ELK集群之filebeat(6)
filebeat工作原理
ilebeat是本地文件的日志数据采集器。 作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,tail file,并将它们转发给Elasticsearch或Logstash进行索引、kafka 等。
filebeat单纯采集如果logstash sprunk plume等运行业务节点直接采集处理在数据量大时很容易消耗较多资源,业务节点应该采用单纯的采集工具到后端去处理,如filebeat FluentBit logtail等只做采集处理。
工作原理:
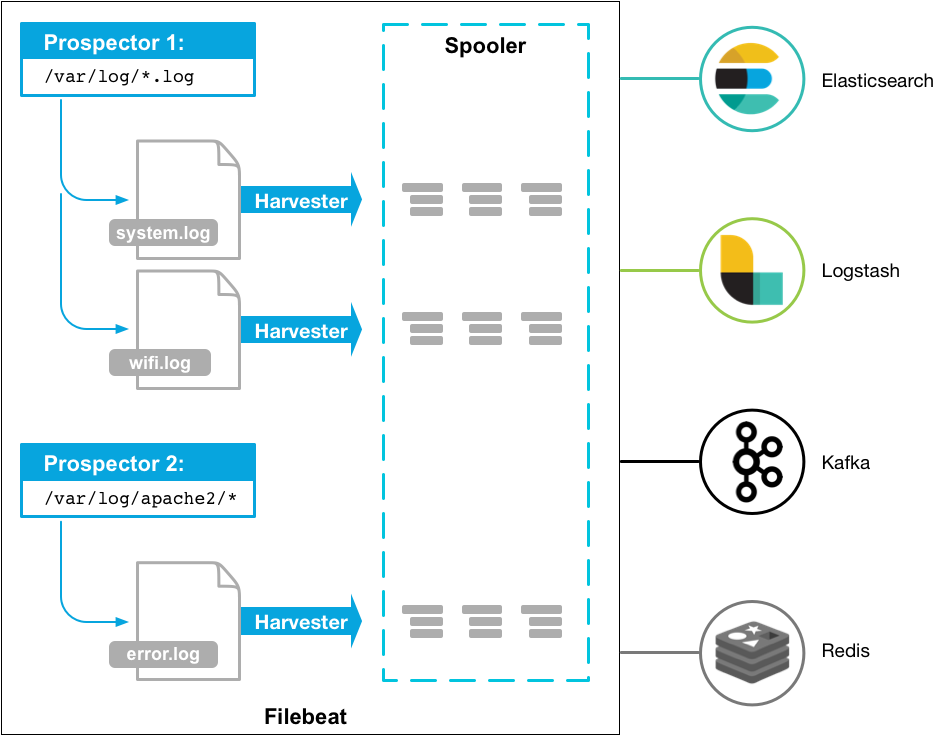
Filebeat由两个主要组件组成:prospector 和harvester。这些组件一起工作来读取文件(tail file)并将事件数据发送到您指定的输出
启动Filebeat时,它会启动一个或多个查找器,查看您为日志文件指定的本地路径。 对于prospector 所在的每个日志文件,prospector 启动harvester。 每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到您为Filebeat配置的输出。
harvester
harvester :负责读取单个文件的内容。读取每个文件,并将内容发送到 the output
每个文件启动一个harvester, harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态
如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
这有副作用,即在harvester关闭之前,磁盘上的空间被保留。默认情况下,Filebeat将文件保持打开状态,直到达到close_inactive状态
关闭harvester会产生以下结果:
1)如果在harvester仍在读取文件时文件被删除,则关闭文件句柄,释放底层资源。
2)文件的采集只会在scan_frequency过后重新开始。
3)如果在harvester关闭的情况下移动或移除文件,则不会继续处理文件。
要控制收割机何时关闭,请使用close_ *配置选项
prospector
prospector 负责管理harvester并找到所有要读取的文件来源。
如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
每个prospector都在自己的Go协程中运行。
以下示例将Filebeat配置为从与指定的匹配的所有日志文件中收集行:
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.log
Filebeat目前支持两种prospector类型:log和stdin。
每个prospector类型可以定义多次。
日志prospector检查每个文件以查看harvester是否需要启动,是否已经运行,
或者该文件是否可以被忽略(请参阅ignore_older)。
只有在harvester关闭后文件的大小发生了变化,才会读取到新行。
注:Filebeat prospector只能读取本地文件, 没有功能可以连接到远程主机来读取存储的文件或日志。
Filebeat如何保持文件的状态?
Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,
当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
每个prospector为它找到的每个文件保留一个状态。
由于文件可以被重命名或移动,因此文件名和路径不足以识别文件。
对于每个文件,Filebeat存储唯一标识符以检测文件是否先前已采集过。
如果您的使用案例涉及每天创建大量新文件,您可能会发现注册文件增长过大。请参阅注册表文件太大?编辑有关您可以设置以解决此问题的配置选项的详细信息。
Filebeat如何确保至少一次交付
Filebeat保证事件至少会被传送到配置的输出一次,并且不会丢失数据。 Filebeat能够实现此行为,因为它将每个事件的传递状态存储在注册文件中。
在输出阻塞或未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到接收端确认已收到。
如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有收到事件。
发送到输出但在Filebeat关闭前未确认的任何事件在重新启动Filebeat时会再次发送。
这可以确保每个事件至少发送一次,但最终会将重复事件发送到输出。
也可以通过设置shutdown_timeout选项来配置Filebeat以在关闭之前等待特定时间。
注意:
Filebeat的至少一次交付保证包括日志轮换和删除旧文件的限制。如果将日志文件写入磁盘并且写入速度超过Filebeat可以处理的速度,或者在输出不可用时删除了文件,则可能会丢失数据。
在Linux上,Filebeat也可能因inode重用而跳过行。有关inode重用问题的更多详细信息,请参阅filebeat常见问题解答。
filebeat安装使用:


ilebeat轻量客户端的引入
不需要使用正则的时候
可直接用filebeat发送日志给es,用得比较少
用得比较多filebeat -> Logstash做一些日志的分析提取 Filebeat的二进制安装
yum localinstall filebeat-7.6.2-x86_64.rpm -y 先创建索引模板,不然filebeat创建的索引模板无用内容较多
PUT _template/sjgtemplate
{
"index_patterns": ["sjg*"],
"settings":{
"number_of_shards": 2,
"number_of_replicas": 0
}
}
filebeat安装设置模板
Filebeat发送日志到ES配置filebeat.yml
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure processors:
- drop_fields:
fields: ["agent","ecs","input"] output:
elasticsearch:
hosts: ["192.168.238.90:9200", "192.168.238.92:9200"]
username: elastic
password: sjgpwd
index: "sjgfb-secure-%{+YYYY.MM.dd}" setup.template.name: "sjgtemplate"
setup.template.pattern: "sjg*"
setup.ilm.enabled: false
filebeat发送采集信息到es
Filebeat+Logstash实现日志的分析处理
logstash配置监听在5044,Filebeat把日志发送Logstash
input {
beats {
host => '0.0.0.0'
port => 5044
}
} Filebeat发送到Logstash
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure processors:
- drop_fields:
fields: ["agent","ecs","log","input"] output:
logstash:
hosts: ["192.168.238.90:5044"]
filebeat发送日志到logstash
Filebeat多行日志分析-Mysql慢日志
分析Mysql慢日志
cat <<EOF >>/var/log/mysql-slow
# Time: 210725 14:40:11
# User@Host: root[root] @ [127.0.0.1] Id: 15
# Query_time: 1.716442 Lock_time: 0.000069 Rows_sent: 0 Rows_examined: 461120
use zabbix;
SET timestamp=1589268946;
select count(1) from history;
# Time: 210725 14:33:15
# User@Host: root[root] @ [127.0.0.1] Id: 21
# Query_time: 6.759307 Lock_time: 2.000038 Rows_sent: 0 Rows_examined: 3307868
SET timestamp=1589269067;
select count(1) from history;
# Time: 210725 14:33:17
# User@Host: root[root] @ [127.0.0.1] Id: 21
# Query_time: 8.759307 Lock_time: 1.000038 Rows_sent: 0 Rows_examined: 3307868
SET timestamp=1589269067;
select count(1) from history;
EOF Filebeat多行日志分析-先输出文件
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/mysql-slow
multiline:
pattern: '^# Time: \d+ \d+:\d+:\d+' #提取多行日志以time开头
negate: true
match: after processors:
- drop_fields:
fields: ["agent","ecs","log","input"] #过滤不需要内容 output.file:
path: "/tmp/filebeat"
filename: filebeat
filebeat分析mysql慢日志
Logstash提取Mysql慢日志-多行提取
logstash正则提取多行日志,使用kibana的grok工具一步步提取
# Time: (?<timestamp>\d+ \d+:\d+:\d+)\s+# User@Host: %{WORD}\[%{WORD:remote_user}\]\s+@\s+\[%{IP:remote_ip}\].*\s+# Query_time:\s+%{NUMBER:query_time}\s+Lock_time:\s+%{NUMBER:lock_time}\s+Rows_sent: %{NUMBER:rows_sent}\s+Rows_examined: %{NUMBER:rows_examined}(?<runsql>(\s+.*)+) timestamp时间覆盖
match => ["timestamp", "yyMMdd HH:mm:ss"] 索引名字更改
index => "sjgslow-%{+YYYY.MM.dd}" Filebeat发送到logstah实现多行日志分析正则提取
output:
logstash:
hosts: ["192.168.238.90:5044"]
logstash正则处理mysql慢日志
Filebeat读取tomcat多行错误日志
日志模板
cat <<EOF >>/var/log/tomcat
25-Jul-2021 14:50:41.950 INFO [localhost-startStop-1] org.apache.catalina.core.ApplicationContext.log SessionListener: contextInitialized()
25-Jul-2021 13:51:45.954 INFO [localhost-startStop-1] org.apache.catalina.core.ApplicationContext.log ContextListener: attributeAdded('StockTicker', 'async.Stockticker@5b24dcf6')
25-Jul-2021 20:15:47.959 SEVERE [http-nio-8080-exec-1] org.apache.catalina.core.StandardWrapperValve.invoke Servlet.service() for servlet [jsp] in context with path [/sjg] threw exception [java.lang.ArithmeticException: / by zero] with root cause
at org.apache.jsp.sjg_jsp._jspService(sjg_jsp.java:110)
at org.apache.jasper.runtime.HttpJspBase.service(HttpJspBase.java:71)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:741)
at org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:476)
at org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:386)
EOF Filebeat提取多行日志看是否正常07-Aug-2020 16:25:40.952
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/tomcat
multiline:
pattern: '^\d+-[a-zA-Z]+-\d+ \d+:\d+:\d+.\d+'
negate: true
match: after processors:
- drop_fields:
fields: ["agent","ecs","log","input"] output.file:
path: "/tmp/filebeat"
filename: filebeat Logstash正则提取Tomcat错误日志-多行
logstash正则提取多行日志
(?<timestamp>\d+-[a-zA-Z]+-\d+ \d+:\d+:\d+.\d+) %{NOTSPACE:loglevel} %{NOTSPACE:thread}(?<loginfo>(\s+.*)+) timestamp时间覆盖22-Jun-2020 15:31:14.428
match => ["timestamp", "dd-MMM-yyyy HH:mm:ss.SSS"] 索引名字更改
index => "sjgtomcat-%{+YYYY.MM.dd}" Filebeat发送到logstash分析
output:
logstash:
hosts: ["192.168.238.90:5044"]
filebeat+logstash分析tomcat错误日志
Filebeat分析指定的日志内容
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure processors:
- drop_fields:
fields: ["agent","ecs","log","input"]
- drop_event:
when:
contains:
message: "session" output.file:
path: "/tmp/filebeat"
filename: filebeat
filebeat去除无用日志
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure
processors:
- drop_fields:
fields: ["agent","ecs","log","input"]
- drop_event:
when:
regexp:
message: "session|polkitd"
output.file:
path: "/tmp/filebeat"
filename: filebeat
filebeat去除无用日志-采用正则
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure processors:
- drop_fields:
fields: ["agent","ecs","log","input"]
- drop_event:
when:
not:
contains:
message: "password" output.file:
path: "/tmp/filebeat"
filename: filebeat
filebeat指定日志分析-保留有用内容
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure processors:
- drop_fields:
fields: ["agent","ecs","log","input"]
- drop_event:
when:
not:
regexp:
message: "password|session" output.file:
path: "/tmp/filebeat"
filename: filebeat
filebeat指定日志分析-保留有用内容-采用正则
filebeat分析日志输出到es
Filebeat分析指定日志输到ES
系统日志需要配置带年份的 Logstash配置提取系统日志
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:timestamp} %{NOTSPACE} %{NOTSPACE:procinfo}: (?<secinfo>.*)'
}
remove_field => ["message"]
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
}
mutate {
remove_field => ["timestamp"]
}
}
output {
elasticsearch {
hosts => ["http://192.168.238.90:9200", "http://192.168.238.92:9200"]
user => "elastic"
password => "sjgpwd"
index => "sjgsecure-%{+YYYY.MM.dd}"
}
} filebeat发送给logstash分析
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure processors:
- drop_fields:
fields: ["agent","ecs","log","input"]
- drop_event:
when:
not:
contains:
message: "password"
output:
logstash:
hosts: ["192.168.238.90:5044"]
采集系统日志输出到es
Filebeat采集多个日志应用
采集多个日志
一台服务器采集多个日志的需求
可针对不同的日志去做不同的提取,使用不同的索引 Filebeat采集多个日志输出到文件
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/nginx/access.log
fields:
type: access
fields_under_root: true - type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure
fields:
type: system
fields_under_root: true processors:
- drop_fields:
fields: ["agent","ecs","log","input"] output.file:
path: "/tmp/filebeat"
filename: filebeat Logstash通过type字段进行判断
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
if [type] == "access" {
grok {
match => {
"message" => '%{IP:remote_addr} - (%{WORD:remote_user}|-) \[%{HTTPDATE:time_local}\] "%{WORD:method} %{NOTSPACE:request} HTTP/%{NUMBER}" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS} %{QS:http_user_agent}'
}
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
else if [type] == "system" {
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["http://192.168.238.90:9200", "http://192.168.238.92:9200"]
user => "elastic"
password => "sjgpwd"
index => "sjgaccess-%{+YYYY.MM.dd}"
}
}
else if [type] == "system" {
elasticsearch {
hosts => ["http://192.168.238.90:9200", "http://192.168.238.92:9200"]
user => "elastic"
password => "sjgpwd"
index => "sjgsystem-%{+YYYY.MM.dd}"
}
}
} 发送给logstash分析
output:
logstash:
hosts: ["xxx:5044"]
filebeat采集多个日志发送es
Filebeat采集Json格式的日志
elk分析json格式的日志 Json格式日志直接采集
log_format json '{"@timestamp":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"status":$status,'
'"body_bytes_sent":$body_bytes_sent,'
'"http_referer":"$http_referer",'
'"http_user_agent":"$http_user_agent",'
'"request_time":$request_time,'
'"request":"$uri"}';
access_log /var/log/nginx/access.json.log json; Filebeat采集Json格式的日志
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/nginx/access.json.log processors:
- drop_fields:
fields: ["agent","ecs","log","input"] output.file:
path: "/tmp/filebeat"
filename: filebeat Logstash解析Json日志
input {
beats {
host => '0.0.0.0'
port => 5044
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["http://192.168.238.90:9200", "http://192.168.238.92:9200"]
user => "elastic"
password => "sjgpwd"
index => "sjgjson-%{+YYYY.MM.dd}"
}
} 发送到logstash
output:
logstash:
hosts: ["192.168.238.90:5044"]
filebeat采集json日志发送logstash
filebeat采集多个日志发送kafka
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/secure
fields:
type: system
fields_under_root: true - type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/nginx/access.log
fields:
type: nginx
fields_under_root: true - type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/tomcat
fields:
type: tomcat
fields_under_root: true
multiline:
pattern: '^\d+-[a-zA-Z]+-\d+ \d+:\d+:\d+.\d+'
negate: true
match: after - type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/mysql-slow
fields:
type: mysql
fields_under_root: true
multiline:
pattern: '^# Time: \d+ \d+:\d+:\d+'
negate: true
match: after processors:
- drop_fields:
fields: ["agent","ecs","input","ecs","log"]
- drop_event:
when:
regexp:
message: "session|polkitd"
output:
kafka:
hosts: ["172.17.166.217:9092", "172.17.166.218:9092", "172.17.166.219:9092"]
topic: sjg
filebeat采集日志发送kafka
ELK集群之filebeat(6)的更多相关文章
- Zookeeper、Kafka集群与Filebeat+Kafka+ELK架构
Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 目录 Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 一.Zookeeper 1. Zook ...
- Filebeat-1.3.1安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)(以Console Output为例)
前期博客 Filebeat的下载(图文讲解) 前提 Elasticsearch-2.4.3的下载(图文详解) Elasticsearch-2.4.3的单节点安装(多种方式图文详解) Elasticse ...
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- 实战之elasticsearch集群及filebeat server和logstash server
author:JevonWei 版权声明:原创作品 实战之elasticsearch集群及filebeat server和logstash server 环境 elasticsearch集群节点环境为 ...
- Centos7中ELK集群安装流程
Centos7中ELK集群安装流程 说明:三个版本必须相同,这里安装5.1版. 一.安装Elasticsearch5.1 hostnamectl set-hostname elk vim /e ...
- ansible playbook部署ELK集群系统
一.介绍 总共4台机器,分别为 192.168.1.99 192.168.1.100 192.168.1.210 192.168.1.211 服务所在机器为: redis:192.168.1.211 ...
- Kibana安装(图文详解)(多节点的ELK集群安装在一个节点就好)
对于Kibana ,我们知道,是Elasticsearch/Logstash/Kibana的必不可少成员. 前提: Elasticsearch-2.4.3的下载(图文详解) Elasticsearch ...
- elasticsearch集群及filebeat server和logstash server
elasticsearch集群及filebeat server和logstash server author:JevonWei版权声明:原创作品blog:http://119.23.52.191/ 实 ...
- elk集群配置配置文件中节点数配多少
配置elk集群时,遇到,elasticsearch配置文件中的一个配置discovery.zen.minimum_master_nodes: 2.这里是三配的2 看到某一位的解释是这样:为了避免脑裂, ...
随机推荐
- [手机编程]Aid Learning--换源+数据库安装
换源+MYSQL安装 Aid Learning下载安装 http://www.aidlearning.net/ 切换源 打开Terminal复制回车即可 cd /etc/apt/&& ...
- 微信小程序自动化测试
使用官方工具 使用webview测试方法,当2019年被微信封禁 使用native定位
- web自动化:IE11运行Python+selenium程序
from selenium import webdriver # 运行此脚本前必须按要求修改注册表'''[HKEY_CURRENT_USER\Software\Microsoft\Internet E ...
- 解决Windows 游戏 错误代码 1170000
安装"Xbox标识提供程序" 下载地址:https://www.microsoft.com/store/apps/9wzdncrd1hkw
- 《手把手教你》系列技巧篇(二十七)-java+ selenium自动化测试- quit和close的区别(详解教程)
1.简介 尽管有的小伙伴或者童鞋们觉得很简单,不就是关闭退出浏览器,但是宏哥还是把两个方法的区别说一下,不然遇到坑后根本不会想到是这里的问题. 2.源码 本文介绍webdriver中关于浏览器退出操作 ...
- AT4996-[AGC034F]RNG and XOR【FWT,生成函数】
正题 题目链接:https://www.luogu.com.cn/problem/AT4996 题目大意 给出一个\(0\sim 2^n-1\)下标的数组\(p\),\(p_i\)表示有\(p_i\) ...
- Mysql集群搭建(多实例、主从)
1 MySQL多实例 一 .MySQL多实例介绍 1.什么是MySQL多实例 MySQL多实例就是在一台机器上开启多个不同的服务端口(如:3306,3307,3308),运行多个MySQL服务进程,通 ...
- LINUX系统入侵排查
当企业发生黑客入侵.系统崩溃或其它影响业务正常运行的安全事件时,急需第一时间进行处理,使企业的网络信息系统在最短时间内恢复正常工作,进一步查找入侵来源,还原入侵事故过程,同时给出解决方案与防范措施,为 ...
- 从源码分析node-gyp指定node库文件下载地址
当我们安装node的C/C++原生模块时,涉及到使用node-gyp对C/C++原生模块的编译工作(configure.build).这个过程,需要nodejs的头文件以及静态库参与(后续称库文件)对 ...
- Serverless 的价值
作者 | 许晓斌 阿里云高级技术专家 本文整理自<Serverless 技术公开课>,关注"Serverless"公众号,回复 入门 ,即可获取 Serverless ...