python3抓取异步百度瀑布流动态图片(一)查找post并伪装头方法
打开流程:
用火狐打开百度图片-->打开firebug-->输入GIF图-->搜索-->点击网络-->全部
观察页面:
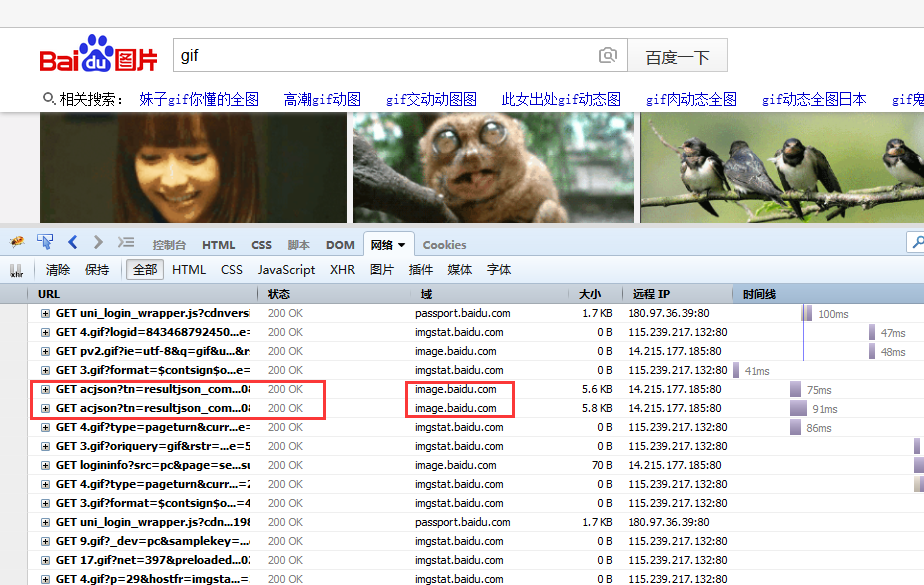
首先要观察的对象是“域”,图片的json一般是放在主要的“域”里面的,任何网站的主要的“域”就是自身,即百度图片的网址image.baidu.com,根据这个“域”我们再去查找URL。
查找方式:
点开“+”号,开打json,观察里面的json的图片网址:
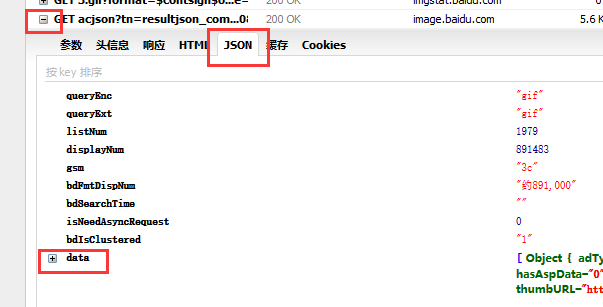
随便点开一个“data”得到一个图片网址:

在浏览器新的窗口里面打开这张图片看看是不是出现在百度图片里面的图片,图片打开时这个样子:

返回百度图片里面去查找:
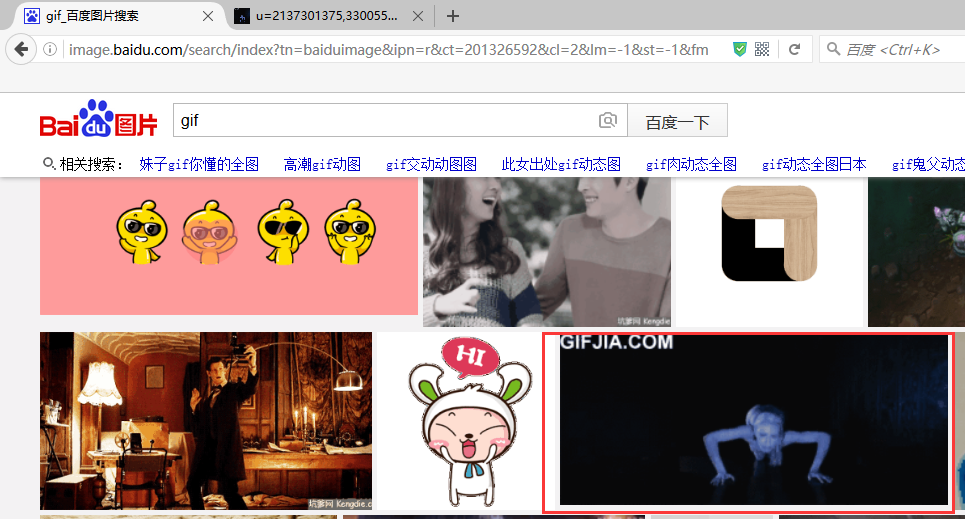
发现也在百度图片里面,那么这个url就是我们要找到的json了,返回去点击复制网址和参数下面的东西出来:
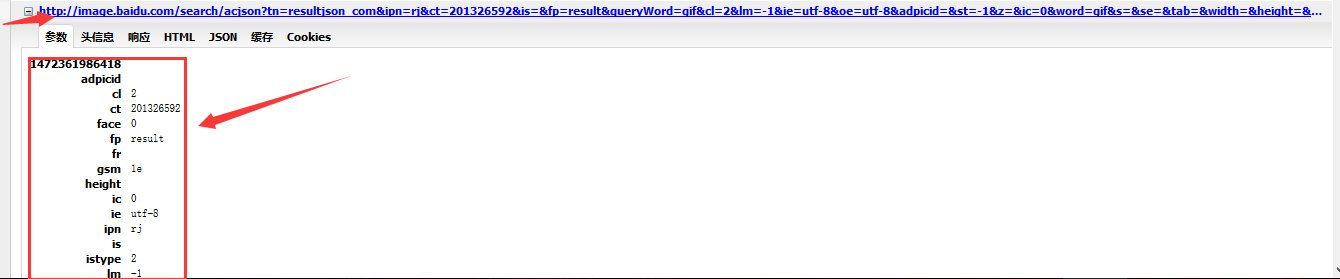
在txt里面观察:
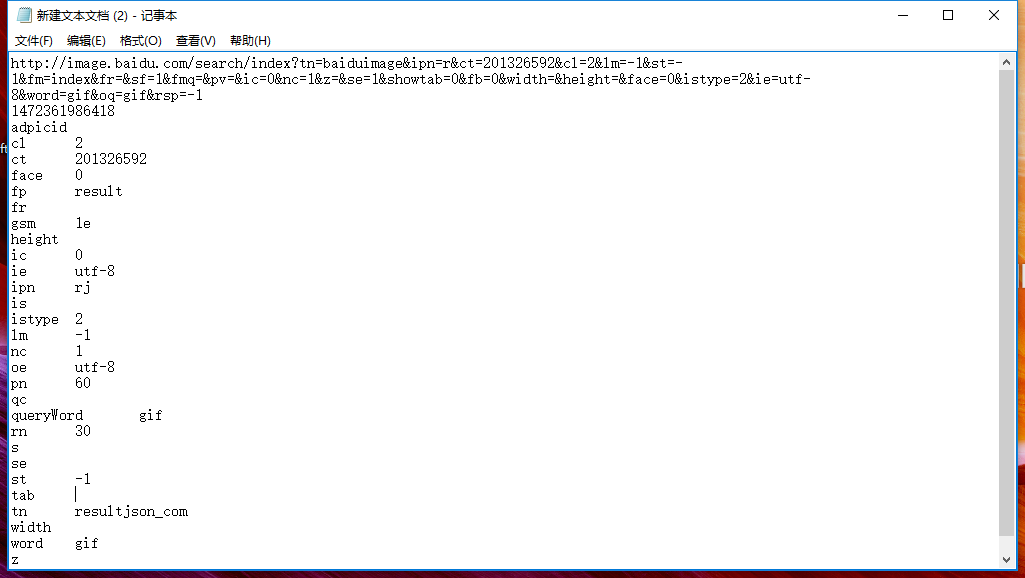
继续观察url,url包含了一大堆的参数,每一个&都固定了一个参数:
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=gif&oq=gif&rsp=-1
从头到尾看,tn、ipn、ct...
这些在参数里面都有显示,那么我们构造的网址就是:
http://image.baidu.com/search/index?tn...&ipn...&ct...&.....&.....
再去观察百度哪里是用get方式的,所以我们的python也应该用get方式:
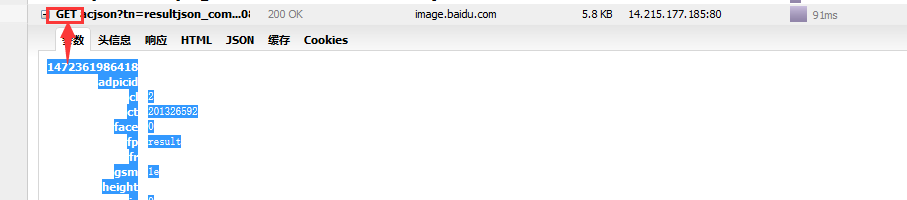
有些网址使用post的,那种方式在以后再去说
---------------------------------------我是快乐的分割线-----------------------------------------
url搞定,那么需要破解它的瀑布流。
浏览器往下拉,给百度图片加载下一个部分的url出来,下面这个是第二部分的url:
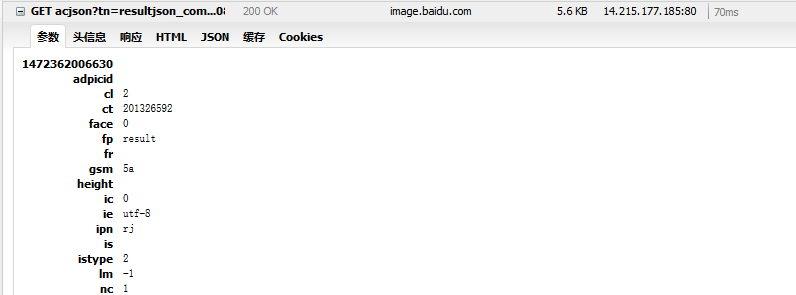
按照上面的方法观察json里面的data,得到的图片:

百度图片原文里面观察:
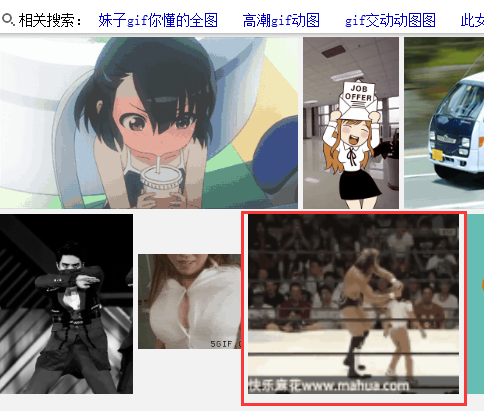
也是找到了这张图片,那么老规矩复制url和参数出来观察:
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=gif&oq=gif&rsp=-1 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=90&rn=30&gsm=5a&1472362006630=
1472361986418
URL不相同???
继续往下翻!!!
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=gif&oq=gif&rsp=-1 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=90&rn=30&gsm=5a&1472362006630=
1472361986418 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=150&rn=30&gsm=96&1472363883056=
后面两个网址有规律了,观察之...
看到没,pn!!!!!
一个pn是90一个是150,呵呵哒终于找到了,那么就要找到这个页数的规律。
刷新浏览器,直接翻到第11页:
然后把加载出来的那个特定的url全部复制到txt里面观察,下面我放了部分出来:
http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1472364207674= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=90&rn=30&gsm=5a&1472364212829= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=150&rn=30&gsm=96&1472364217002= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=210&rn=30&gsm=d2&1472364220585= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=270&rn=30&gsm=10e&1472364223842=
看到这里还要我多说明么:
pn=30
pn=90
pn=150
pn=210
pn=270
搞定了url,到时候写个for i in range(...),太强大,到这里构造的post就完成了
----------------------------------------------我是快乐的分割线--------------------------------------------------
伪装头部是很重要的,要防止被反爬虫、反反盗链等等,那么头部就是:
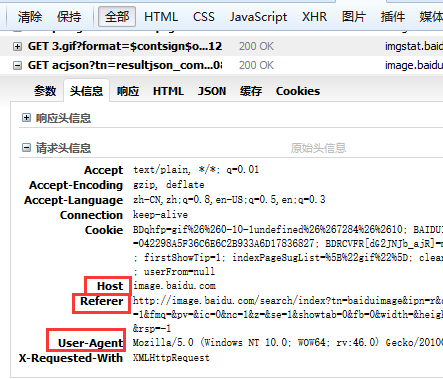
referer是反反盗链,ua是反爬虫,host是主链,这三个最重要,笔者曾经偷懒只写了ua,被反反盗链害死,得到的图片为:

假如你们抓到这样的图那么说明失败,第一篇幅搞定。
python3抓取异步百度瀑布流动态图片(一)查找post并伪装头方法的更多相关文章
- python3抓取异步百度瀑布流动态图片(二)get、json下载代码讲解
制作解析网址的get def gethtml(url,postdata): header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 【js】【图片瀑布流】js瀑布流显示图片20180315
js实现把图片用瀑布流显示,只需要“jquery-1.11.2.min.js”. js: //瀑布流显示图片 var WaterfallImg = { option: { maxWidth: 850, ...
- 利用wget 抓取 网站网页 包括css背景图片
利用wget 抓取 网站网页 包括css背景图片 wget是一款非常优秀的http/ftp下载工具,它功能强大,而且几乎所有的unix系统上都有.不过用它来dump比较现代的网站会有一个问题:不支持c ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- Python3抓取javascript生成的html网页
用urllib等抓取网页,只能读取网页的静态源文件,而抓不到由javascript生成的内容. 究其原因,是因为urllib是瞬时抓取,它不会等javascript的加载延迟,所以页面中由javasc ...
- python3抓取淘宝评论内容
好久没有写爬虫了,今天研究了下淘宝商品评论的内容. 一开始用最简单的方法,挂代理,加请求头,对网页请求,是抓不到数据的,在网上找了一些相关文章,也基本已经过时了,就是网站逻辑有改动,用旧的方法是抓不到 ...
- Python3 抓取豆瓣电影Top250
利用 requests 抓取豆瓣电影 Top 250: import re import requests def main(url): global num headers = {"Use ...
- java平台利用jsoup开发包,抓取优酷视频播放地址与图片地址等信息。
/******************************************************************************************** * aut ...
随机推荐
- IOS 使用block完成网络请求的自定义类BlockURLConnection
一,头文件 #import <Foundation/Foundation.h>//定义下载中block类型typedef void(^ProcessBlock) (NSURLRespons ...
- 【JOJO】真男人-坚不可摧
DIO,你输给我的原因只有一个! 那就是,你惹怒了我! http://www.bilibili.com/video/av461689/
- HDU 4004
http://acm.hdu.edu.cn/showproblem.php?pid=4004 题意:青蛙过长L的河,只能落在石头上,石头数量是n,给出n个坐标,至多跳m次,求在可以过河的条件下,青蛙跳 ...
- HDU 1811
http://acm.hdu.edu.cn/showproblem.php?pid=1811 中文码题 对于等号的情况,用并查集合并(因为编号不同一定可以分出先后) 然后判断能否构成拓扑排序,以及拓扑 ...
- Selenium Waits
Selenium高级功能包含查找等待, Selenium的查找等待有两种方式, 隐式等待(Implicit Waits)和显示等待(Explicit Waits): 这里写下我对两者的理解, 1. 隐 ...
- 解决spring配置中的bean类型的问题:BeanNotOfRequiredTypeException
解决spring配置中的bean类型的问题:BeanNotOfRequiredTypeException这个问题出现的原因:一般在使用annotation的方式注入spring的bean 出现的,具体 ...
- PM 时钟机制
PM 时钟机制 10.1 Minix3 PM 时钟机制概述在 MINIX3 中,除了前面所讲到的 CLOCK 时钟,在 pm 中也是维持了一个时钟, 我们暂且不分析为啥要这么做,我就分析是怎么实现这个 ...
- Think Python - Chapter 8 - Strings
8.1 A string is a sequenceA string is a sequence of characters. You can access the characters one at ...
- App_Code 引起的 ambiguously 问题
今天遇到了一个这样的问题,一个.net framework 4.0 的web application ,下面有一个App_Code文件夹,里面的一些公共类的build action 是 Compile ...
- js foreach比for多出两个undefined
项目中发现,javascript 用foreach会比for多出两个undefined, //会多两个undefined for (var i in _SysFunctions_S) {} //正常 ...