机器学习|K邻近(K Nearest-Neighbours)
本文从概念、原理、距离函数、K 值选择、K 值影响、、优缺点、应用几方面详细讲述了 KNN 算法
K 近临(K Nearest-Neighbours)
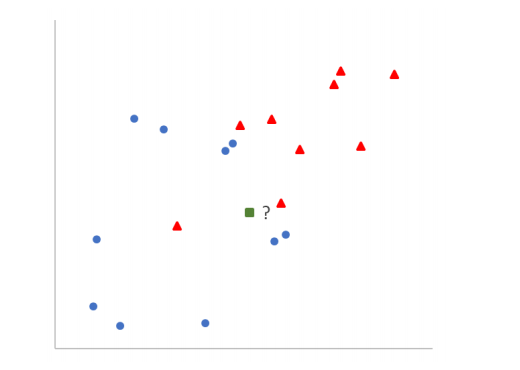
一种简单的监督学习算法,惰性学习算法,在技术上并不训练模型来预测。适用于分类和回归任务。它的核心思想是:相似的对象彼此接近。例如,若果你想分类一个新的数据点(绿点),可以查看训练数据中哪些数据点与它最接近,并根据这些最接近的数据点和标签来预测它的标签(红点或蓝圆)。
概念
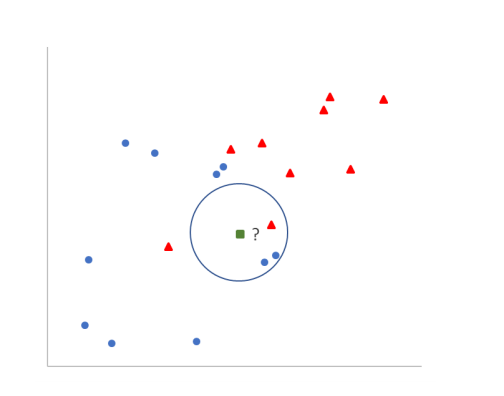
K: 这是一个用户指定的正整数,即训练数据分类数量,代表要考虑的最近邻居的数量,上图中假设 K=2,即训练数据分类为蓝色圆和红色三角两类标签。
距离函数: 用于计算数据点之间的距离。最常见的是欧几里得距离、曼哈顿距离、马氏距离等。
投票机制:
- 分类任务: 将根据 k 个最近邻的多数投票来确定新数据点的类别。
- 回归任务: 通常取 k 个最近邻的输出变量的平均值。
原理
- 距离计算: 对于给定的新数据点,计算它与训练数据集中每个点的距离。
- 选取 K 个邻居: 从训练数据集中选取距离最近的 K 个点。
- 投票 (对于分类): 对于 K 个邻居,看哪个类别最为常见,并将其指定为新数据点的类别。
- 均值 (对于回归): 对于 K 个邻居,计算其属性的平均值,并将其指定为新数据点的值。
距离度量
欧几里得距离 (Euclidean Distance)
欧几里得距离的名称来源于古希腊数学家欧几里得,是衡量两点在平面或更高维空间中的"直线"距离。它基于勾股定理,用于计算两点之间的最短距离。在日常生活中,我们经常无意识地使用欧几里得距离,例如,当我们说两地之间的"直线"距离时,实际上是在引用欧几里得距离。
公式:
给定两点 P 和 Q,其坐标分别为 \(P(x_1, x_2, ..., x_n)\) 和 \(Q(y_1, y_2, ..., y_n)\) 在一个 n 维空间中,它们之间的欧几里得距离 d 定义为:
\(d(P, Q) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2}\)
曼哈顿距离 (Manhattan Distance)
曼哈顿距离得名于纽约的曼哈顿,因为在曼哈顿的街道布局是网格状的。想象一下,你在一个街区的一个角落,要走到对面的角落,你不能直接穿越街区,只能沿着街道走。这就是曼哈顿距离的来源,也因此它有时被称为“城市街区距离”。
公式
给定两点 P 和 Q,其坐标分别为 \(P(x_1, x_2, ..., x_n)\) 和 \(Q(y_1, y_2, ..., y_n)\) 在一个 n 维空间中,它们之间的曼哈顿距离 L1 定义为:
\(L1(P, Q) = \sum_{i=1}^{n} |x_i - y_i|\)
闵可夫斯基距离 (Minkowski Distance)
闵可夫斯基距离是一种在向量空间中度量两个点之间距离的方法。它实际上是一种泛化的距离度量,可以看作是其他距离度量(如欧几里得距离、曼哈顿距离)的泛化。通过改变一个参数p,它可以表示多种距离度量。
公式
给定两点 P 和 Q,其坐标分别为 \(P(x_1, x_2, ..., x_n)\) 和 \(Q(y_1, y_2, ..., y_n)\) 在一个 n 维空间中,它们之间的闵可夫斯基距离 Lp 定义为:
\(Lp(P, Q) = \left( \sum_{i=1}^{n} |x_i - y_i|^p \right)^{\frac{1}{p}}\)
其中 p 是一个大于等于 1 的实数。特定的 p 值会导致其他常见的距离度量:
- 当
p = 1时,这变成了曼哈顿距离。 - 当
p = 2时,这变成了欧几里得距离。
余弦相似性 (Cosine Similarity)
余弦相似性度量了两个向量方向的相似度,而不是它们的大小。换句话说,它是通过比较两个向量之间的夹角来测量它们的相似性的。夹角越小,相似性就越高。
它经常在高维空间中(如 TF-IDF 权重的文档向量)使用,因为在高维空间中,基于欧几里得距离的相似性度量可能不太有效。
公式
给定两个向量 A 和 B,它们的余弦相似性定义为:
\(\text{cosine similarity}(A, B) = \frac{A \cdot B}{\|A\| \|B\|}\)
其中:
- \(A \cdot B\) 是向量
A和B的点积。 - \(\|A\|\) 和 \(\|B\|\) 分别是向量
A和B的欧几里得长度(或模)。
公式可以进一步扩展为:
\(\text{cosine similarity}(A, B) = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}}\)
这里,n 是向量的维度,而 \(A_i\) 和 \(B_i\) 分别是向量 A 和 B 在第 i 维度上的值。
余弦相似性值范围为[-1, 1],其中 1 表示完全相似,0 表示不相关,而-1 表示完全相异。
K 值的确定方法:
交叉验证: 这是确定 k 值的最常用方法。对于每一个可能的 k 值,使用交叉验证计算模型的预测错误率,选择错误率最低的 k 值。
启发式方法: 有时,可以选择 sqrt(n)作为起始点,其中 n 是训练样本的数量。这只是一个粗略的估计,通常需要进一步验证。
误差曲线: 画出不同 k 值对应的误差率曲线,选择误差变化开始平稳的点。
领域知识: 在某些应用中,基于领域知识和经验选择 k 值可能更为合适。
K 值的影响:
过小的 k 值:
- 分类:模型可能变得过于敏感和复杂。它可能对训练数据中的噪声或异常点特别敏感,从而容易过拟合。当 k=1 时,任何训练数据中的异常点都可能影响预测结果。
- 回归:模型可能会受到异常值的强烈影响,导致预测结果出现明显的波动。
过大的 k 值:
- 分类:模型可能变得过于简化。随着 k 值的增加,分类决策的边界会变得更加平滑,可能会忽视数据中的细微模式,导致欠拟合。
- 回归:模型同样可能会过于简化。大 k 值使模型的预测偏向于所有数据点的平均值,因此可能会忽视数据中的局部特性或细节。
优缺点
优点
简单且直观。
无需训练阶段,适用于动态变化的数据集。
对异常值不敏感(取决于 K 的大小)。
缺点
计算复杂度高,因为对于每一个新的数据点,都需要与所有训练数据计算距离。
需要决定 K 的大小,这可能会影响结果。
高维数据中的性能下降。
应用场景:
推荐系统:
- 基于用户之前的喜好推荐相似电影
- 推荐用户可能喜欢的曲目或歌手
文本分类:
区分垃圾邮件和正常邮件。图像识别: 识别包括上的手写邮政编码,分类投递邮件包裹
医疗诊断: 预测患者可能的疾病风险。
信用评分:预测客户的信用风险。
欺诈检测:识别信用卡中的异常交易。
位置基服务:基于位置提供餐厅或服务推荐。
机器学习|K邻近(K Nearest-Neighbours)的更多相关文章
- 机器学习基础——简单易懂的K邻近算法,根据邻居“找自己”
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天的文章给大家分享机器学习领域非常简单的模型--KNN,也就是K Nearest Neighbours算法,翻译过来很简单,就是K最近邻居 ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- 机器学习算法及代码实现–K邻近算法
机器学习算法及代码实现–K邻近算法 1.K邻近算法 将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近 ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
随机推荐
- SQL Server 数据库字符串分割函数
SQL Server 数据库字符串分割函数,源代码如下: ALTER FUNCTION [dbo].[f_split] ( @SourceStr VARCHAR(MAX), -- 源字符串 @Spli ...
- 一文学会TextureID渲染到Surface
最近遇到一个需求,要求将一个GL_TEXTURE_2D类型的纹理ID写入到ImageReader生成的Surface中. 其实这个需求与我之前写过的一篇文章 一文学会MediaCodeC与OpenGL ...
- 【SpringBoot】Session共享
本文参考 Spring Boot 一个依赖搞定 session 共享,没有比这更简单的方案了! 在传统的单服务架构中,只有一个服务器,那就不会存在session共享的问题,但如果在分布式/集群项目中, ...
- String、StringBuffer、StringBuilder 的区别?
一. 介绍 String.StringBuffer.StringBuilder: 前言: String.StringBuffer.StringBuilder 均在java.lang包下: String ...
- Linux安装与配置FTP服务
1.FTP安装与配置 1.1.FTP安装 一般使用yum直接在线安装 # 在线安装FTP yum install -y vsftpd 安装完成后查看ftp状态 # 查看ftp状态 systemctl ...
- 用 Tensorflow.js 做了一个动漫分类的功能(二)
前言: 前面已经通过采集拿到了图片,并且也手动对图片做了标注.接下来就要通过 Tensorflow.js 基于 mobileNet 训练模型,最后就可以实现在采集中对图片进行自动分类了. 这种功能在应 ...
- NOIP2022 题解
终于有机会补NOIP的题了 T1 考虑枚举 C 与 F 的纵列 考虑预处理出每个点最左边和最下边可以延伸到哪 之后枚举列,然后对行做类似于扫描线的操作,统计有多少可行的 "第一横行" ...
- 如何正确使用:has和:nth-last-child
我们可以用CSS检查,以了解一组元素的数量是否小于或等于一个数字.例如,一个拥有三个或更多子项的grid.你可能会想,为什么需要这样做呢?在某些情况下,一个组件或一个布局可能会根据子元素的数量而改变. ...
- Log4j的Maven依赖及其配置文件
Maven配置 <!--Log4j依赖文件--> <dependency> <groupId>log4j</groupId> <artifactI ...
- [git]基于GitLab搭建本地Git服务
0.准备 (如果选择docker安装)Docker 系统:CentOS 7 1.安装部署GitLab 1.1.使用docker安装中文社区版GitLab 在docker上发现一个中文版的gitlab, ...