pandas 取 groupby 后每个分组的前 N 行
原始数据如下:
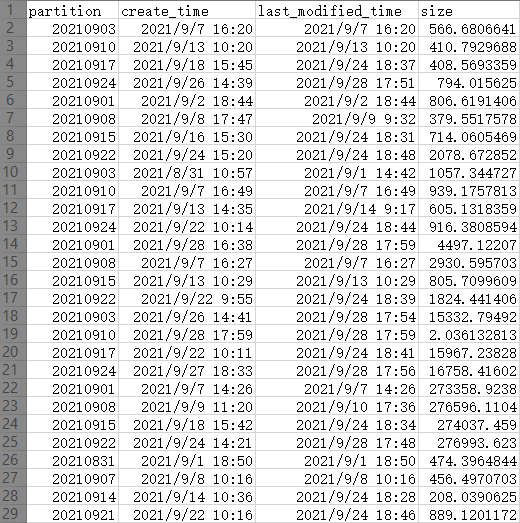
(图是从 excel 截的,最左1行不是数据,是 excel 自带的行号,为了方便说明截进来的)
除去首行是标题外,有效数据为 28行 x 4列
目前的需求是根据 partition 分组,然后取每组的前 2 行,如果不考虑排序,代码如下:
(把head()里面的数字改成 n 就可以取 n 行)
import pandas as pd
esp_df = pd.read_excel('excel文件路径', sheet_name='Sheet名')
esp_df.groupby(['partition', 'create_time', 'last_modified_time']).mean().reset_index(drop=False).groupby('partition').head(2)
结果如下:
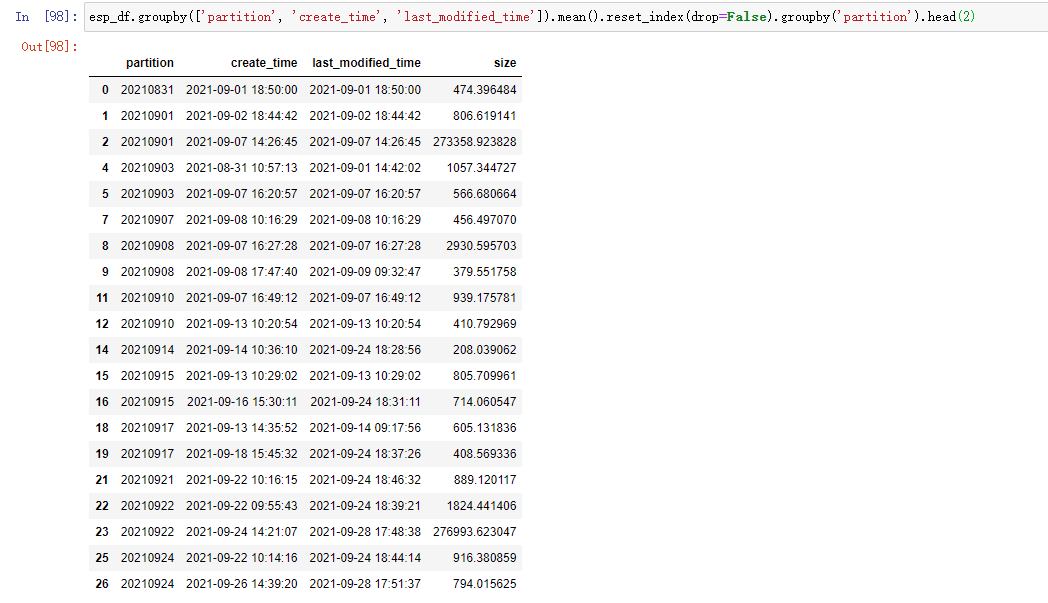
分别说明如下:
- groupby:分组,这里是根据数据中的 3 列来一起分组,因为我们并不需要做聚合运算,所以这么取可以保留原始数据不变。原始数据只有 4 列,这里 groupby 了 3 列,只剩下 size(其实把 size 放进去一起 groupby 也没问题)
- mean:求平均值,但是在这里没用,因为上一步的 groupby 取了前面的 3 列,在本例中,前 3 列并在一起就能得到一个唯一的一行,所以这里其实也只是每一行数据自己求平均数,结果等于它本身。同理,这里替代成求和函数
sum()也是一样的。但是不能省略,因为**省略后它就是一个DataFrameGroupBy类型的变量,不是DataFrame,而DataFrameGroupBy是没有后面的reset_index方法的 - reset_index:重置索引,groupby 之后,结果集的索引就变成了 groupby 里面的 key,这个
reset_index把这个索引重新退回为数据。
举例说明,在应用reset_index之前,即使用mean()之后的数据是这样的:

可以看到左边的 3 列,也就是 groupby key 的 partition、create_time、last_modified_time 是加粗了的,说明此时这 3 列都是索引;而且 partition 因为有相同的行,还被合并了。显然这不是我们想要的。reset_index 把它们重新放回到数据列里

参数中的 drop 作用是是否保留(重置前)的索引
数据就又回来了,索引变成了原来默认的(0123...)
- groupby:再次根据 partition 分组
- head: 取每个分组的前 n 行
如果要排序
本例中,如果要先根据 partition 分组,然后再根据 size 倒序(从大到小)再取前 2 行,则代码如下:
esp_df.groupby(['partition']).apply(lambda x: x.sort_values(["size"], ascending = False)).reset_index(drop=True).groupby('partition').head(2)
结果如下:

pandas 取 groupby 后每个分组的前 N 行的更多相关文章
- 第十三节:pandas之groupby()分组
1.Series()对象分组 1.1.单级索引 1.2.多级索引 2.DataFrame()对象分组 3.获取一个分组,遍历分组,filter过滤.
- pandas之groupby分组与pivot_table透视
一.groupby 类似excel的数据透视表,一般是按照行进行分组,使用方法如下. df.groupby(by=None, axis=0, level=None, as_index=True, so ...
- sql-实现select取行号、分组后在分组内排序、每个分组中的前n条数据
表结构设计: 实现select取行号 sql局部变量的2种方式 set @name='cm3333f'; select @id:=1; 区别:set 可以用=号赋值,而select 不行,必须使用:= ...
- pandas获取groupby分组里最大值所在的行,获取第一个等操作
pandas获取groupby分组里最大值所在的行 10/May 2016 python pandas pandas获取groupby分组里最大值所在的行 如下面这个DataFrame,按照Mt分组, ...
- Pandas之groupby分组
释义 groupby用来分组,调用groupby 之后返回pandas.core.groupby.generic.DataFrameGroupBy,其实就是由一个个格式为(key, 分组后的dataf ...
- sql server 分组,取每组的前几行数据
sql中group by后,获取每组中的前N行数据,目前我知道的有2种方法 比如有个成绩表: 里面有字段学生ID,科目,成绩.我现在想取每个科目的头三名. 1. 子查询 select * from ...
- mysql分组取最大(最小、最新、前N条)条记录
在数据库开发过程中,我们要为每种类型的数据取出前几条记录,或者是取最新.最小.最大等等,这个该如何实现呢,本文章向大家介绍如何实现mysql分组取最大(最小.最新.前N条)条记录.需要的可以参考一下. ...
- pandas之groupby分组与pivot_table透视表
zhuanzi: https://blog.csdn.net/qq_33689414/article/details/78973267 pandas之groupby分组与pivot_table透视表 ...
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
随机推荐
- TCP可靠传输原理
停止等待协议 "停止等待"就是发送方在发送完一个分组后停止发送,等待接收方的确认后再继续发送. 超时重传 发送方在等待一定时间后如果还没有收到接收方的确认,此时发送方将认定分组没有 ...
- python获取邮件信息
在项目的Terminal中注册模块pypiwin32 python -m pip install pypiwin32 import win32com.client outlook = win32com ...
- AntDesign VUE:上传组件图片/视频宽高、文件大小、image/video/pdf文件类型等限制(Promise、Boolean)
文件大小限制 - Promise checkFileSize(file, rules) { return new Promise((resolve, reject) => { file.size ...
- shell编程之条件语句
目录: 一.条件测试 1.test命令测试 2.文件测试 3.字符串比较 4.逻辑测试 二.if语句 1.if单分支语句 2.if双分支语句 3.if多分支语句 三.case语句 case多分支语句 ...
- 【Nginx】Linux常用命令------启动、停止、重启
启动 启动代码格式:nginx安装目录地址 -c nginx配置文件地址 例如: [root@LinuxServer sbin]# /usr/local/nginx/sbin/nginx -c /us ...
- python中字符串的各种方法
图片来源见水印,一个学python的公众号
- 物理机burp抓虚拟机包
先设置网络连接为NAT模式. 这就相当于主机虚拟出一个网卡,虚拟机单独成为一个网段(相当于虚拟机为单独一台主机,物理机作为路由器网关使用),我将会在物理机,也就是这个"路由器"上设 ...
- hadoop集群搭建详细教程
本文针对hadoop集群的搭建过程给予一个详细的介绍. 参考视频教程:https://www.bilibili.com/video/BV1tz4y127hX?p=1&share_medium= ...
- android开发使用jxl创建Excel
这周水了几天,今天把博客赶上,找找状态. 周五的时候终于完成了课堂测试第二阶段,主要的难点就是生成Excel表并将填写的数据插入到Excel表中. 一.jxl使用 1.创建或读取一个工作薄 Workb ...
- PHP中的日期相关函数(二)
上回文章中我们介绍了三个时间日期相关的对象,不过它们的出镜频率并不是特别地高.今天学习的对象虽说可能不少人使用过,但是它的出镜频率也是非常低的.它们其实就是我们非常常用的那些面向过程的日期函数的面向对 ...