深度学习(五)——DatadLoader的使用
一、DataLoader简介
官网地址:
1. DataLoder类
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device='')
由此可见,DataLoder必须需要输入的参数只有\(dataset\)。
2. 参数说明
dataset(Dataset): 数据集的储存的路径位置等信息
batch_size(int): 每次取数据的数量,比如batchi_size=2,那么每次取2条数据
shuffle(bool): True: 打乱数据(可以理解为打牌中洗牌的过程); False: 不打乱。默认为False
num_workers(int): 加载数据的进程,多进程会更快。默认为0,即用主进程进行加载。但在windows系统下,num_workers如果非0,可能会出现 BrokenPipeError[Error 32] 错误
drop_last(bool): 比如我们从100条数据中每次取3条,到最后会余下1条,如果drop_last=True,那么这条数据会被舍弃(即只要前面99条数据);如果为False,则保留这条数据
二、DataLoader实操
- 数据集仍然采用上一篇的CIFAR10数据集
1. DataLoader取数据的逻辑
首先import dataset,dataset会返回一个数据的img和target
然后import dataloder,并设置\(batch\_size\),比如\(batch\_size=4\),那么dataloder会获取这些数据:dataset[0]=img0, target0; dataset[1]=img1, target1; dataset[2]=img2, target2; dataset[3]=img3, target3. 并分别将其中的4个img和4个target进行打包,并返回打包好的imgs和targets
比如下面这串代码:
import torchvision
from torch.utils.data import DataLoader
#测试集,并将PIL数据转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#batch_size=4:每次从test_data中取4个数据集并打包
test_loader=DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
这里的test_loader会取出test_data[0]、test_data[1]、test_data[2]、test_data[3]的img和target,并分别打包。返回两个参数:打包好的imgs,打包好的taregts
2. 如何取出DataLoader中打包好的img、target数据
(1)输出打包好的img、target
代码示例如下:
import torchvision
from torch.utils.data import DataLoader
#测试集,并将PIL数据转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#batch_size=4:每次从test_data中取4个数据集并打包
test_loader=DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
#测试数据集中第一章图片及target
img, target=test_data[0]
print(img.shape)
print(target)
#取出test_loader中的图片
for data in test_loader:
imgs,targets = data
print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
在11行处debug一下可以发现,test_loader中有个叫sampler的采样器,采取的是随机采样的方式,也就是说这batch_size=4时,每次抓取的4张图片都是随机抓取的。
(2)展示图片
用tensorboard就可以可视化了,具体操作改一下上面代码最后的for循环就好了
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("dataloder")
step=0 #tensorboard步长参数
for data in test_loader:
imgs,targets = data
# print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
# print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
writer.add_images("test_data",imgs,step) #注意这里是add_images,不是add_image。因为这里是加入了64张图
step=step+1
writer.close()
(3)关于shuffle的理解
- 可以理解为一个for循环就是打一次牌,打完一轮牌后,若shuffle=False,那么下一轮每一步抓到的牌都会跟上一轮相同;如果shuffle=True,那么就会进行洗牌,打乱牌的顺序后,下一轮每一步跟上一轮的会有不同。
首先将shuffle设置为False:
test_loader=DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
然后对(2)的代码进行修改,运行代码:
for epoch in range(2): #假设打两次牌,我们来观察两次牌中间的洗牌情况
step = 0 # tensorboard步长参数
for data in test_loader:
imgs,targets = data
# print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
# print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
writer.add_images("Epoch: {}".format(epoch),imgs,step) #注意这里是add_images,不是add_image。因为这里是加入了64张图
step=step+1
writer.close()
结果显示,未洗牌时运行的结果是一样的:
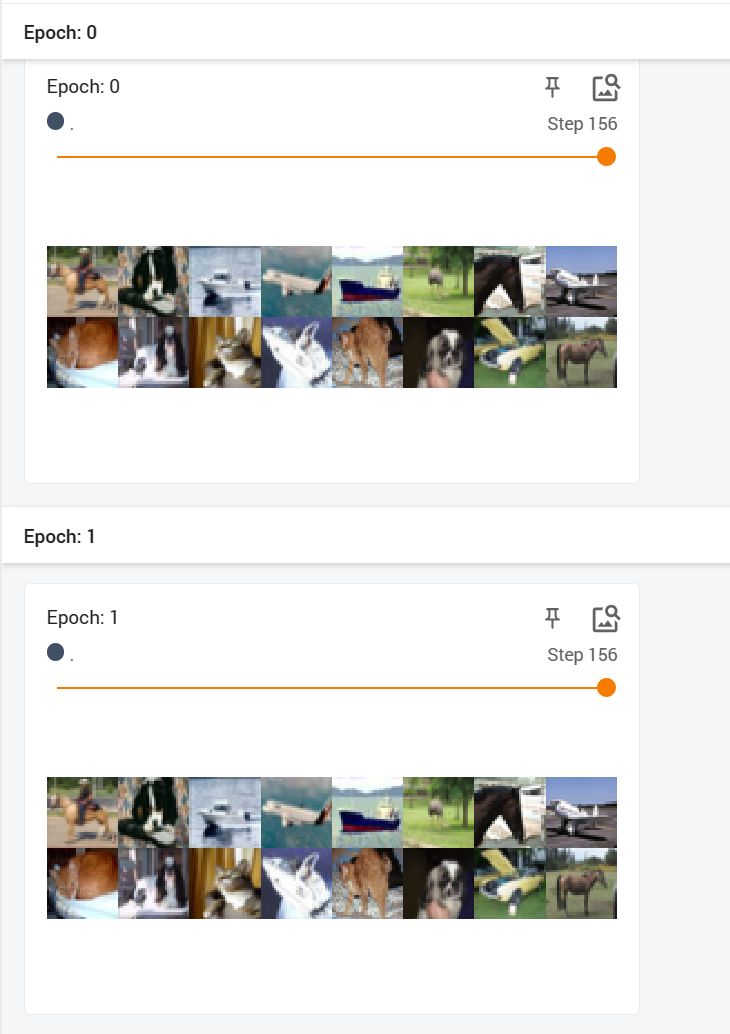
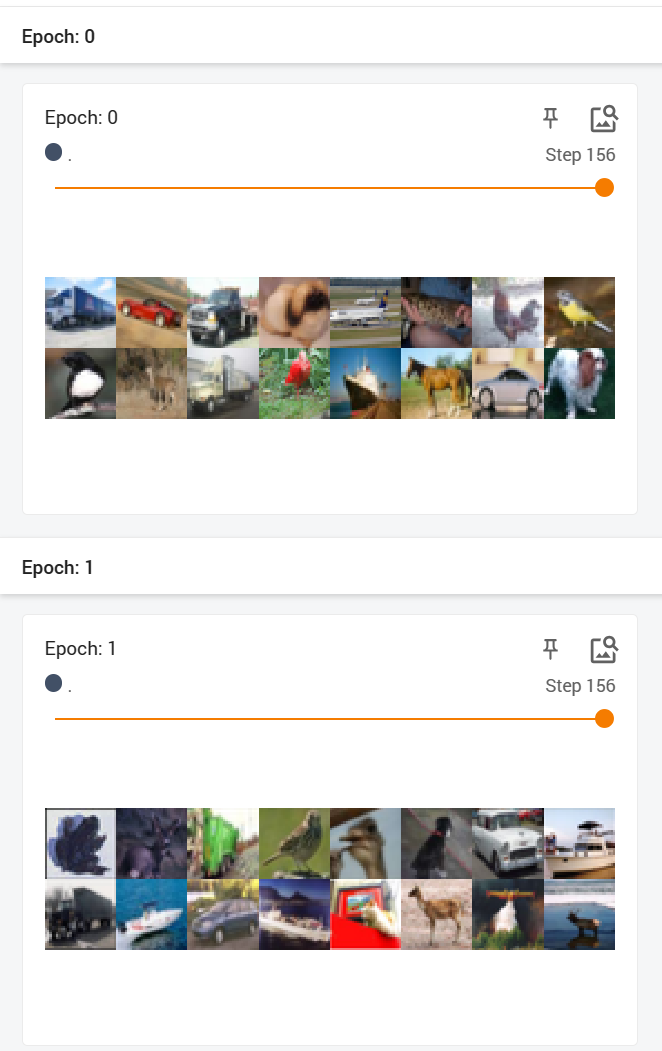
- 将shuffle设置为True,再次运行,可以发现两次结果还是不一样的:
深度学习(五)——DatadLoader的使用的更多相关文章
- go微服务框架go-micro深度学习(五) stream 调用过程详解
上一篇写了一下rpc调用过程的实现方式,简单来说就是服务端把实现了接口的结构体对象进行反射,抽取方法,签名,保存,客户端调用的时候go-micro封请求数据,服务端接收到请求时,找到需要调用调 ...
- 深度学习菜鸟的信仰地︱Supervessel超能云服务器、深度学习环境全配置
并非广告~实在是太良心了,所以费时间给他们点赞一下~ SuperVessel云平台是IBM中国研究院和中国系统与技术中心基于POWER架构和OpenStack技术共同构建的, 支持开发者远程开发的免费 ...
- go微服务框架go-micro深度学习-目录
go微服务框架go-micro深度学习(一) 整体架构介绍 go微服务框架go-micro深度学习(二) 入门例子 go微服务框架go-micro深度学习(三) Registry服务的注册和发现 go ...
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- Deep Learning(深度学习)学习笔记整理系列之(五)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(五)Ensemble
深度学习课程笔记(五)Ensemble 2017.10.06 材料来自: 首先提到的是 Bagging 的方法: 我们可以利用这里的 Bagging 的方法,结合多个强分类器,来提升总的结果.例如: ...
- 深度学习(五)基于tensorflow实现简单卷积神经网络Lenet5
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/8954892.html 参考博客:https://blog.csdn.net/u01287127 ...
- UFLDL深度学习笔记 (五)自编码线性解码器
UFLDL深度学习笔记 (五)自编码线性解码器 1. 基本问题 在第一篇 UFLDL深度学习笔记 (一)基本知识与稀疏自编码中讨论了激活函数为\(sigmoid\)函数的系数自编码网络,本文要讨论&q ...
- 深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition 论文作者: Gregory Koch Richard Zemel Rusla ...
随机推荐
- 【深度学习】【图像分类网络】(一)残差神经网络ResNet以及组卷积ResNeXt
ResNet网络 论文:Deep Residual Learning for Image Recognition 网络中的亮点: 1 超深的网络结构(突破了1000层) 上图为简单堆叠卷积层和池化层的 ...
- 文盘Rust -- 用Tokio实现简易任务池
作者:京东科技 贾世闻 Tokio 无疑是 Rust 世界中最优秀的异步Runtime实现.非阻塞的特性带来了优异的性能,但是在实际的开发中我们往往需要在某些情况下阻塞任务来实现某些功能. 我们看看下 ...
- 分布式缓存--Redis
目录 一.单点Redis的问题 二.Redis持久化 2.1 RDB持久化 2.1.1 单机安装Redis 2.1.2 RDB内部机制 2.1.3 RDB异步持久化 2.1.14 RDB的缺点 2.2 ...
- C# 从0到实战 lambda表达式和Expression-bodied表达式
什么是lambda表达式(λ表达式) 用过其他函数式语言的人可能对闭包和惰性计算很熟悉,没有用过的人也多多少少的听说过Lambda表达式.那么到底什么是lambda表达式呢?按我的看法是创建一个匿名的 ...
- DRF的Serializer组件(源码分析)
DRF的Serializer组件(源码分析) 1. 数据校验 drf中为我们提供了Serializer,他主要有两大功能: 对请求数据校验(底层调用Django的Form和ModelForm) 对数据 ...
- RTSP Server(LIVE555)源码分析(五)-PLAY信令
主要分析RTSPServer::RTSPClientSession针对客户端PLAY事件处理 一. PLAY信令,handleCmd_withinSession源码解析 1)步骤1.03,当RTSP客 ...
- 继承 extends
首先是基础的继承关系,用extend就可以继承. 再者是继承的东西,包括:变量(也包括类变量).全部非私有的属性和方法(除了父类的构造方法) 注:构造方法 class C{ public C() { ...
- 我的web系统设计规范
以下是我自己在工作中总结的,仅供参考. ·应对所有用户输入进行trim()去除两头空格,若是需要空格的应用 转义代替,不应在js里trim(),而应该在数据库端或后端控制,且只在一处拦截控制,更改策略 ...
- 存下吧!Spring高频面试题总结
Spring是什么? Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架. Spring的优点 通过控制反转和依赖注入实现松耦合. 支持面向切面的编程,并且把应用业务逻辑和系统 ...
- 2022-08-25:以下go语言代码输出什么?A:1 0;B:1 2;C:不能编译;D:0 0。 package main import “fmt“ func named() (n, _ int
2022-08-25:以下go语言代码输出什么?A:1 0:B:1 2:C:不能编译:D:0 0. package main import "fmt" func named() ( ...