[HAOI2018] 字串覆盖
[HAOI2018]字串覆盖
题目描述
小C对字符串颇有研究,他觉得传统的字符串匹配太无聊了,于是他想到了这
样一个问题.
对于两个长度为n的串A, B, 小C每次会给出给出4个参数s, t, l, r. 令A从s到t的
子串(从1开始标号)为T,令B从l到r的子串为P.然后他会进行下面的操作:
如果T的某个子串与P相同,我们就可以删掉T的这个子串,并获得K − i的收
益,其中i是初始时A中(注意不是T中)这个子串的起始位置,K是给定的参数.
删除操作可以进行任意多次,你需要输出获得收益的最大值.
注意每次询问都是独立的,即进行一次询问后,删掉的位置会复原.
输入格式
从文件cover.in中读入数据.
第一行两个整数n, K,表示字符串长度和参数.
接下来一行一个字符串A.
接下来一行一个字符串B.
接下来一行一个整数q,表示询问个数.
接下来q行,每行四个整数s, t, l, r,表示一次询问.
输出格式
输出到文件cover.out中.
输出q行,每行一个整数,表示一个询问的答案.
样例 #1
样例输入 #1
10 11
abcbababab
ababcbabab
5
1 9 7 9
3 10 8 10
1 10 1 2
5 7 2 3
1 5 3 6
样例输出 #1
6
10
22
5
10
提示
样例1解释 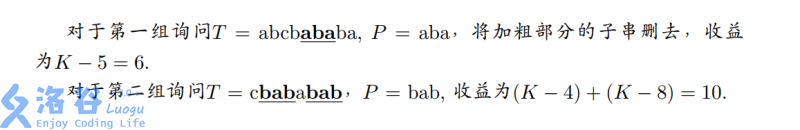
子任务
对于所有数据,有 $ 1 ≤ n, q ≤ 10^5 $ ,A, B仅由小写英文字母组成,$ 1 ≤ s ≤ t ≤n $ , $ 1 ≤ l ≤ r ≤ n $ , $ n < K ≤ 10^9 $ .
HAOI2018 round1 T3
对于 $ n = 10^5 $ 的测试点,满足\(51≤r−l≤2*10^3\) 的询问不超过11000个,且r−l在该区间内均匀随机
作为一道省选压轴题,这题还是偏简单的。
有一个很显然的贪心:一定是尽量地往前选,选越多越好。因为 \(k>n\),同时选的 \(k-i\) 中 \(i\) 一定是越小越好。
见到这个数据范围,明显要求我们分类分成 \(r-l>50\) 和 \(r-l\le 50\) 来处理
\(r-l>50\) 的方法就非常板子了。容易发现当 \(r-l>2000\) 的时候,选的串的个数一定不超过 $|S|\div(r-l)\le50 $,这就变成了一个字符串题。对S 建 SAM 后,找到 T[l...r] 所对应的等价类。怎么找等价类呢?可以建SAM 时把两个串连在一起建,然后在两个串中间放一些特殊字符,然后只要找到 \(T\) 对应的等价类就可以了。可以在 SAM 上用线段树合并维护等价类出现位置,然后每次线段树二分出下一个选的地方在哪就行了。而在 \(51\le r-l\le 2000\) 时,串的个数不超过 \(|S|\div r-l\le 2000\),同时询问还只有 \(11000\) 次,带个 log 3s 还是跑的过去的。
当 \(r-l\le 50\) 的时候,考虑把所有串给找出来跑。枚举所有长度不超过 50 的串,然后把那些一样的给找出来。对于每个询问,可以用倍增去统计就行了。
#include<bits/stdc++.h>
#define vit vector<int>::iterator
using namespace std;
typedef long long LL;
const int N=1e5+5,INF=2e9;
int k,n,TME,tme,nx[N][20];
LL ans[N],ns[N][20];
char s[N],t[N];
vector<int>p[51],q[N<<2],g[N];
string str;
map<string,int>mp;
struct query{
int l,r,s,t,id;
}qu[N];
template<int N>struct segment{
int tr[N],lc[N],rc[N],idx;
void update(int&o,int l,int r,int x)
{
if(!o)
o=++idx;
if(l==r)
return;
int md=l+r>>1;
if(md>=x)
update(lc[o],l,md,x);
else
update(rc[o],md+1,r,x);
}
int merge(int p,int q)
{
if(!p||!q)
return p|q;
lc[p]=merge(lc[p],lc[q]);
rc[p]=merge(rc[p],rc[q]);
return p;
}
int erfen(int o,int l,int r,int x)
{
if(!o)
return INF;
if(x>r)
return INF;
if(l==r)
return l;
int md=l+r>>1,k;
if((k=erfen(lc[o],l,md,x))^INF)
return k;
return erfen(rc[o],md+1,r,x);
}
};
template<int N,int M> struct graph{
struct edge{
int v,nxt;
}e[M];
int hd[N],e_num;
void add_edge(int u,int v)
{
e[++e_num]=(edge){v,hd[u]};
hd[u]=e_num;
}
};
template<int N>struct SAM{
int tr[N<<1][27],l[N<<1],fil[N<<1][21],idx=1,ls=1,g[N],rt[N<<1];
segment<N*60> s;
graph<N<<1,N<<1>t;
void insert(int s)
{
int k=++idx,p=ls;
g[l[k]=l[ls]+1]=k,ls=k;
SAM::s.update(rt[k],1,2*n+1,l[k]);
while(p&&!tr[p][s])
tr[p][s]=k,p=fil[p][0];
if(!p)
fil[k][0]=1;
else
{
int q=tr[p][s];
if(l[q]==l[p]+1)
fil[k][0]=q;
else
{
int nw=++idx;
l[nw]=l[p]+1,fil[nw][0]=fil[q][0];
memcpy(tr[nw],tr[q],sizeof(tr[0]));
fil[q][0]=fil[k][0]=nw;
while(p&&tr[p][s]==q)
tr[p][s]=nw,p=fil[p][0];
}
}
}
void dfs(int x)
{
for(int i=1;i<=20;i++)
fil[x][i]=fil[fil[x][i-1]][i-1];
for(int i=t.hd[x];i;i=t.e[i].nxt)
dfs(t.e[i].v);
}
void build()
{
for(int i=2;i<=idx;i++)
t.add_edge(fil[i][0],i);
dfs(1);
}
void sou(int x)
{
for(int i=t.hd[x];i;i=t.e[i].nxt)
{
sou(t.e[i].v);
rt[x]=s.merge(rt[x],rt[t.e[i].v]);
}
for(int i=0;i<q[x].size();i++)
{
int len=qu[q[x][i]].r-qu[q[x][i]].l,lst=qu[q[x][i]].s+len,c=0;
LL sum=0;
while(1)
{
int k=s.erfen(rt[x],1,n+n+1,lst);
if(k>qu[q[x][i]].t)
break;
sum+=k-len,++c;
lst=k+len+1;
}
ans[q[x][i]]=1LL*c*k-sum;
}
}
void add(int r,int len,int x)
{
int k=g[r];
for(int i=20;i>=0;i--)
if(l[fil[k][i]]>=len)
k=fil[k][i];
q[k].push_back(x);
}
};
SAM<N<<1>sm;
int main()
{
scanf("%d%d%s%s%d",&n,&k,s+1,t+1,&TME);
for(int i=1;i<=n;i++)
sm.insert(s[i]-'a');
sm.insert(26);
for(int i=1;i<=n;i++)
sm.insert(t[i]-'a');
sm.build();
for(int i=1;i<=TME;i++)
{
scanf("%d%d%d%d",&qu[i].s,&qu[i].t,&qu[i].l,&qu[i].r);
qu[i].id=i;
if(qu[i].r-qu[i].l<=50)
p[qu[i].r-qu[i].l].push_back(i);
else
sm.add(n+1+qu[i].r,qu[i].r-qu[i].l+1,i);
}
for(int i=0;i<=50;i++)
{
for(int i=1;i<=tme;i++)
g[i].clear();
tme=0;
mp.clear();
for(int j=1;j+i<=n;j++)
{
str="";
for(int k=j;k<=j+i;k++)
str.push_back(s[k]);
if(!mp[str])
mp[str]=++tme;
g[mp[str]].push_back(j);
}
for(int i=0;i<=n+1;i++)
for(int j=0;j<20;j++)
nx[i][j]=n+1,ns[i][j]=0;
for(int j=1;j<=tme;j++)
{
for(int k=0;k<g[j].size();k++)
{
vector<int>::iterator it=upper_bound(g[j].begin(),g[j].end(),g[j][k]+i);
if(it!=g[j].end())
ns[g[j][k]][0]=nx[g[j][k]][0]=*it;
}
}
for(int i=n;i>=0;i--)
for(int j=1;j<20;j++)
ns[i][j]=ns[i][j-1]+ns[nx[i][j-1]][j-1],nx[i][j]=nx[nx[i][j-1]][j-1];
for(int j=0;j<p[i].size();j++)
{
str="";
for(int k=qu[p[i][j]].l;k<=qu[p[i][j]].r;k++)
str.push_back(t[k]);
if(mp[str])
{
int k=mp[str];
vit it=lower_bound(g[k].begin(),g[k].end(),qu[p[i][j]].s);
if(it!=g[k].end()&&(*it)+i<=qu[p[i][j]].t)
{
int nw=*it,ret=1;
LL s=nw;
for(int k=19;k>=0;k--)
if(nx[nw][k]+i<=qu[p[i][j]].t)
ret+=1<<k,s+=ns[nw][k],nw=nx[nw][k];
ans[p[i][j]]=1LL*ret*::k-s;
}
}
}
}
sm.sou(1);
for(int i=1;i<=TME;i++)
printf("%lld\n",ans[i]);
return 0;
}
[HAOI2018] 字串覆盖的更多相关文章
- 【BZOJ5304】[HAOI2018]字串覆盖(后缀数组,主席树,倍增)
[BZOJ5304][HAOI2018]字串覆盖(后缀数组,主席树,倍增) 题面 BZOJ 洛谷 题解 贪心的想法是从左往右,能选就选.这个显然是正确的. 题目的数据范围很好的说明了要对于询问分开进行 ...
- BZOJ5304 : [Haoi2018]字串覆盖
离线处理所有询问. 对于$r-l\leq 50$的情况: 按照串长从$1$到$51$分别把所有子串按照第一位字符为第一关键字,上一次排序结果为第二关键字进行$O(n)$基数排序. 同理也可以用上一次比 ...
- 洛谷P4493 [HAOI2018]字串覆盖(后缀自动机+线段树+倍增)
题面 传送门 题解 字符串就硬是要和数据结构结合在一起么--\(loj\)上\(rk1\)好像码了\(10k\)的样子-- 我们设\(L=r-l+1\) 首先可以发现对于\(T\)串一定是从左到右,能 ...
- 「HAOI2018」字串覆盖
「HAOI2018」字串覆盖 题意: 给你两个字符串,长度都为\(N\),以及一个参数\(K\),有\(M\)个询问,每次给你一个\(B\)串的一个子串,问用这个字串去覆盖\(A\)串一段区间的最 ...
- 【LOJ】#2525. 「HAOI2018」字串覆盖
题解 写后缀树真是一写就好久,然后调好久QAQ 我们把两个串取反拼一起建后缀树,这样的话使得后缀树是正串的后缀树 然后我们把询问挂在每个节点上,每次线段树合并,对于大于50的每次暴力跳着在线段树找,对 ...
- 最大公共字串LCS问题(阿里巴巴)
给定两个串,均由最小字母组成.求这两个串的最大公共字串LCS(Longest Common Substring). 使用动态规划解决. #include <iostream> #inclu ...
- 编程:使用递归方式判断某个字串是否回文(Palindrome)
Answer: import java.util.Scanner; public class Palindrome { private static int len;//全局变量整型数据 privat ...
- NOIP2002字串变换[BFS]
题目描述 已知有两个字串 A$, B$ 及一组字串变换的规则(至多6个规则): A1$ -> B1$ A2$ -> B2$ 规则的含义为:在 A$中的子串 A1$ 可以变换为 B1$.A2 ...
- 字串符相关 split() 字串符分隔 substring() 提取字符串 substr()提取指定数目的字符 parseInt() 函数可解析一个字符串,并返回一个整数。
split() 方法将字符串分割为字符串数组,并返回此数组. stringObject.split(separator,limit) 我们将按照不同的方式来分割字符串: 使用指定符号分割字符串,代码如 ...
- mormot 数据集转换为JSON字串
mormot 数据集转换为JSON字串 unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graph ...
随机推荐
- C#程序随系统启动例子 - 开源研究系列文章
今天讲讲C#中应用程序随系统启动的例子. 我们知道,应用程序随系统启动,都是直接在操作系统注册表中写入程序的启动参数,这样操作系统在启动的时候就根据启动参数来启动应用程序,而我们要做的就是将程序启动参 ...
- Zimbra禁止接收带有加密的文件邮件 提醒病毒(Heuristics.Encrypted.PDF)
最近碰到一个国际性大客户,一定要发送经过加密的文件,因为是合约相关的文件,对方公司有这方面要求.但是Zimbra默认是禁止接收加密的文件 - 'Block encrypted archives',这样 ...
- 混合开发模式是否可以在App备案制度下突围
网站 ICP 备案已施行了很久,我们也非常清楚必须在进行 ICP 备案后,网站才能在大陆范围合法运营,并且用户可以通过域名正常访问网站. 但是月初出了新规,明年起,国内的 App 也要像网站一样进行备 ...
- Oracle数据库字符集概述及修改方式
1.字符集概述 Oracle语言环境的描述包括三部分:language.territory.characterset(语言.地域.字符集) language:主要指定服务器消息的语言,提示信息显示中文 ...
- uni微信小程序隐私协议
最近小程序又新增了个 隐私协议弹窗.需要用户去授权,官网的一些API才能使用.官网地址 功能展示 项目地址:https://ext.dcloud.net.cn/plugin?id=14358 1.ma ...
- KRPano JS 场景编辑器源码
KRPano JS编辑器,可以运行在Node环境中. 源码地址:https://github.com/xxweimei/krpano-editor-js 或者下载zip包:http://pan.bai ...
- oracle 12C提示:ORA-28001口令已经失效
oracle 12C 提示口令已经失效,此用户是pdb用户,解决办法:1 系统管理员身份登陆 sqlplus / as sysdba 2 转到对应的pdb容器中 alter session set c ...
- 计算机三级网络技术备考复习资料zhuan
计算机三级网络技术备考复习资料 第一章 计算机基础 分析:考试形式:选择题和填空题,6个的选择题和2个填空题共10分,都是基本概念 1.计算机的四特点:有信息处理的特性,有广泛适应的特性,有 ...
- 漏洞扫描与安全加固之Apache Axis组件
一.Apache Axis组件高危漏洞自查及整改 Apache Axis组件存在由配置不当导致的远程代码执行风险. 1. 影响版本 Axis1 和Axis2各版本均受影响 2. 处置建议 1)禁用此服 ...
- Unity - UIWidgets 1. 从Hello world开始
安装参照github的README.UIWidgets相当于Flutter的一个Unity实现(后面表示UIWidgets和UGUI区别时直接称"Flutter"),是把承载的所有 ...