深入理解Kafka核心设计及原理(六):Controller选举机制,分区副本leader选举机制,再均衡机制
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/15026824.html
目录:
6.1.Kafka核心总控制器Controller
6.2.Controller选举机制
6.3.Partition副本选举Leader机制
6.4.消费者消费消息的offset记录机制
6.5.消费者Rebalance机制
6.6.消费者Rebalance分区分配策略
kafka 集群拓扑结构:
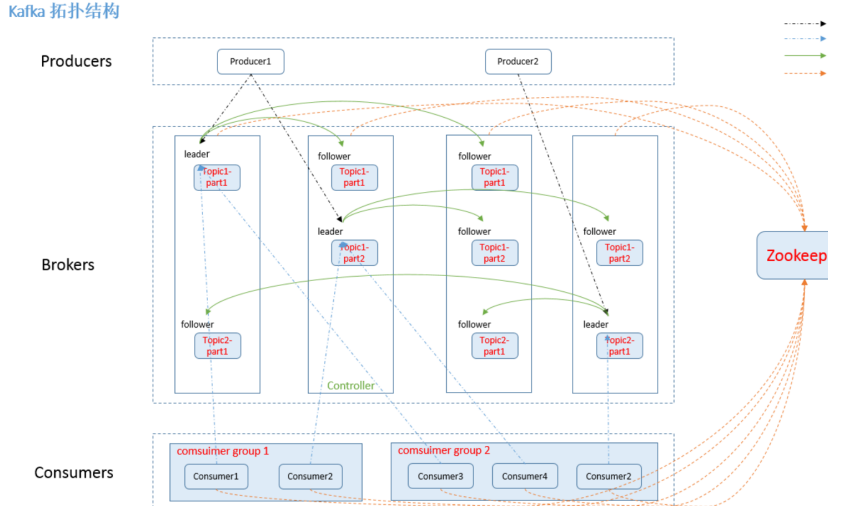
6.1.Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
6.2.Controller选举机制
在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点,zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。
当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
1. 监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
2. 监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
3. 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
4. 更新集群的元数据信息,同步到其他普通的broker节点中。
6.3.Partition副本选举Leader机制
controller感知到分区leader所在的broker挂了(controller监听了很多zk节点可以感知到broker存活),controller会从每个parititon的 replicas 副本列表中取出第一个broker作为leader,当然这个broker需要也同时在ISR列表里。这也成为副本优先机制;
6.4.消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给 kafka内部topic:__consumer_offsets,提交过去的时候,key是 consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据,因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
__consumer_offsets 的每条消息格式大致如图所示:
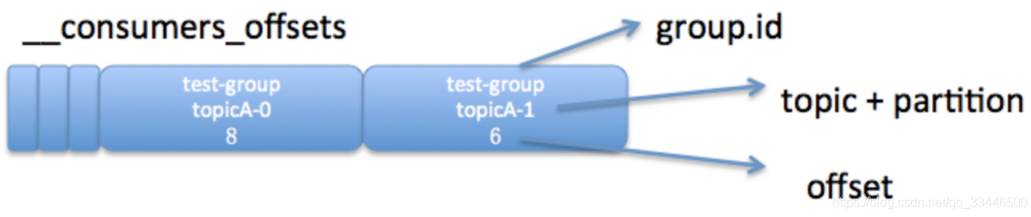
一般情况下,当集群中第一次有消费者消费消息时会自动创建 __consumer_offsets,它的副本因子受 offsets.topic.replication.factor 参数的约束,默认值为3
6.5.消费者Rebalance机制
消费者rebalance就是说如果consumer group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他如下情况可能会触发消费者rebalance
1. consumer所在服务重启或宕机了
2. 动态给topic增加了分区
3. 消费组订阅了更多的topic
Rebalance过程如下
当有消费者加入消费组时,消费者、消费组及组协调器之间会经历以下几个阶段。
第一阶段:选择组协调器
组协调器GroupCoordinator:每个consumer group都会选择一个broker作为自己的组协调器coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者rebalance。consumer group中的每个consumer启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。
组协调器选择方式:
通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区,这个分区leader对应的broker就是这个consumer group的coordinator
公式:hash(consumer group id) % __consumer_offsets主题的分区数 (50)
第二阶段:加入消费组JOIN GROUP
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。然后GroupCoordinator 从一个consumer group中选择第一个加入group的consumer作为leader(消费组协调器),把consumer group情况发送给这个leader,接着这个leader会负责制定分区方案。
第三阶段( SYNC GROUP)
consumer leader通过给GroupCoordinator发送SyncGroupRequest,接着GroupCoordinator就把分区方案下发给各个consumer,他们会根据指定分区的leader broker进行网络连接以及消息消费。
6.6.消费者Rebalance分区分配策略
主要有三种rebalance的策略:range、round-robin、sticky。
Kafka 提供了消费者客户端参数partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况为range分配策略。
假设一个主题有10个分区(0-9),现在有三个consumer消费:
range策略就是按照分区序号排序,假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。比如分区0~3给一个consumer,分区4~6给一个consumer,分区7~9给一个consumer。
round-robin策略就是轮询分配,比如分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、8给一个consumer
sticky策略就是在rebalance的时候,需要保证如下两个原则。
1)分区的分配要尽可能均匀 。
2)分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:
consumer1除了原有的0~3,会再分配一个7
consumer2除了原有的4~6,会再分配8和9
深入理解Kafka核心设计及原理(六):Controller选举机制,分区副本leader选举机制,再均衡机制的更多相关文章
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16124354.html 目录: 4.1创建主题 4.2 优先副本的选举 4.3 分区重分配 4.4 如何选择合 ...
- 深入理解Kafka核心设计及原理(五):消息存储
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16127749.html 目录: 5.1文件目录布局 5.2消息压缩 5.3日志索引 5.4日志文件及索引文件分 ...
- 深入理解Kafka核心设计及原理(二):生产者
转载请注明出处: 2.1Kafka生产者客户端架构 2.2 Kafka 进行消息生产发送代码示例及ProducerRecord对象 kafka进行消息生产发送代码示例: public class Ka ...
- Kafka高级设计和架构,一文深化理解
主题: 1.kafka是写磁盘还是写内存? 2.kafka究竟是由 consumer 从 broker 那里拉数据,还是由 broker 将数据推到 consumer? 3.如何区分已消费(consu ...
- 深入理解Kafka必知必会(2)
Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么? __consumer_offsets:作用是保存 Kafka 消费者的位移信息 __transaction_state:用来 ...
- 深入理解 Kafka 副本机制
一.Kafka集群 二.副本机制 2.1 分区和副本 2.2 ISR机制 2.3 不完全的首领选举 2.4 最少同步副本 ...
- Kafka 学习之路(五)—— 深入理解Kafka副本机制
一.Kafka集群 Kafka使用Zookeeper来维护集群成员(brokers)的信息.每个broker都有一个唯一标识broker.id,用于标识自己在集群中的身份,可以在配置文件server. ...
- Kafka 系列(五)—— 深入理解 Kafka 副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- 入门大数据---Kafka深入理解分区副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
随机推荐
- MySQL运维14-管理及监控工具Mycat-web的安装配置
一.Mycat-web介绍 Mycat-web(现改名为Mycat-eye)是对Mycat-server提供监控服务,通过JDBC连接对Mycat,MySQL监控,监控远程服务器的cpu,内存,网络, ...
- python tkinter使用(九)
python tkinter使用(九) 本文主要讲下scrolledText中图片的插入,以及常见的错误. 使用Image.open来打开图片 使用ImageTk.PhotoImage()方法将图片转 ...
- Odoo Windows系统下部署方法
Windows 系统下 Odoo 环境搭建流程 ① 安装python2.7 安装完成后 在命令行(cmd)输入python 如果不出现内部错误提示则表示环境配置成功 当出现错误时要设置环境变量 ...
- 【云原生 | Kubernetes 系列】— Kubernetes存储方案
目录 [云原生 | Kubernetes 系列]- Kubernetes存储方案 一.基本存储 EmptyDir HostPath NFS 搭建nfs服务器 二.高级存储 PV和PVC pv pvc ...
- flutter常用的音乐播放器库
audioplayers: 优势:audioplayers 是一个简单易用的音乐播放器库,支持主流平台(Android.iOS)并提供了丰富的功能,比如播放.暂停.快进.音量控制等. 缺点:audio ...
- 容器中域名解析流程以及不同dnsPolicy对域名解析影响
本文分享自华为云社区<容器中域名解析流程以及不同dnsPolicy对域名解析影响>,作者:可以交个朋友 . 一.coreDNS背景 部署在kubernetes集群中的容器业务通过coreD ...
- Istio与Kubernetes:资源管理与协同解析
本文分享自华为云社区<istio资源介绍以及和kubernetes资源扭转关系>,作者:可以交个朋友. 一.istio原理 Istio的原理是拦截 Kubernetes 中创建 Pod 的 ...
- 华为云举办AI经典论文复现活动,打造领先AI开发者学习社区
摘要:百余篇经典论文算法上线华为云AI Gallery,学AI就用ModelArts 2020年8月28日,华为云AI院长峰会在杭州千岛湖举行,来自中国科学院.中国工程院的多位院士,以及清华大学.北京 ...
- 火山引擎 DataTester 为企业降本增效:1 个人也能成为一支 A/B 实验团队
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 今年天猫电商.京东均表示交易规模与 2021 年持平,跟往年急剧增长的销售额相比,今年的双十一显得略微" ...
- PPT 图片8大操作技巧
如何实现图片的批量导入 插入相册 图片批量导出 7z 直接解压 修改扩展名 -> 解压 PPT 抠图 设备透明色 删除背景色 二次曝光效果 低版本 office 通过,形状来实现 图片融入背景 ...