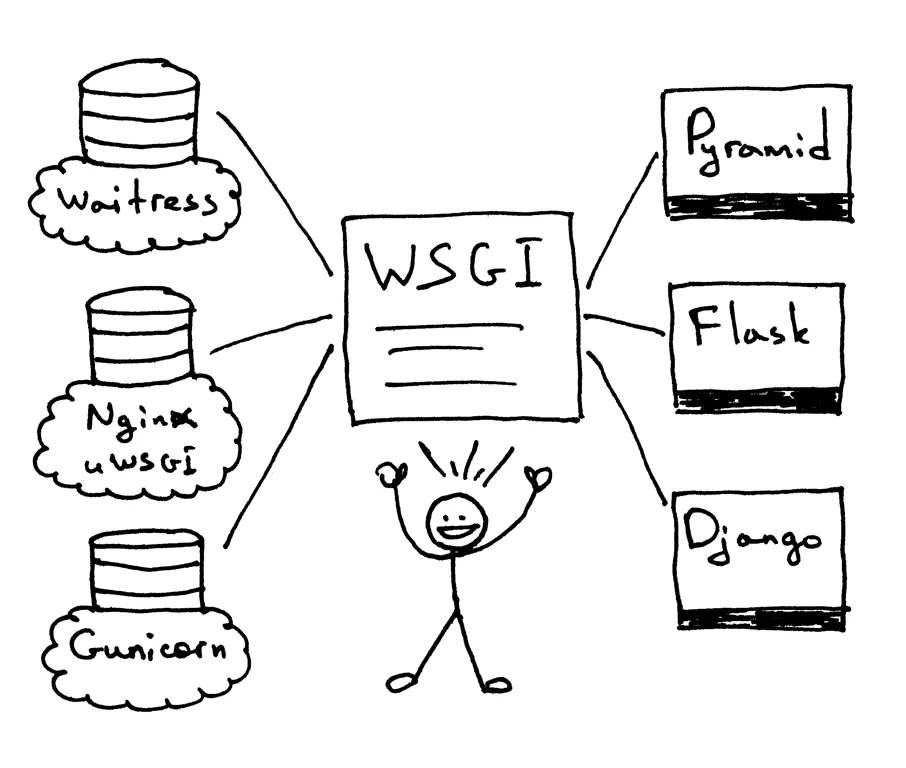
web服务器必须具备WSGI接口,所有的现代Python Web框架都已具备WSGI接口,它让你不对代码作修改就能使服务器和特点的web框架协同工作。
定义WSGI接口
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return 'Hello World!'
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
- environ:一个包含所有HTTP请求信息的dict对象;
- start_response:一个发送HTTP响应的函数。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,把底层web服务器解析部分和应用程序逻辑部分进行了分离,这样开发者就可以专心做一个领域了。
编写framwork支持WSGI协议,实现浏览器显示 hello world
直接协议规范代码复制进去。
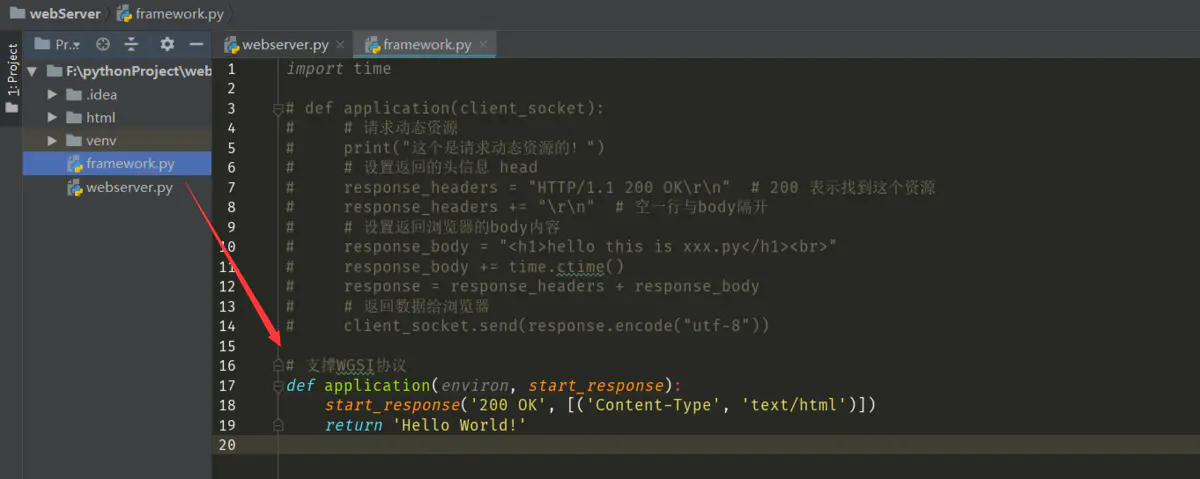
那么在webserver.py的部分,就需要接受application返回的信息。
首先,start_response 就是在framwork设置http请求header信息的。而return 就是返回http请求body信息的。
那么知道了这两点之后,下一步要做的。就是想办法来接受这个application的设置header以及body信息。
那么怎么处理呢?
为了方便对比查看这两个文件的代码,使用pycharm同时打开两个视图窗口来查看。

好了,下面来继续看看。
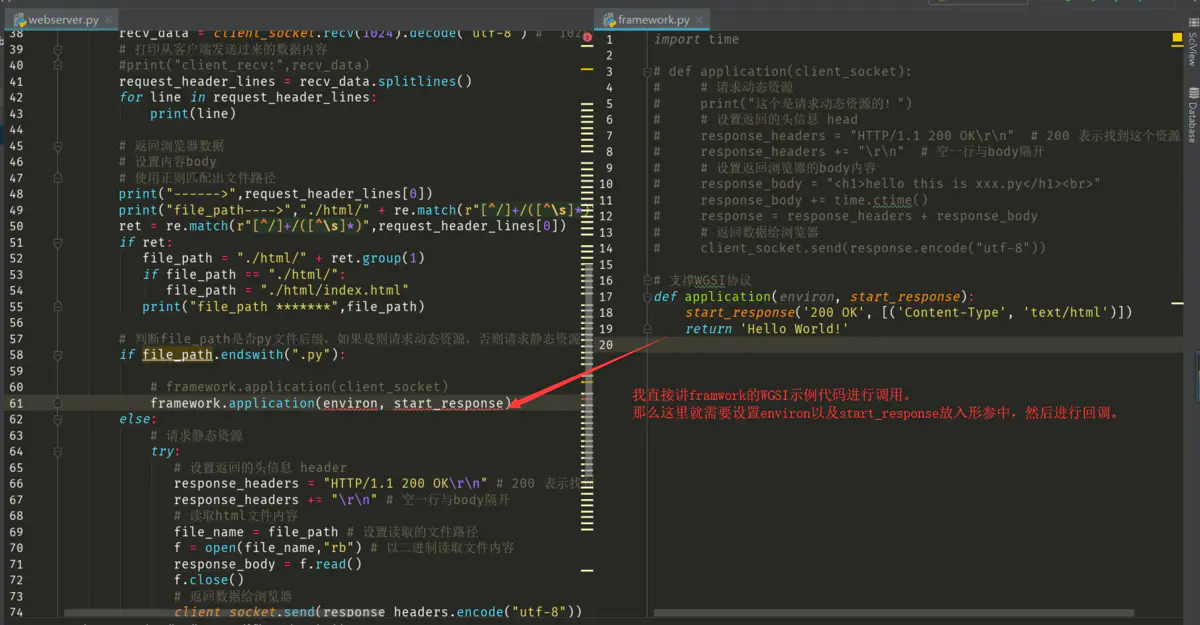
下面来创建这两个形参:
- environ:一个包含所有HTTP请求信息的dict对象;
- start_response:一个发送HTTP响应的函数。
先随便写个空的,来填入WSGI规范所需要的参数。
其中response_body通过return的返回值就可以接受到了。
那么response_header该怎么处理呢?
可以从代码中看出start_response 在webserver.py 传入到 framwork.py 的application中调用。
其中在application中就直接设置header信息到start_response的参数中。然后我在webserver.py能否直接将其取出来,拼接成header信息呢?
编写start_response 接收 header 信息
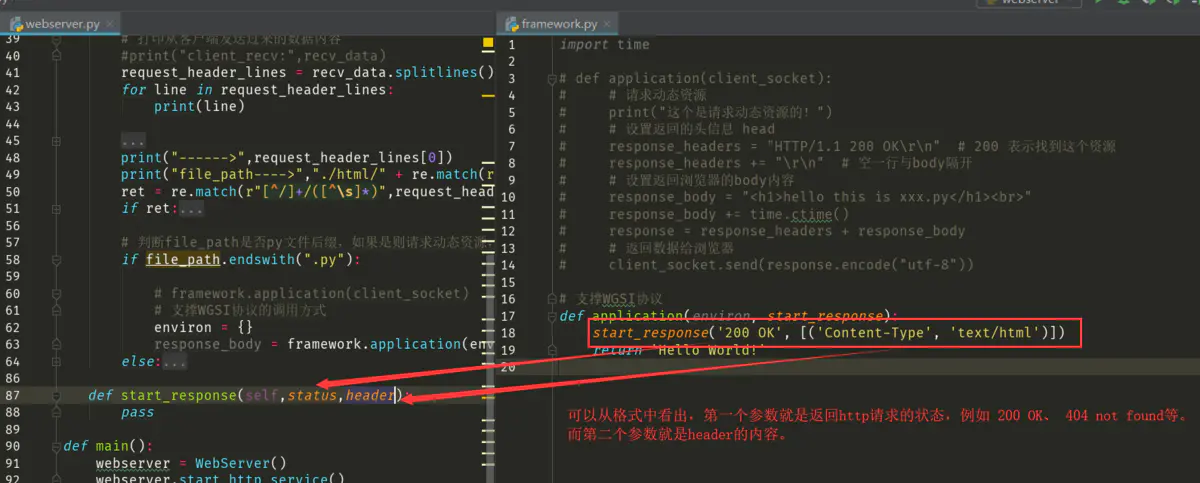
那么首先编写一个类变量来保存信息,然后测试打印一下看看。

运行测试一下看看:

那么只要将其保存到self.application_header中,我就可以在类方法的任意一个地方进行拆分或者拼接成所需要的http header返回值了。
编写如下:
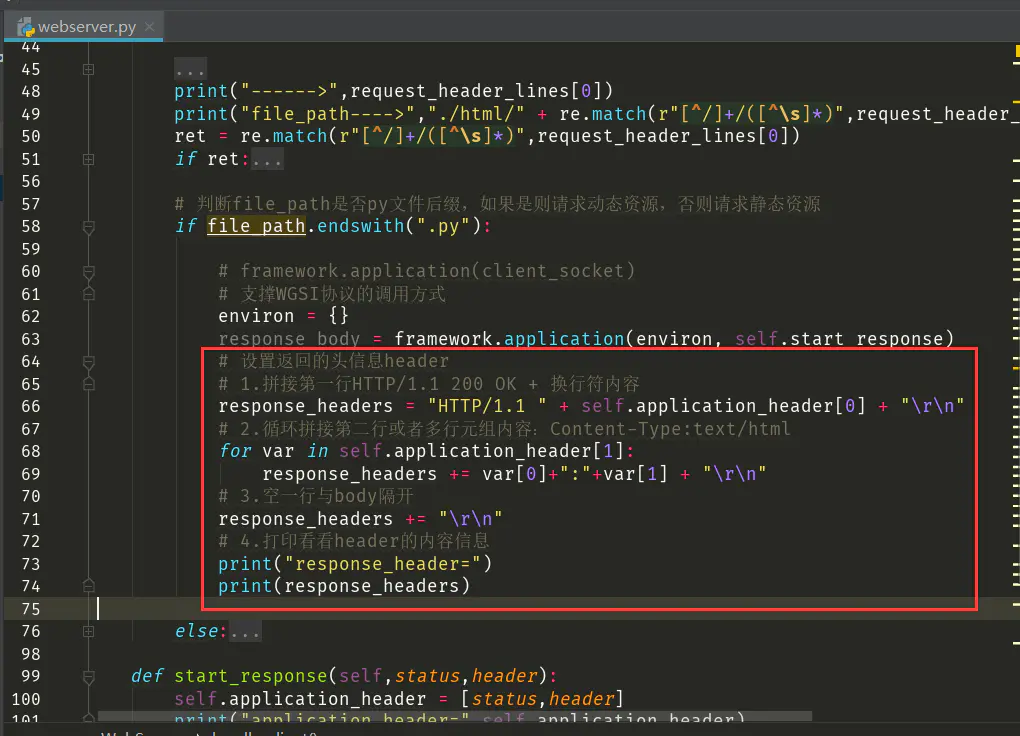
运行测试看看。
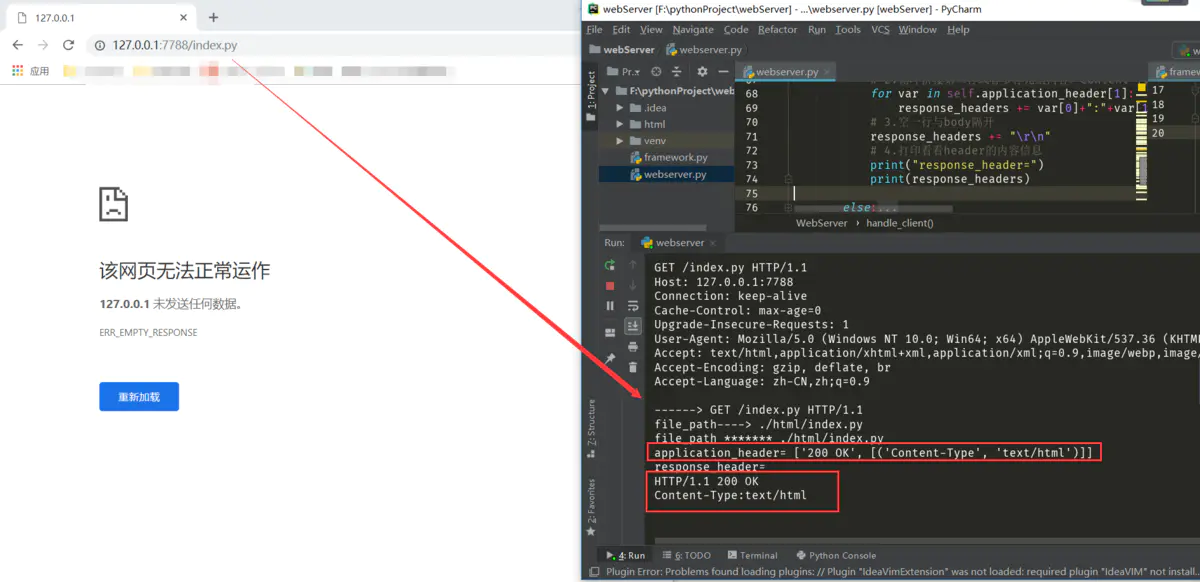
这样就得到了完成的header内容啦,那么下面将其拼接body内容,然后返回浏览器中显示。
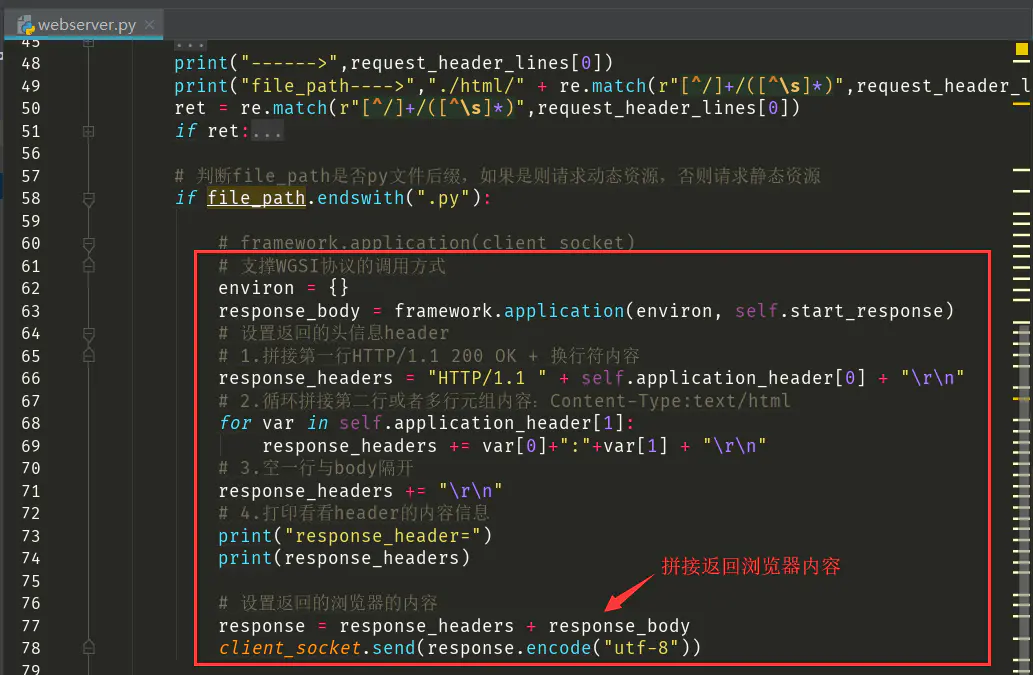
运行测试如下:
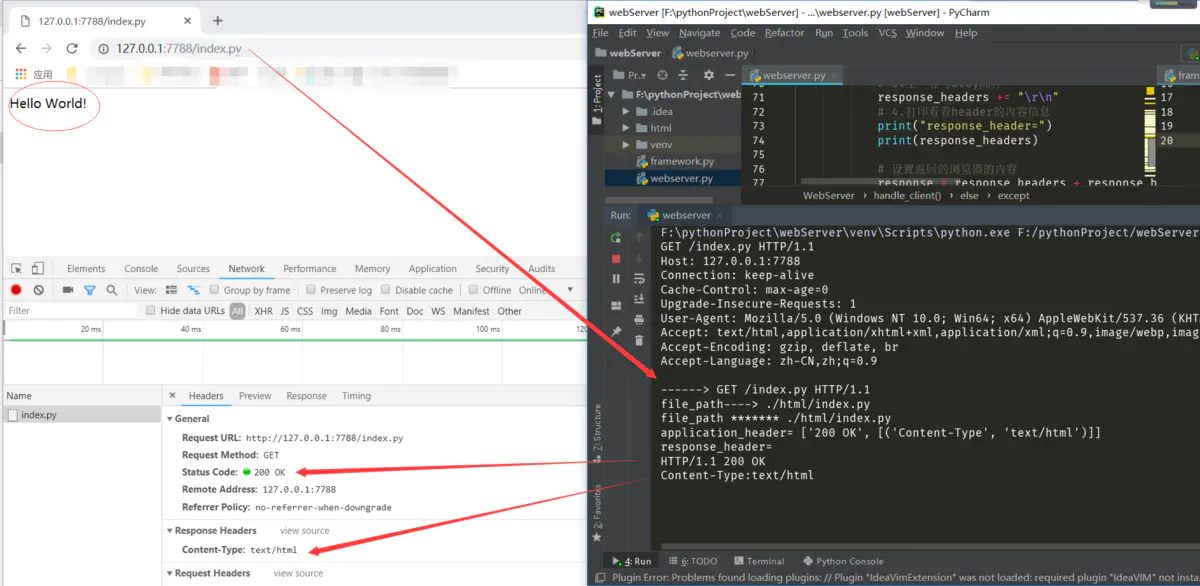
本次开发的完整代码如下:
webserver.py
#coding=utf-8
from socket import *
import re
import multiprocessing
import time
import framework class WebServer: def __init__(self):
# 创建套接字
self.server_socket = socket(AF_INET, SOCK_STREAM)
# 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口
self.server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
# 设置服务端提供服务的端口号
self.server_socket.bind(('', 7788))
# 使用socket创建的套接字默认的属性是主动的,使用listen将其改为被动,用来监听连接
self.server_socket.listen(128) #最多可以监听128个连接 def start_http_service(self):
# 开启while循环处理访问过来的请求
while True:
# 如果有新的客户端来链接服务端,那么就产生一个新的套接字专门为这个客户端服务
# client_socket用来为这个客户端服务
# self.server_socket就可以省下来专门等待其他新的客户端连接while True:
client_socket, clientAddr = self.server_socket.accept()
# handle_client(client_socket)
# 设置子进程
new_process = multiprocessing.Process(target=self.handle_client,args=(client_socket,))
new_process.start() # 开启子进程
# 因为子进程已经复制了父进程的套接字等资源,所以父进程调用close不会将他们对应的这个链接关闭的
client_socket.close() def handle_client(self,client_socket):
"""为一个客户端服务"""
# 接收对方发送的数据
recv_data = client_socket.recv(1024).decode("utf-8") # 1024表示本次接收的最大字节数
# 打印从客户端发送过来的数据内容
#print("client_recv:",recv_data)
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line) # 返回浏览器数据
# 设置内容body
# 使用正则匹配出文件路径
print("------>",request_header_lines[0])
print("file_path---->","./html/" + re.match(r"[^/]+/([^\s]*)",request_header_lines[0]).group(1))
ret = re.match(r"[^/]+/([^\s]*)",request_header_lines[0])
if ret:
file_path = "./html/" + ret.group(1)
if file_path == "./html/":
file_path = "./html/index.html"
print("file_path *******",file_path) # 判断file_path是否py文件后缀,如果是则请求动态资源,否则请求静态资源
if file_path.endswith(".py"): # framework.application(client_socket)
# 支撑WGSI协议的调用方式
environ = {}
response_body = framework.application(environ, self.start_response)
# 设置返回的头信息header
# 1.拼接第一行HTTP/1.1 200 OK + 换行符内容
response_headers = "HTTP/1.1 " + self.application_header[0] + "\r\n"
# 2.循环拼接第二行或者多行元组内容:Content-Type:text/html
for var in self.application_header[1]:
response_headers += var[0]+":"+var[1] + "\r\n"
# 3.空一行与body隔开
response_headers += "\r\n"
# 4.打印看看header的内容信息
print("response_header=")
print(response_headers) # 设置返回的浏览器的内容
response = response_headers + response_body
client_socket.send(response.encode("utf-8")) else:
# 请求静态资源
try:
# 设置返回的头信息 header
response_headers = "HTTP/1.1 200 OK\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
# 读取html文件内容
file_name = file_path # 设置读取的文件路径
f = open(file_name,"rb") # 以二进制读取文件内容
response_body = f.read()
f.close()
# 返回数据给浏览器
client_socket.send(response_headers.encode("utf-8")) #转码utf-8并send数据到浏览器
client_socket.send(response_body) #转码utf-8并send数据到浏览器
except:
# 如果没有找到文件,那么就打印404 not found
# 设置返回的头信息 header
response_headers = "HTTP/1.1 404 not found\r\n" # 200 表示找到这个资源
response_headers += "\r\n" # 空一行与body隔开
response_body = "<h1>sorry,file not found</h1>"
response = response_headers + response_body
client_socket.send(response.encode("utf-8")) def start_response(self,status,header):
self.application_header = [status,header]
print("application_header=",self.application_header) def main():
webserver = WebServer()
webserver.start_http_service() if __name__ == "__main__":
main()
framework.py
# 支撑WGSI协议
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return 'Hello World!'
来源:简书
作者:DevOps海洋的渔夫
链接:https://www.jianshu.com/p/417cd1989781
Python web框架开发 - WSGI协议的更多相关文章
- python web框架 django wsgi 理论
django wsgi python有个自带的wsgi模块 可以写自定义web框架 用wsgi在内部创建socket对象就可以了 自己只写处理函数就可以了django只是web框架 他也不负责写soc ...
- [Python web开发] Web框架开发基础 (一)
Python WEB框架 WSGI,WEB Server Gateway Interface,可以看做是一种底层协议,它规定了服务器程序和应用程序各自实现上面接口.Python的实现称为wsgiref ...
- Python Web框架本质——Python Web开发系列一
前言:了解一件事情本质的那一瞬间总能让我获得巨大的愉悦感,希望这篇文章也能帮助到您. 目的:本文主要简单介绍Web开发中三大基本功能:Socket实现.路由系统.模板引擎渲染. 进入正题. 一. 基础 ...
- python三大web框架Django,Flask,Flask,Python几种主流框架,13个Python web框架比较,2018年Python web五大主流框架
Python几种主流框架 从GitHub中整理出的15个最受欢迎的Python开源框架.这些框架包括事件I/O,OLAP,Web开发,高性能网络通信,测试,爬虫等. Django: Python We ...
- 微型 Python Web 框架: Bottle
微型 Python Web 框架: Bottle 在 19/09/11 07:04 PM 由 COSTONY 发表 Bottle 是一个非常小巧但高效的微型 Python Web 框架,它被设计为仅仅 ...
- 一文读懂Python web框架和web服务器之间的关系
我们都知道 Python 作为一门强大的语言,能够适应快速原型和较大项目的制作,因此被广泛用于 web 应用程序的开发中. 在面试的过程中,大家或多或少都被问到过这样一个问题:一个请求从浏览器发出到数 ...
- Django,Flask,Tornado三大框架对比,Python几种主流框架,13个Python web框架比较,2018年Python web五大主流框架
Django 与 Tornado 各自的优缺点Django优点: 大和全(重量级框架)自带orm,template,view 需要的功能也可以去找第三方的app注重高效开发全自动化的管理后台(只需要使 ...
- 2018年要学习的10大Python Web框架
通过为开发人员提供应用程序开发结构,框架使开发人员的生活更轻松.他们自动执行通用解决方案,缩短开发时间,并允许开发人员更多地关注应用程序逻辑而不是常规元素. 在本文中,我们分享了我们自己的前十大Pyt ...
- Python Web 应用:WSGI基础
在Django,Flask,Bottle和其他一切Python web 框架底层的是Web Server Gateway Interface,简称WSGI.WSGI对Python来说就像 Servle ...
随机推荐
- 应用层协议——DHCP
常见协议分层 网洛层协议:包括:IP协议.ICMP协议.ARP协议.RARP协议. 传输层协议:TCP协议.UDP协议. 应用层协议:FTP.Telnet.SMTP.HTTP.RIP.NFS.DNS ...
- 2、Redis的安装
一.Windows下Redis安装 下载地址 Redis中文网站 Github地址 1.将下载下来的文件解压到目录 2.双击redis-server.exe运行 出现如下界面证明运行成功 3.双击 ...
- Mongodb集群调研
目录 一.高可用集群的解决方案 二.MongoDB的高可用集群配置 三.Mongo集群实现高可用方式详解 四.Sharding分片技术 一.高可用集群的解决方案 高可用性即HA(High Availa ...
- 阿里面试题: (a,b,c)组合索引, 查询语句select...from...where a=.. and c=..走索引吗?
面试官:(a,b,c)组合索引,查询语句select...from...where a=.. and c=..走索引吗应聘者: 最佳左前缀法,如果索引了多列,要遵守最左前缀法则,否则索引失效 按最左前 ...
- 对ORM的理解
1. 在面试中可能会问到这个问题,什么是ORM? ORM是对象关系映射(Object Relational Mapping),简称ORM,或O/RM,或O/R mapping,是一种程序技术. 白话理 ...
- java 编程基础 反射方式获取泛型的类型Fileld.getGenericType() 或Method.getGenericParameterTypes(); (ParameterizedType) ;getActualTypeArguments()
引言 自从JDK5以后,Java Class类增加了泛型功能,从而允许使用泛型来限制Class类,例如,String.class的类型实际上是 Class 如果 Class 对应的类暂时未知,则使 C ...
- .Net Core 文件打包压缩
最近项目需要实现多文件打包的功能,尝试了一些方法,最后发现使用 ICSharpCode.SharpZipLib 最符合项目的要求. 具体实现如下: 1.在 Nuget 中安装 ICSharpCod ...
- Maven配置使用阿里云镜像
在settings.xml文件中的mirrors下添加mirror标签 <!-- 阿里云仓库 --> <mirror> <id>alimaven</id> ...
- Android NDK开发篇:Java与原生代码通信(数据操作)
虽然说使用NDK可以提高Android程序的执行效率,但是调用起来还是稍微有点麻烦.NDK可以直接使用Java的原生数据类型,而引用类型,因为Java的引用类型的实现在NDK被屏蔽了,所以在NDK使用 ...
- 【LeetCode】674. Longest Continuous Increasing Subsequence 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 动态规划 空间压缩DP 日期 题目地址:https: ...