MongoDB_文档存储结构(三)
MongoDB 文档数据库的存储结构分为四个层次,从大到小依次是:数据库(database)、集合(collection)、文档(document)、键值对。
图 1 描述了 MongoDB 与 MySQL 的对应关系,可以看出,MongoDB中的数据库、集合、文档对应于MySQL数据库中的数据库、表、一行数据。

图 1:MongoDB与 Mysql的对比
数据库
在 MongoDB 中,数据库由集合组成。一个 MongoDB 实例可承载多个数据库,互相之间彼此独立,在开发过程中,通常将一个应用的所有数据存储到同一个数据库中,MongoDB 将不同数据库存放在不同文件中。
数据库结构示例如图 2所示。
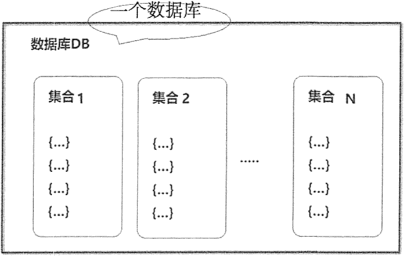
图2
集合
MongoDB 将文档存储在集合中,一个集合是一些文档构成的对象。如果说 MongoDB 中的文档类似于关系型数据库中的“行”,那么集合就如同“表”。
集合存在于数据库中,没有固定的结构,这意味着用户对集合可以插入不同格式和类型的数据。但通常情况下插入集合的数据都会有一定的关联性,即一个集合中的文档应该具有相关性。
集合的结构如图 3 所示。

图3
文档
文档是 MongoDB 的核心概念,是数据的基本单元,与关系数据库中的行十分类似,但是比行要复杂。文档是一组有序的键值对集合。文档的数据结构与 JSON 基本相同,所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类 JSON 的二进制存储格式,是 Binary JSON 的简称。 一个简单的文档例子如下:
{"country" : "China", "city": "BeiJing"}
MongoDB 中的数据具有灵活的架构,集合不强制要求文档结构。但数据建模的不同可能会影响程序性能和数据库容量。文档之间的关系是数据建模需要考虑的重要因素。文档与文档之间 的关系包括嵌入和引用两种。
下面举一个关于顾客 patron 和地址 address 之间的例子,来说明在某些情况下,嵌入优于引用。
{
_id: "joe",
name: "Joe Bookreader"
}
{
patron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "2345"
}
关系数据库的数据模型在设计时,将 patron 和 address 分到两个表中,在查询时进行关联, 这就是引用的使用方式。如果在实际查询中,需要频繁地通过 _id 获得 address 信息,那么就需要频繁地通过关联引用来返回查询结果。在这种情况下,一个更合适的数据模型就是嵌入。
将 address 信息嵌入 patron 信息中,这样通过一次查询就可获得完整的 patron 和 address 信息,如下所示:
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon”,
state: nMAnz
zip: T2345”
}
}
如果具有多个 address,可以将其嵌入 patron 中,通过一次查询就可获得完整的 patron 和多个 address 信息,如下所示:
{
_id: "joe",
name: "Joe Bookreader",
addresses:[
{
street: "123 Fake Streetn,
city: "Faketon",
state: "MA",
zip: "12345"
},
{
street: "l Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
]
}
但在某种情况下,引用用比嵌入更有优势。下面举一个图书出版商与图书信息的例子,代码如下:
{
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolfn"],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
{
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
从上边例子可以看出,嵌入式的关系导致出版商的信息重复发布,这时可采用引用的方式描述集合之间的关系。使用引用时,关系的增长速度决定了引用的存储位置。如果每个出版商的图书数量很少且增长有限,那么将图书信息存储在出版商文档中是可行的。
通过 books 存储每本图书的 id 信息,就可以查询到指定图书出版商的指定图书信息,但如果图书出版商的图书数量很多, 则此数据模型将导致可变的、不断增长的数组 books,如下所示:
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [123456789, 234567890, …]
}
{
_id: 123456789,
title: "MongoDE: The Definitive Guide",
author: ["Kristina Chodorow", "Mike Dirolf"],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
}
为了避免可变的、不断增长的数组,可以将出版商引用存放到图书文档中,如下所示:
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guiden,
author: [ "Kristina Chodorow", "Mike Dirolf"],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
键值对
文档数据库存储结构的基本单位是键值对,具体包含数据和类型。键值对的数据包含键和值,键的格式一般为字符串,值的格式可以包含字符串、数值、数组、文档等类型。
按照键值对的复杂程度,可以将键值对分为基本键值对和嵌套键值对。
- 图 4 中的键值对中的键为字符串,值为基本类型,这种键值对就称为基本键值。
- 嵌套键值对类型如图 5 所示,从图中可以看岀, contact 的键对应的值为一个文档,文档中又包含了相关的键值对,这种类型的键值对称为嵌套键值对。
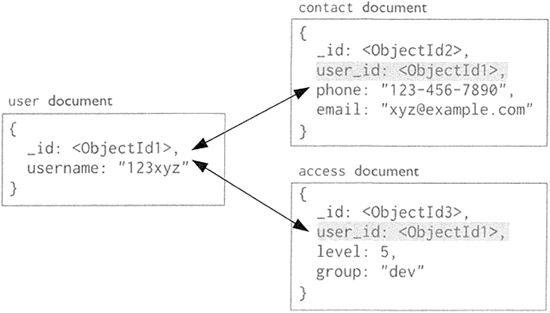
图4:MongoDB 文档数据模型
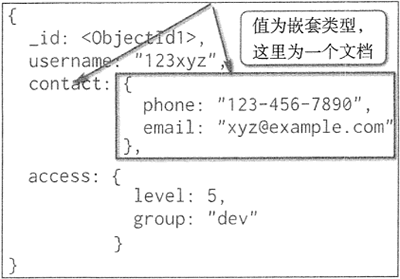
图 5:嵌套键值对
键(Key)起唯一索引的作用,确保一个键值结构里数据记录的唯一性,同时也具有信息记录的作用。例如,country:"China",用:实现了对一条地址的分割记录,“country”起到了 “China”的唯一地址作用,另外,“country”作为键的内容说明了所对应内容的一些信息。
值(Value)是键所对应的数据,其内容通过键来获取,可存储任何类型的数据,甚至可以为空。
键和值的组成就构成了键值对(Key-Value Pair)。它们之间的关系是一一对应的,如定义了 “country:China”键值对,"country”就只能对应“China”,而不能对应“USA”。
文档中键的命名规则如下。
- UTF-8 格式字符串。
- 不用有
\0的字符串,习惯上不用.和$。 - 以开头的多为保留键,自定义时一般不以开头。
- 文档键值对是有序的,MongoDB 中严格区分大小写。
原文引用:http://c.biancheng.net/view/6545.html
MongoDB_文档存储结构(三)的更多相关文章
- MFC单文档程序结构
MFC单文档程序结构三方面: Doc MainFrame View
- NoSQL生态系统——类似Bigtable列存储,或者Dynamo的key存储(kv存储如BDB,结构化存储如redis,文档存储如mongoDB)
摘自:http://www.ituring.com.cn/article/4002# NoSQL系统的数据操作接口应该是非SQL类型的.但在NoSQL社区,NoSQL被赋予了更具有包容性的含义,其意为 ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- MFC文档视图结构学习笔记
文档/视图概述 为了统一和简化数据处理方法,Microsoft公司在MFC中提出了文档/视图结构的概念,其产品Word就是典型的文档/视图结构应用程序 MFC通过其文档类和视图类提供了大量有关数据处理 ...
- ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的. 路由 首先,我们需要明白,文档和分片之间是如何匹配 ...
- HTML介绍、文档基本结构、meta标签、HTML标记的语法
一.HTML的介绍 Hyper Text Mark-up Language 超文本标记语言,是一种描述性标记语言(不是编程语言),主要用于描述网页(可以有图像,文字,声音,等..)但没有交互性 HTM ...
- ElasticSearch文档及分布式文档存储
1.什么是文档? 文档由索引(_index),类型(_type),唯一标识(_id) 组成,我们为 _index(索引) 分配相关逻辑地址分片,该索引下的数据会根据索引以及类型计算哈希来分配数据存储的 ...
- ElasticSearch文档操作介绍三
ElasticSearch文档的操作 文档存储位置的计算公式: shard = hash(routing) % number_of_primary_shards 上面公式中,routing 是一个可变 ...
- MFC用串行化实现文档存储和读取功能
在面向对象的程序设计中,一般都是用二进制文件来保存文档资料.在VC++中控制和使用文件流的方法很多,MFC程序设计中常用的有两种方法:用CFile对象存储和读取文件:利用串行化存取文件.其中用CFil ...
随机推荐
- 通过DT10获取程序执行过程中的实时覆盖率
DT10是新一代的动态测试工具,可以长时间跟踪记录目标程序执行情况,获取目标程序动态执行数据,帮助进行难于重现的Bug错误分析,覆盖率检测,性能测试,变量跟踪等等功能. 系统测试覆盖率,通常是用于判断 ...
- 【JAVA今法修真】 第三章 关系非关系 redis法器
您好,我是南橘,万法仙门的掌门,刚刚从九州世界穿越到地球,因为时空乱流的影响导致我的法力全失,现在不得不通过这个平台向广大修真天才们借去力量.你们的每一个点赞,每一个关注都是让我回到九州世界的助力,兄 ...
- Mongodb安全防护
1.Mongodb未授权访问 描述 MongoDB 是一个基于分布式文件存储的数据库.默认情况下启动服务存在未授权访问风险,用户可以远程访问数据库,无需认证连接数据库并对数据库进行任意操作,存在严重的 ...
- Mysql配置文件 基本设置
[mysqld] #MySQL启动用户 user = mysql #设置mysql的安装目录 basedir=/usr/local/mysql #mysql.sock存放目录 socket=/var/ ...
- 【Azure Redis 缓存】Azure Cache for Redis 中如何快速查看慢指令情况(Slowlogs)
问题描述 当 Azure Redis 服务器负载过高的情况下,使用时就会遇见连接超时,命令超时,IO Socket超时等异常.为了能定位是那些因素引起的,可以参考微软官方文档( 管理 Azure Ca ...
- Asp.Net Core基础篇之:白话管道中间件
在Asp.Net Core中,管道往往伴随着请求一起出现.客户端发起Http请求,服务端去响应这个请求,之间的过程都在管道内进行. 举一个生活中比较常见的例子:旅游景区. 我们都知道,有些景区大门离景 ...
- js控制滚动条在最底部位置
window.scrollTo(0, document.body.scrollHeight) 如果需要始终保持在最底部,可以循环调用该方法 如果是div的 /*滚动条到地步*/ function to ...
- 【Android开发】找乐,一个笑话App的制作过程记录
缘起 想做一个笑话App的原因是因为在知乎上看过一个帖子,做Android可以有哪些数据可以练手,里面推荐了几个数据开放平台.在这些平台中无一不是有公共的笑话接口,当时心想这个可以拿来练手啊,还挺有意 ...
- 【LeetCode】726. Number of Atoms 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/number-o ...
- Docker 与 K8S学习笔记(七)—— 容器的网络
本节我们来看看Docker网络,我们这里主要讨论单机docker上的网络.当docker安装后,会自动在服务器中创建三种网络:none.host和bridge,接下来我们分别了解下这三种网络: $ s ...