通过提示大语言模型进行个性化推荐LLM-Rec: Personalized Recommendation via Prompting Large Language Models
论文原文地址:https://arxiv.org/abs/2307.15780
本文提出了一种提示LLM并使用其生成的内容增强推荐系统的输入的方法,提高了个性化推荐的效果。
LLM-Rec Prompting
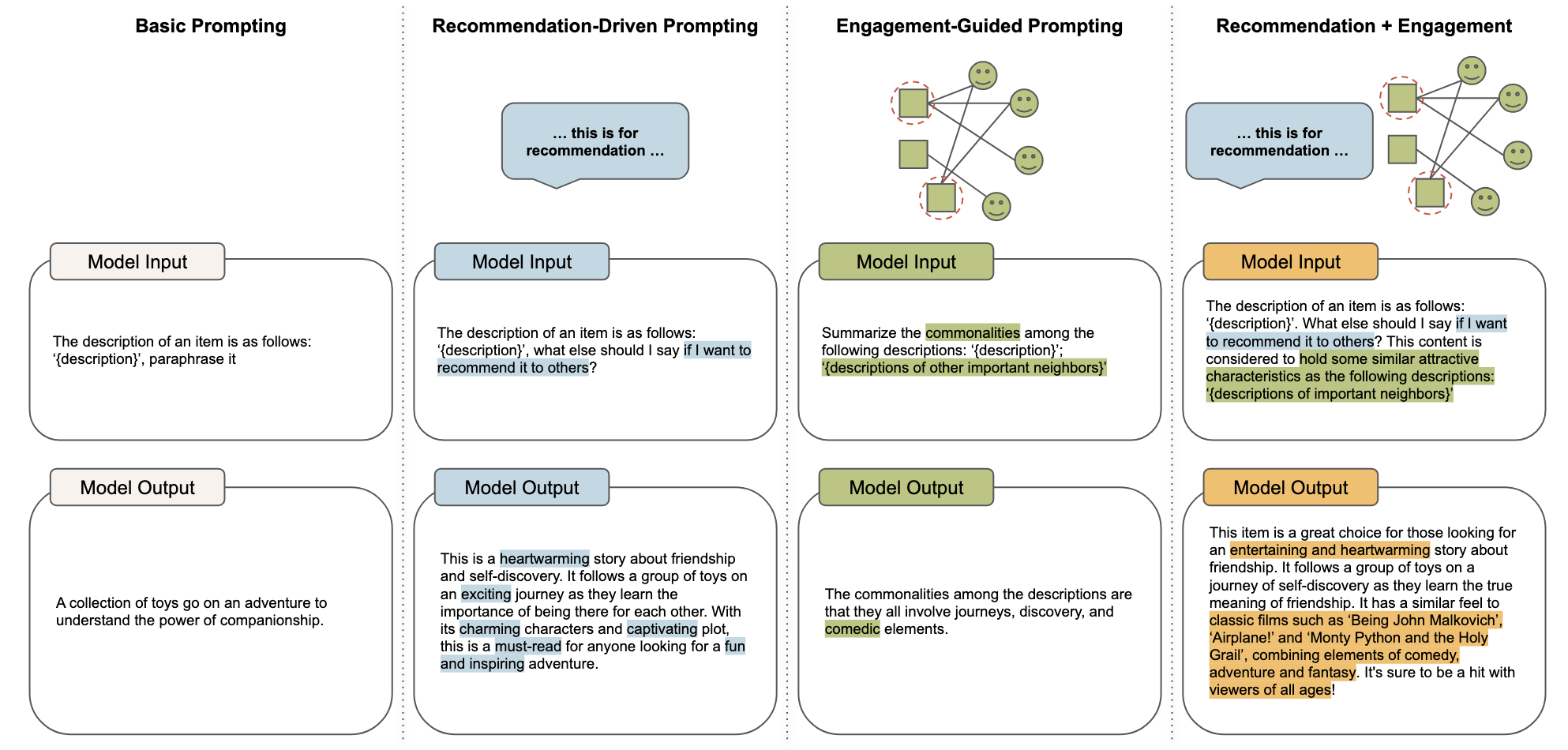
Basic prompting
基础提示,主要有以下三种
- \(P_{para}\):提示LLM对原始内容进行改述,尽量保持原本的意思不变,并且不加入额外的内容。
- \(P_{tag}\):提示LLM用标签总结原始内容,用更简洁的表述捕获关键信息。
- \(P_{infer}\):提示LLM对原始内容的特征进行一些推理,并提供一个比较宽泛的回答。
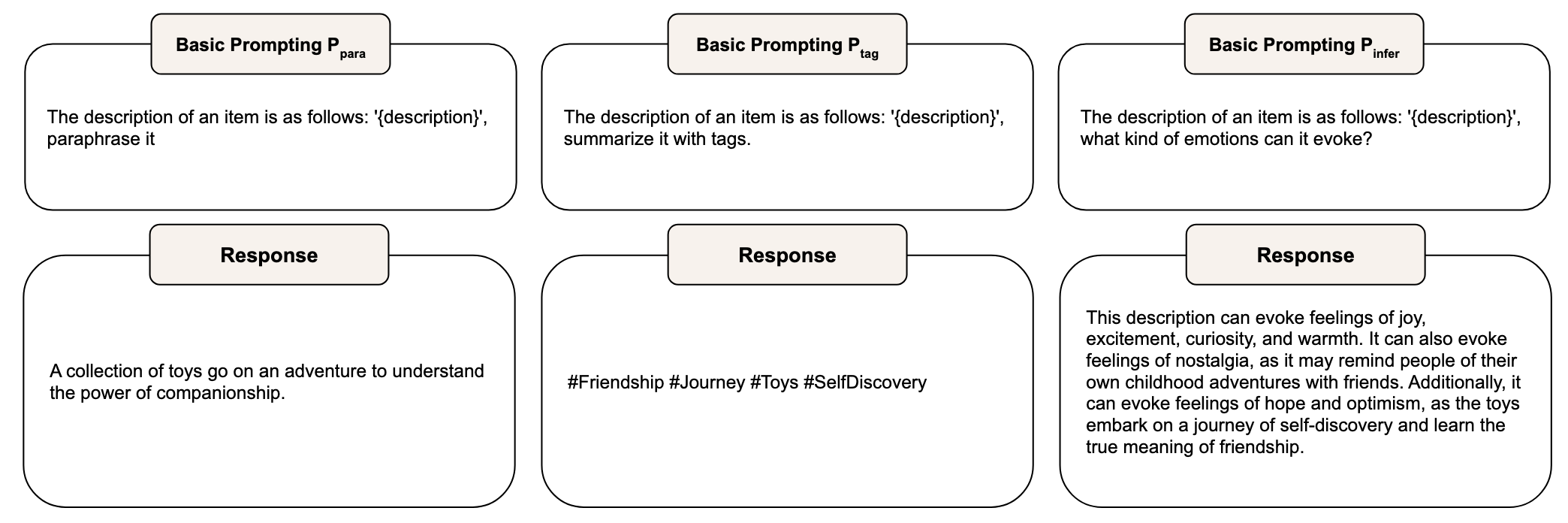
Recommendation-driven prompting
推荐驱动的提示,在基础提示的基础上增加推荐指令,例如“我想把它推荐给他人”这样的语句。这种提示可以使得生成的内容更适合推荐的场景(虽然作者提到了有三种特点,但是我觉得可以用这一句话概括)。
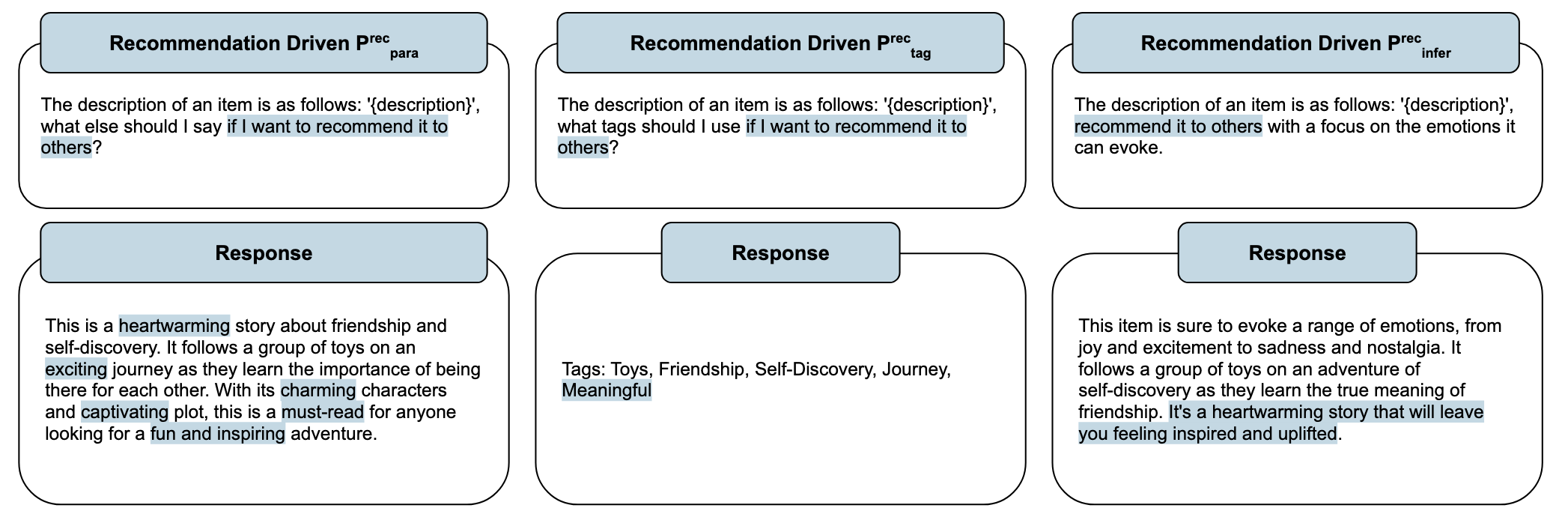
Engagement-guided prompting
参与引导的提示。简单来说,论文中作者根据user与item的交互(如果一个user常与两个item交互,那么这两个item相似度较高),计算出与当前item最相似的T个item,并在输入中,把这T个相似的item的描述也加入。这种方式可以使得LLM生成的内容与当前item更相关,更符合用户的偏好。
Recommendation-driven + engagement-guided prompting
推荐驱动的提示与参与引导的提示的结合。
Experiment
- Benchmarks:用到两个数据集MovieLens-1M和Recipe。
- Item module:
- Response generation:GPT-3(text-davinci-003)
- Text encoder:Sentence-BERT
- Engagement-guided prompting中的重要性度量:见上述。
- User module:大小为128的embedding
- User module:
- ItemPop:流行度推荐
- MLP
- AutoInt
- DCN-V2
- Model training:交叉熵损失
- Evaluation protocols:Precision、Recall、NDCG
Results
整体的评估框架。

LLM-Rec(使用MLP作为推荐模型,只是输入使用LLM进行了增强)取得了最佳推荐表现,超越了其他更复杂的基于特征的方法。
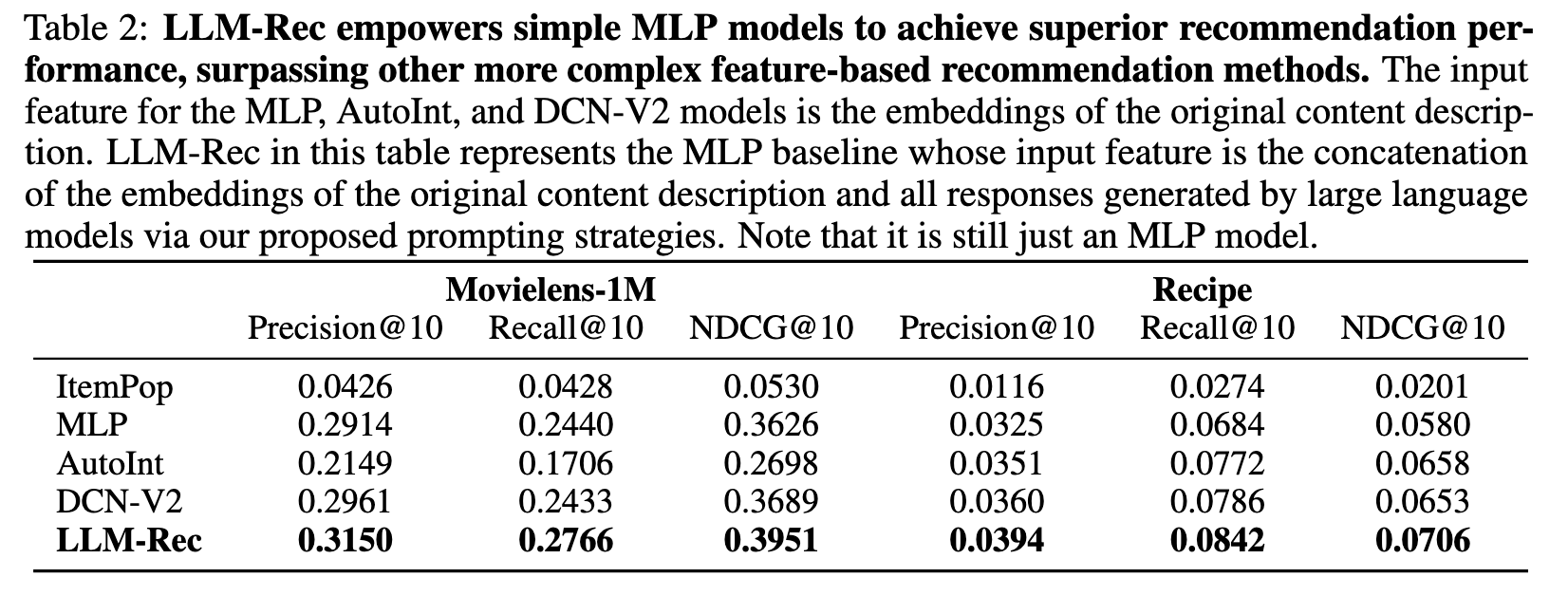
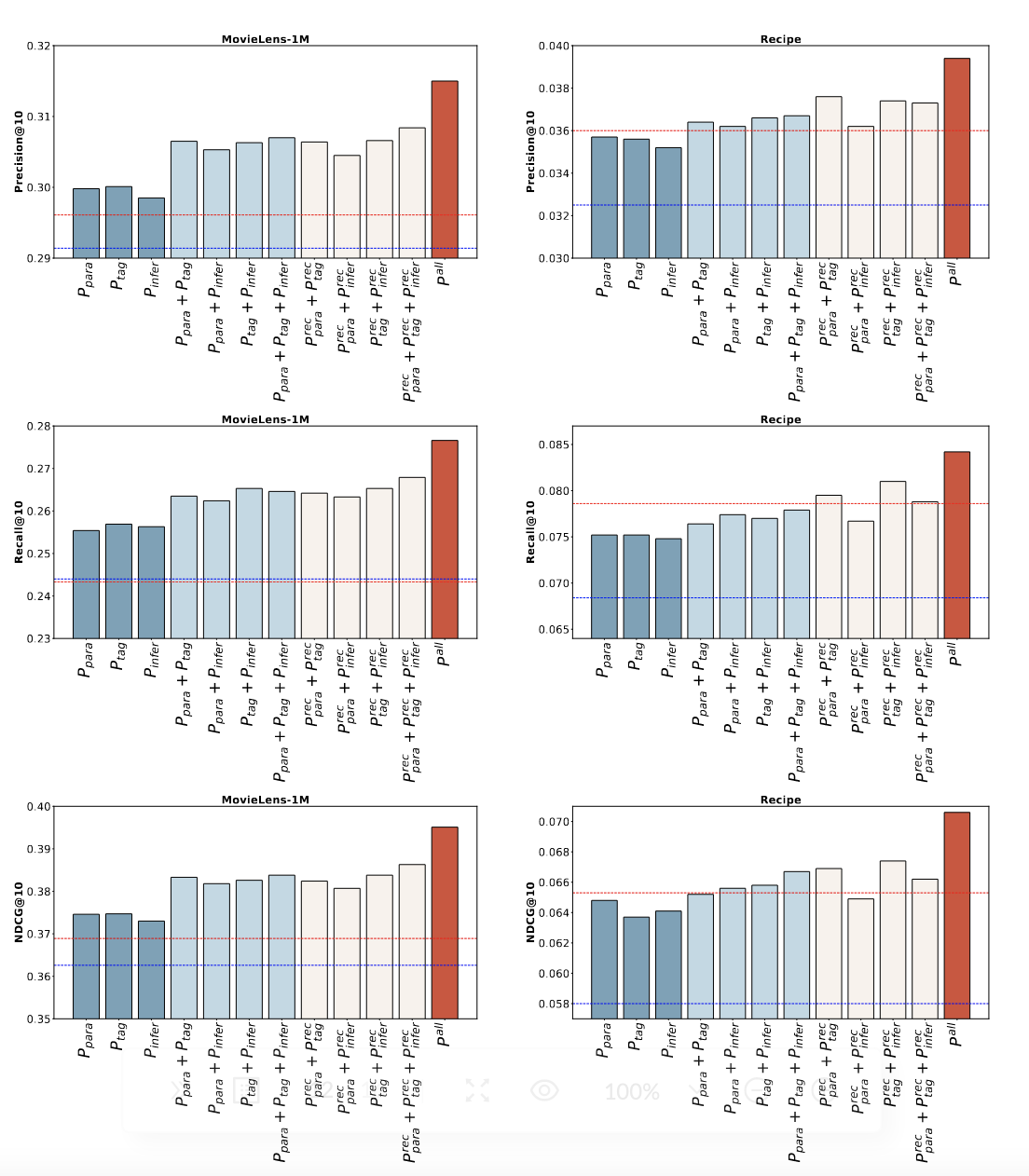
下表展示了每个提示策略的推荐性能,蓝线是只使用原始内容不进行数据增强的情况。

结合重要的关键字,而不是全部生成的内容,可以获得更好的推荐效果。

将生成的所有内容的embedding和原始内容的embedding拼在一起会有更好的推荐效果。
Summary
本文通过提示大模型对输入进行数据增强,提高推荐系统的推荐效果。通过试验结果可以看出,经过LLM增强后的输入对推荐有很大帮助,即使是只使用MLP作为推荐模型,也可以取得超越一些复杂的推荐模型的效果。将各种提示策略(转述、标签、推理)生成的内容进行集成后,会获取更好的效果,这表明生成的内容是互补的。但是,作者在实验中发现,通过推理进行数据增强并没有达到预期的效果,因为通过推理生成的内容已经超出了原始数据的范围,其对推荐可能会产生未知的影响,因此需要进一步研究如何设计出更合适的推理提示以及推理产生的内容对推荐的影响。
通过提示大语言模型进行个性化推荐LLM-Rec: Personalized Recommendation via Prompting Large Language Models的更多相关文章
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- CSDDN特约专稿:个性化推荐技术漫谈
本文引自http://i.cnblogs.com/EditPosts.aspx?opt=1 如果说过去的十年是搜索技术大行其道的十年,那么个性化推荐技术将成为未来十年中最重要的革新之一.目前几乎所有大 ...
- 为什么要用深度学习来做个性化推荐 CTR 预估
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:苏博览 深度学习应该这一两年计算机圈子里最热的一个词了.基于深度学习,工程师们在图像,语音,NLP等领域都取得了令人振奋的进展.而深 ...
- 从0开始做垂直O2O个性化推荐-以58到家美甲为例
从0开始做垂直O2O个性化推荐 上次以58转转为例,介绍了如何从0开始如何做互联网推荐产品(回复"推荐"阅读),58转转的宝贝为闲置物品,品类多种多样,要做统一的宝贝画像比较难,而 ...
- Slope one—个性化推荐中最简洁的协同过滤算法
Slope One 是一系列应用于 协同过滤的算法的统称.由 Daniel Lemire和Anna Maclachlan于2005年发表的论文中提出. [1]有争议的是,该算法堪称基于项目评价的non ...
- 搜索实时个性化模型——基于FTRL和个性化推荐的搜索排序优化
本文来自网易云社区 作者:穆学锋 简介:传统的搜索个性化做法是定义个性化的标签,将用户和商品通过个性化标签关联起来,在搜索时进行匹配.传统做法的用户特征基本是离线计算获得,不够实时:个性化标签虽然具有 ...
- 个性化推荐产品功能的设计和B端产品的功能策划方式
宜信科技中心财富管理产品部负责人Bob,与大家一起聊聊个性化推荐产品功能的设计和B端产品的功能策划方式. 拓展阅读:回归架构本质,重新理解微服务|专访宜信开发平台(SIA)负责人梁鑫 智慧金融时代,大 ...
- 使用Python3.7配合协同过滤算法(base on user,基于人)构建一套简单的精准推荐系统(个性化推荐)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_136 时至2020年,个性化推荐可谓风生水起,Youtube,Netflix,甚至于Pornhub,这些在互联网上叱咤风云的流媒体 ...
- 推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
0.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回.粗排.精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板: 粗排是初筛,一般不会上复杂模型: 精排是整个推荐环节的重 ...
随机推荐
- Java(类的继承)
1.继承 extends的意思是"扩展".子类是父类的扩展,使用关键字extends来表示. Java里,一个类只能继承一个父类. 继承是类与类之间的一种关系,此外还有依赖.组合. ...
- Flash Download failed -“Cortex-M3”
STM32下载程序时经常出现如下问题,即 error:Flash Download failed -"Cortex-M3" 经查找网络攻略,总结如下: (1). (2). ( ...
- selenium-wire简介
一.简介 以下来自chatGPT回答: selenium-wire是一个基于selenium的Python库,它扩展了selenium的功能,使得我们可以在自动化测试中直接访问和修改浏览器的网络请求和 ...
- 驱动开发:内核ShellCode线程注入
还记得<驱动开发:内核LoadLibrary实现DLL注入>中所使用的注入技术吗,我们通过RtlCreateUserThread函数调用实现了注入DLL到应用层并执行,本章将继续探索一个简 ...
- Git使用教程(带你玩转GitHub)
Git使用教程(理论实体结合体系版) 下载安装: 按照这个博客来就好 Windows系统Git安装教程(详解Git安装过程) - 学为所用 - 博客园 (cnblogs.com) Git命令大全: G ...
- 教程 | Datavines 自定义数据质量检查规则(Metric)
Metric 是 Datavines 中一个核心概念,一个 Metric 表示一个数据质量检查规则,比如空值检查和表行数检查都是一个规则.Metric 采用插件化设计,用户可以根据自己的需求来实现一个 ...
- K8S | 容器和Pod组件
对比软件安装和运行: 一.场景 作为研发人员,通常自己电脑的系统环境都是非常复杂,在个人的习惯上,是按照下图的模块管理电脑的系统环境: 对于「基础设施」.「主机操作系统」.「系统软件」来说,通常只做配 ...
- Stable Diffusion生成图片的参数查看与抹除方法
前几天分享了几张Stable Diffusion生成的艺术二维码,有同学反映不知道怎么查看图片的参数信息,还有的同学问怎么保护自己的图片生成参数不会泄露,这篇文章就来专门分享如何查看和抹除图片的参数. ...
- centOS7 磁盘扩容(2T以上)
centOS7 磁盘扩容 1.安装parted分区工具 yum install -y parted 2.查看服务器分区情况 #fdisk -l 或者 lsblk 找到新增磁盘名称 例如/dev/sdb ...
- 更快的训练和推理: 对比 Habana Gaudi®2 和英伟达 A100 80GB
通过本文,你将学习如何使用 Habana Gaudi2 加速模型训练和推理,以及如何使用 Optimum Habana 训练更大的模型.然后,我们展示了几个基准测例,包括 BERT 预训练.Stabl ...