YAML编写应用的资源清单文件(十五)
上面我们在 Kubernetes 中部署了我们的第一个容器化应用,我们了解到要部署应用最重要的就是编写应用的资源清单文件。那么如何编写资源清单文件呢?日常使用的时候我们都是使用 YAML 文件来编写,但是现状却是大部分同学对 JSON 更加熟悉,对 YAML 文件的格式不是很熟悉,所以也导致很多同学在编写资源清单的时候似懂非懂的感觉,所以在了解如何编写资源清单之前我们非常有必要来了解下 YAML 文件的用法。
YAML 是专门用来写配置文件的语言,非常简洁和强大,远比 JSON 格式方便。YAML语言(发音 /ˈjæməl/)的设计目标,就是方便人类读写。它实质上是一种通用的数据串行化格式。
它的基本语法规则如下:
1. 大小写敏感
2. 使用缩进表示层级关系
3. 缩进时不允许使用Tab键,只允许使用空格
4. 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
5. # 表示注释,从这个字符一直到行尾,都会被解析器忽略
在 Kubernetes 中,我们只需要了解两种结构类型就行了:
- Lists(列表)
- Maps(字典)
也就是说,你可能会遇到 Lists 的 Maps 和 Maps 的 Lists,等等。不过不用担心,你只要掌握了这两种结构也就可以了,其他更加复杂的我们暂不讨论。
二、Maps
首先我们来看看 Maps,我们都知道 Map 是字典,就是一个 key:value 的键值对,Maps 可以让我们更加方便的去书写配置信息,例如:
---
apiVersion: v1
kind: Pod
第一行的---是分隔符,是可选的,在单一文件中,可用连续三个连字号---区分多个文件。这里我们可以看到,我们有两个键:kind 和 apiVersion,他们对应的值分别是:v1 和 Pod。上面的 YAML 文件转换成 JSON 格式的话,你肯定就容易明白了:
{
"apiVersion": "v1",
"kind": "pod"
}
我们在创建一个相对复杂一点的 YAML 文件,创建一个 KEY 对应的值不是字符串而是一个 Maps:
---
apiVersion: v1
kind: Pod
metadata:
name: ydzs-site
labels:
app: web
上面的 YAML 文件,metadata 这个 KEY 对应的值就是一个 Maps 了,而且嵌套的 labels 这个 KEY 的值又是一个 Map,你可以根据你自己的情况进行多层嵌套。
上面我们也提到了 YAML 文件的语法规则,YAML 处理器是根据行缩进来知道内容之间的嗯关联性的。比如我们上面的 YAML 文件,我用了两个空格作为缩进,空格的数量并不重要,但是你得保持一致,并且至少要求一个空格(什么意思?就是你别一会缩进两个空格,一会缩进4个空格)。我们可以看到 name 和 labels 是相同级别的缩进,所以 YAML 处理器就知道了他们属于同一个 Map,而 app 是 labels 的值是因为 app 的缩进更大。
注意:在 YAML 文件中绝对不要使用 tab 键来进行缩进。
同样的,我们可以将上面的 YAML 文件转换成 JSON 文件:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "kube100-site",
"labels": {
"app": "web"
}
}
}
或许你对上面的 JSON 文件更熟悉,但是你不得不承认 YAML 文件的语义化程度更高吧?
三、Lists
Lists就是列表,说白了就是数组,在 YAML 文件中我们可以这样定义:
args
- Cat
- Dog
- Fish
你可以有任何数量的项在列表中,每个项的定义以破折号(-)开头的,与父元素之间可以缩进也可以不缩进。对应的 JSON 格式如下:
{
"args": [ 'Cat', 'Dog', 'Fish' ]
}
当然,Lists 的子项也可以是 Maps,Maps 的子项也可以是 Lists 如下所示:
---
apiVersion: v1
kind: Pod
metadata:
name: ydzs-site
labels:
app: web
spec:
containers:
- name: front-end
image: nginx
ports:
- containerPort: 80
- name: flaskapp-demo
image: cnych/flaskapp
ports:
- containerPort: 5000
比如这个 YAML 文件,我们定义了一个叫 containers 的 List 对象,每个子项都由 name、image、ports 组成,每个 ports 都有一个 key 为 containerPort 的 Map 组成,同样的,我们可以转成如下 JSON 格式文件:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "ydzs-site",
"labels": {
"app": "web"
}
},
"spec": {
"containers": [{
"name": "front-end",
"image": "nginx",
"ports": [{
"containerPort": "80"
}]
}, {
"name": "flaskapp-demo",
"image": "cnych/flaskapp",
"ports": [{
"containerPort": "5000"
}]
}]
}
}
是不是觉得用 JSON 格式的话文件明显比 YAML 文件更复杂了呢?
四、如何编写资源清单
上面我们了解了 YAML 文件的基本语法,现在至少可以保证我们的编写的 YAML 文件语法是合法的,那么要怎么编写符合 Kubernetes API 对象的资源清单呢?比如我们怎么知道 Pod、Deployment 这些资源对象有哪些功能、有哪些字段呢?
一些简单的资源对象我们可能可以凭借记忆写出对应的资源清单,但是 Kubernetes 发展也非常快,版本迭代也很快,每个版本中资源对象可能又有很多变化,那么有没有一种办法可以让我们做到有的放矢呢?
实际上是有的,最简单的方法就是查找 Kubernetes API 文档,比如我们现在使用的是 v1.19.3 版本的集群,可以通过地址 https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.19/ 查找到对应的 API 文档,在这个文档中我们可以找到所有资源对象的一些字段。
比如我们要了解创建一个 Deployment 资源对象需要哪些字段,我们可以打开上面的 API 文档页面,在左侧侧边栏找到 Deployment v1 apps,点击下面的 Write Operations,然后点击 Create,然后我们查找到创建 Deployment 需要提交的 Body 参数
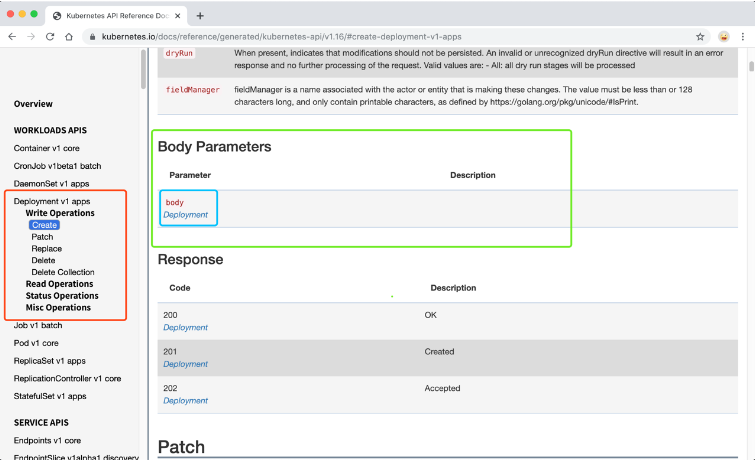
然后点击 Body,进入到参数详情页:

这个时候我们就可以看到我们创建 Deployment 需要的一些字段了,比如 apiVersion、kind、metadata、spec 等,而且每个字段都有对应的文档说明,比如我们像要了解 DeploymentSpec 下面有哪些字段,继续点击进去查看就行:

每个字段具体什么含义以及每个字段下面是否还有其他字段都可以这样去追溯。
但是如果平时我们编写资源清单的时候都这样去查找文档势必会效率低下,Kubernetes 也考虑到了这点,我们可以直接通过 kubectl 命令行工具来获取这些字段信息,同样的,比如我们要获取 Deployment 的字段信息,我们可以通过 kubectl explain 命令来了解:
$ kubectl explain deployment
KIND: Deployment
VERSION: apps/v1
DESCRIPTION:
Deployment enables declarative updates for Pods and ReplicaSets.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
metadata <Object>
Standard object metadata.
spec <Object>
Specification of the desired behavior of the Deployment.
status <Object>
Most recently observed status of the Deployment.
我们可以看到上面的信息和我们在 API 文档中查看到的基本一致,比如我们看到其中 spec 字段是一个 类型的,证明该字段下面是一个对象,我们可以继续去查看这个字段下面的详细信息:
$ kubectl explain deployment.spec
KIND: Deployment
VERSION: apps/v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of the Deployment.
DeploymentSpec is the specification of the desired behavior of the
Deployment.
FIELDS:
minReadySeconds <integer>
Minimum number of seconds for which a newly created pod should be ready
without any of its container crashing, for it to be considered available.
Defaults to 0 (pod will be considered available as soon as it is ready)
paused <boolean>
Indicates that the deployment is paused.
progressDeadlineSeconds <integer>
The maximum time in seconds for a deployment to make progress before it is
considered to be failed. The deployment controller will continue to process
failed deployments and a condition with a ProgressDeadlineExceeded reason
will be surfaced in the deployment status. Note that progress will not be
estimated during the time a deployment is paused. Defaults to 600s.
replicas <integer>
Number of desired pods. This is a pointer to distinguish between explicit
zero and not specified. Defaults to 1.
revisionHistoryLimit <integer>
The number of old ReplicaSets to retain to allow rollback. This is a
pointer to distinguish between explicit zero and not specified. Defaults to
10.
selector <Object> -required-
Label selector for pods. Existing ReplicaSets whose pods are selected by
this will be the ones affected by this deployment. It must match the pod
template's labels.
strategy <Object>
The deployment strategy to use to replace existing pods with new ones.
template <Object> -required-
Template describes the pods that will be created.
如果一个字段显示的是 required,这就证明该自动是必填的,也就是我们在创建这个资源对象的时候必须声明这个字段,每个字段的类型也都完全为我们进行了说明,所以有了 kubectl explain 这个命令我们就完全可以写出一个不熟悉的资源对象的清单说明了,这个命令我们也是必须要记住的,会在以后的工作中为我们提供很大的帮助。
下一篇将介绍Kubernetes中Pod原理
(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
YAML编写应用的资源清单文件(十五)的更多相关文章
- YAML资源清单
YAML 文件基本语法格式 在 Docker 环境下面我们是直接通过命令 docker run 来运行我们的应用的,在 Kubernetes 环境下面我们同样也可以用类似 kubectl run 这样 ...
- 1.k8s概述、安装、名词解释、资源清单
一.k8s概述 1.简介 Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernete ...
- Ansible之 Inventory 资源清单介绍
一.Inventory 库存清单文件 1.Inventory 作用 Ansible 可以在同一时间针对多个系统设施进行管理工作.它通过选择Ansible 资源清单文件中列出的系统,该清单文件默认是在/ ...
- Ansible 系列之 Inventory 资源清单介绍
一.Inventory 库存清单文件 1.Inventory 作用 Ansible 可以在同一时间针对多个系统设施进行管理工作.它通过选择Ansible 资源清单文件中列出的系统,该清单文件默认是在/ ...
- Kubernetes学习之路(十五)之Ingress和Ingress Controller
目录 一.什么是Ingress? 1.Pod 漂移问题 2.端口管理问题 3.域名分配及动态更新问题 二.如何创建Ingress资源 三.Ingress资源类型 1.单Service资源型Ingres ...
- K8是—— yaml资源清单
K8是-- yaml资源清单 一.yaml文件详解 1.Kubernetes支持YAML和JSON格式管理资源对象2.JSON格式:主要用于api接口之间消息的传递3.YAML格式:用于配置和管理,Y ...
- Android多版本flavor配置之资源文件和清单文件合并介绍
知识背景 Android studio升级到3.0之后,gradle增加了多维度管理配置,便于同一个项目中创建应用的不同版本,分别管理依赖项并签署配置.创建产品风味与创建构建类型类似:只需将它们添加到 ...
- Kubernetes【K8S】(三):资源清单
K8S中的资源 K8S中所有的内容都抽象为资源,资源实例化之后叫做对象.一般使用yaml格式的文件来创建符合我们预期的pod,这样的yaml文件我们一般成为资源清单. 名称空间级资源 工作负载型资源( ...
- k8s学习笔记之五:Pod资源清单spec字段常用字段及含义
第一章.前言 在上一篇博客中,我们大致简述了一般情况下资源清单的格式,以及如何获得清单配置的命令帮助,下面我们再讲解下清单中spec字段中比较常见的字段及其含义 第二章.常用字段讲解 spec.con ...
- Android AndroidManifest 清单文件以及权限具体解释
每一个Android应用都须要一个名为AndroidManifest.xml的程序清单文件,这个清单文件名称是固定的而且放在每一个Android应用的根文件夹下.它定义了该应用对于Android系统来 ...
随机推荐
- JavaScript小面试~宏任务和微任务
首先,我们要知道JavaScript是单线程调用,在程序启动的时候,会把不同的代码段分派到不同的调用栈,同步任务在同步栈中直接执行,宏任务分派到宏任务栈,微任务会分配到微任务栈,分配好之后,调用栈会被 ...
- 测试思想-流程规范 用例优先级定义与使用规范 V1.0
用例优先级定义与使用规范 V1.0 By:授客 1. 规范说明 目的 对软件测试过程中的用例级别进行详细描述及标准化定义,明确不同测试阶段的测试范围,减少测试冗余投入,提高测试效率,建立 ...
- Android studio报错:Failed to allocate a 3213123 byte allocation with 31231 free bytes and 189MB ontil 0OM
这个问题是运行内存超了 在AndroidManifest中加入 android:hardwareAccelerated="false"android:largeHeap= &quo ...
- js实现动态表格的添加
<!DOCTYPE html> <html lang="en"> <head> <title>Table_Simple CSS fo ...
- 用了组合式 (Composition) API 后代码变得更乱了,怎么办?
前言 组合式 (Composition) API 的一大特点是"非常灵活",但也因为非常灵活,每个开发都有自己的想法.加上项目的持续迭代导致我们的代码变得愈发混乱,最终到达无法维护 ...
- 【Hibernate】05 缓存与MySQL事务隔离
Cache 什么是缓存? 数据存储到数据库,是从内存中以流的方式写进[输出]到数据库,其效率并不是很高 - 所以在内存中暂存一部分数据,可以不以流的方式读取,效率是非常高的[相对于流来说] Hiber ...
- 【转载】sun的rpc ——rpcbind(nfs文件系统中的rpc)
原文地址: https://blog.csdn.net/wangpeng138375/article/details/8169071 ================================= ...
- 二分答案&前缀和&差分&离散化(简记)
二分答案 基本code int Find(int l,int r) { int ans,mid; while(l<=r) { int mid=l+r>>1; if(Check(mid ...
- Oracle——navicat连接Oracle数据库报错(12514)
2024/07/22 1.问题描述 2.解决办法 3.参考材料 1.问题描述 与其他厂商做数据对接时,对方提供相关视图,我navicat连接Oracle数据库时报错,其报错代码如下: ORA-1251 ...
- CF1693D--单调区间
\(T_4\) 单调区间结题报告 题目描述 一句话题意:给定一个排列 \(a\) 算出有多少个区间 \([l , r]\) , 满足其可以划分为一个单调递增子序列和单调递减子序列,其中单调递增子序列长 ...