【01】DataFrame的创建和属性
DataFrame是一个表格型的数据结构,可以看成就是excel中的表格。
官方文档:https://pandas.pydata.org/docs/reference/frame.html
DataFrame的创建
DataFrame构造方法如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
- data:DataFrame的数据部分,可以是字典、二维数组、Series、DataFrame或其他可转换为DataFrame的对象,若不提供此参数,则创建一个空的DataFrame。
- index:DataFrame的行索引,用于标识每行数据,可以是列表、数组、索引对象等,若不提供此参数,则创建一个默认的整数索引。
- columns:DataFrame的列索引,用于标识每列数据。可以是列表、数组、索引对象等,若不提供此参数,则创建默认的整数索引。
- dtype:指定DataFrame的数据类型,可以是NumPy的数据类型,例如np.int64、np.float64等,若不提供此参数,则根据数据自动推断数据类型。
- copy:是否复制数据,默认为False,表示不复制数据,若设置为True,则复制输入的数据。
一维列表创建DataFrame
|
 |
二维列表创建DataFrame
|
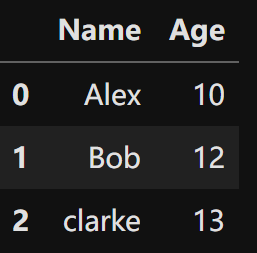 |
传递字典创建DataFrame
|
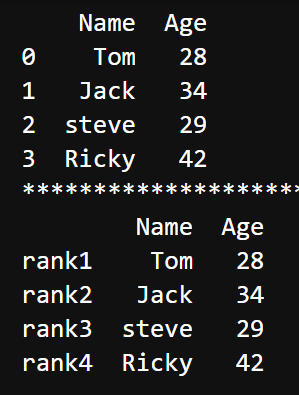 |
传递字典列表创建DataFrame
|
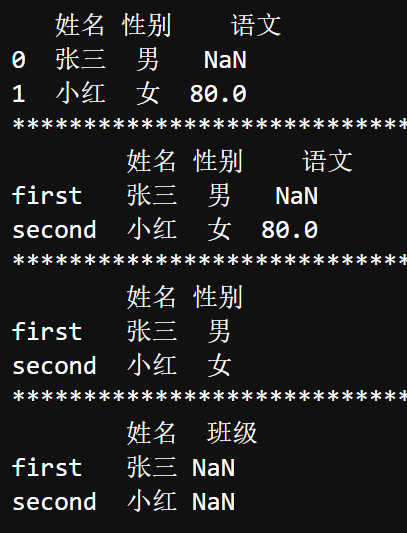 |
通过Series对象创建
|
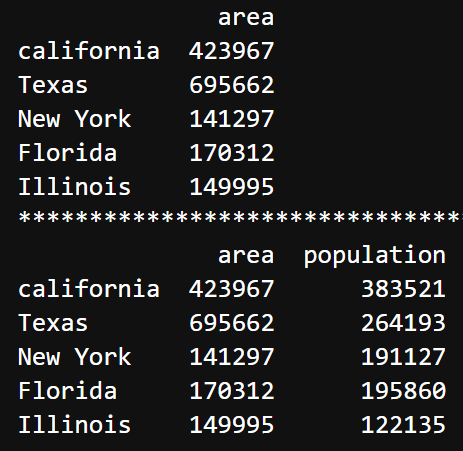 |
通过Numpy创建
|
 |
DataFrame的属性
dataframe.T
df.T属性主要用来转置行和列,和 df.transpose() 实现的效果一样。
|
 |
dataframe.axes
返回包含行索引和列索引的列表,可以通过 df.axes[0].tolist() 或 list(df.axes[0]) 转成行索引列表,列索引列表同理。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.axes) # [Index(['a', 'b', 'c'], dtype='object'), Index(['foo', 'bar'], dtype='object')]
print(df.axes[0].tolist()) # ['a', 'b', 'c']
print(list(df.axes[0])) # ['a', 'b', 'c']dataframe.dtypes
查看每列的数据类型。
|
 |
dataframe.ndim
获取DataFrame的维数。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.ndim) # 2dataframe.shape
获取DataFrame的行数和列数,是一个元组。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.shape) # (3, 2)dataframe.size
返回DataFrame中的元素个数。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.size) # 6dataframe.values
返回一个所有行数据组成的二维的数组,每个元素是一个一维数组(也就是一行数据),可以通过 list(df.values) 或 df.values.tolist() 转成python的列表类型。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
# 基于a数组建立DataFrame
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.values) # [[8 6] [3 3] [8 7]]
print(list(df.values)) # [array([8, 6], dtype=int32), array([3, 3], dtype=int32), array([8, 7], dtype=int32)]
print(df.values.tolist()) # [[8, 6], [3, 3], [8, 7]]dataframe.index
获取行索引,返回的是Index类型,可以通过 list(df.index) 或 df.index.tolist() 转换成列表。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.index) # Index(['a', 'b', 'c'], dtype='object')
print(df.index.values) # ['a' 'b' 'c']
print(list(df.index)) # ['a', 'b', 'c']
print(df.index.tolist()) # ['a', 'b', 'c']dataframe.columns
获取列索引,返回的是Index类型,可以通过 list(df.columns) 或 df.columns.tolist() 转换成列表。
import pandas as pd
import numpy as np
a = np.random.randint(1, 10, (3, 2))
df = pd.DataFrame(a, columns=['foo', 'bar'], index=['a', 'b', 'c'])
print(df)
print("*" * 50)
print(df.columns) # Index(['foo', 'bar'], dtype='object')
print(df.columns.values) # ['foo' 'bar'],可用 df.columns.values.tolist() 转换成列表
print(list(df.columns)) # ['foo', 'bar']
print(df.columns.tolist()) # ['foo', 'bar']【01】DataFrame的创建和属性的更多相关文章
- Pandas的基础操作(一)——矩阵表的创建及其属性
Pandas的基础操作(一)——矩阵表的创建及其属性 (注:记得在文件开头导入import numpy as np以及import pandas as pd) import pandas as pd ...
- 继承自UITableView的类自带tableView属性,不需要在创建该属性,因为父类UITableView已经创建.
继承自UITableView的类自带tableView属性,不需要在创建该属性,因为父类UITableView已经创建. https://www.evernote.com/shard/s227 ...
- JS对象—数组总结(创建、属性、方法)
JS对象—数组总结(创建.属性.方法) 1.创建字符串 1.1 new Array() var arr1 = new Array(); var arr2 = new Array(6); 数组的长度为6 ...
- Python 中使用动态创建类属性的机制实现接口之后的依赖
我们在自动化测试中经常会需要关联用例处理,需要动态类属性: 推荐使用第二种方法: 创建:setattr() 获取:getattr() 两种,如何创建 类属性 loan_id # 第一种,创建 # 类名 ...
- DataFrame的创建
DataFrame的创建从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载.转换 ...
- 原创:MVC 5 实例教程(MvcMovieStore 新概念版:mvc5.0,EF6.01) - 4、创建数据上下文和数据实体模型
说明:MvcMovieStore项目已经发布上线,想了解最新版本功能请登录 MVC影视(MvcMovie.cn) 进行查阅.如需转载,请注明出处:http://www.cnblogs.com/Dodu ...
- 大数据学习day24-------spark07-----1. sortBy是Transformation算子,为什么会触发Action 2. SparkSQL 3. DataFrame的创建 4. DSL风格API语法 5 两种风格(SQL、DSL)计算workcount案例
1. sortBy是Transformation算子,为什么会触发Action sortBy需要对数据进行全局排序,其需要用到RangePartitioner,而在创建RangePartitioner ...
- CSS.01 -- 选择器及相关的属性文本、文字、字体、颜色、
与html相比,Css支持更丰富的文档外观,Css可以为任何元素的文本和背景设置颜色:允许在任何元素外围设置边框:允许改变文本的大小,装饰(如下划线),间隔,甚至可以确定是否显示文本. 什么是CSS? ...
- python中创建实例属性
虽然可以通过Person类创建出xiaoming.xiaohong等实例,但是这些实例看上除了地址不同外,没有什么其他不同.在现实世界中,区分xiaoming.xiaohong要依靠他们各自的名字.性 ...
- spark DataFrame的创建几种方式和存储
一. 从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载.转换.处理等功能.Sp ...
随机推荐
- 【Redis】06 事务
Redis事务 可以一次执行多个命令,本质是一组命令的集合. 一个事务中的 所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞 官方说明: https://redis.io/topi ...
- 阿里modelscope下载模型
个人上传的模型地址:(需要注意,这个模型参数只做测试之用,并无实际意义) https://modelscope.cn/models/devilmaycry812839668/devil/summary ...
- 对国产AI计算框架要有一定的包容力——记“mindspore”使用过程中的“不良反应”
看mindspore的官方文档,居然有502错误,恶心到了: 打开Eager模式的链接,报错:
- 高校教编程是否应该将Python作为主语言
偶读一文:https://www.cnblogs.com/qing-gee/p/12941219.html 想到了这样的一个老问题,个人搞计算机软件开发.人工智能的时间已经十余年,虽然个人能力有限但是 ...
- ×被替换成x 的解决办法
今天写代码遇到一个很有趣的问题: 在php中使用echo 输出url的时候当url中包含×字段时就会被html直接解析成 x (乘号)这样一来我返回的地址就不能正常访问url了: 解 ...
- 【CMake系列】05-静态库与动态库编译
在各种项目类型中,可能我们的项目就是一个 库 项目,向其他人提供 我们开发好的 库 (windows下的 dll /lib : linux下的 .a / .so):有时候在一个项目中,我们对部分功能 ...
- ChatGPT学习之旅 (9) 系统运维小助手
大家好,我是Edison. 上一篇我们写了一个单元测试助手的prompt,它帮我们写一些我们开发者不太愿意编写的单元测试代码,在我最近一个月的实践中我再也没有手写过单元测试,更多地只是在AI生成的代码 ...
- TwinCAT3 - 实现自己的Tc2_SerialCom
目录 1,前言 2,原生Tc2_SerialCom简单使用 3,实现自己的Tc2_SerialCom 3.1,EL6inData22B,EL6outData22B 3.2,ComBuffer 3.3, ...
- echarts x轴下绘制表
效果图: 把下面代码复制到官网实例的js代码编辑中即可预览( 附连接:Examples - Apache ECharts) let map = { 销售单价: [2200.0,4000.9,700.0 ...
- 查看 Linux 系统信息
查看系统信息 查看发行版信息 cat /etc/os-release lsb_release -a 查看公网 IP 地址 curl -4 icanhazip.com 查看系统架构 uname -m # ...