二叉树的遍历(BFS、DFS)
二叉树的遍历(BFS、DFS)
本文分为以下部分:
BFS(广度优先搜索)
广度优先搜索[^1](英语:Breadth-First Search,缩写为BFS),又译作宽度优先搜索,或横向优先搜索,是一种图形搜索算法。简单的说,BFS是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。广度优先搜索的实现一般采用open-closed表。
先遍历每层的节点,优先对相邻节点做相同操作,再对下一层进行操作,直到所有操作完成。
简单来说就是一层一层的进行操作,横向操作。
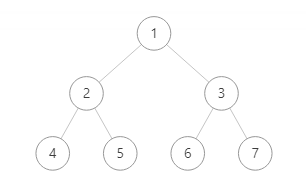
例如上图,用广度优先搜索算法将节点值输出,则输出结果为 1 2 3 4 5 6 7
第一层输出 1 ,然后输出第二层 2 3 ,最后输出第三层 4 5 6 7
实现方法:
(队列先进先出原则)
首先定义一个单端队列,将根节点加入队列中
判断队列是否为空,不为空则取出队列的第一个节点,输出节点的值,将节点的左、右节点加入队列中
重复第二步,直到队列为空
e.g.
- 定义一个单端队列queue,将根节点 1 加入队列中
- 从队列中取出节点 1 ,输出节点的的值 1 ,将节点 2 、3 加入队列中
- 由于队列先进先出特性,所以取出节点 2 , 输出节点值 2 ,将节点 4 、5 加入队列
- 此时取出的是节点 3,输出节点值 3 ,将节点 6 、7 加入队列
- ......
最终输出为 1 2 3 4 5 6 7
public class ErgodicTree {
@Test
public void test(){
Node root = new Node(1);
Node node = new Node(2);
Node node1 = new Node(3);
Node node2 = new Node(4);
Node node3 = new Node(5);
Node node4 = new Node(6);
Node node5 = new Node(7);
root.setLeft(node);
root.setRight(node1);
node.setLeft(node2);
node.setRight(node3);
node1.setLeft(node4);
node1.setRight(node5);
this.bfs(root);
}
//广度优先搜索
//1 => 2 => 3 => 4 => 5 => 6 => 7 =>
public void bfs(Node node){
Queue<Node> queue = new LinkedList<Node>();
//将根节点加入队列中
queue.offer(node);
while (!queue.isEmpty()){
//获取队列的第一个节点
Node poll = queue.poll();
if(poll != null){
//输出获取到的节点值
System.out.print(poll.getValue() + " => ");
//将该节点的左侧节点加入队列中
queue.offer(poll.getLeft());
//将该节点的右侧节点加入队列中
queue.offer(poll.getRight());
}
}
}
}
//节点定义
class Node{
private int value;
private Node left;
private Node right;
public Node(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
}
DFS(深度优先搜索)
深度优先搜索算法[^1](英语:Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法。这个算法会尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
遍历一列的节点,再对下一列的节点进行操作,直到所有操作完成
简单来说就是一列一列的进行操作,纵向操作。
先序遍历
(先)根左右
每次遍历都先根,再遍历左子树,再遍历右子树,依旧以上图为例
- 先根节点,输出 1
- 再遍历左子树,左子树为 2 4 5
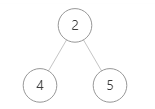
- 遍历左子树的根节点,输出 2
- 再遍历左子树,左子树为单独的 4 ,所以输出 4
- 2 的左子树遍历完,再遍历 2 的右子树,右子树为单独的 5 ,所以输出 5
- 1 的左子树遍历完,回溯遍历 1 的右子树,右子树为 3 6 7

- 遍历右子树依旧为先 根左右 ,根为 3 ,输出 3
- 再遍历左子树,左子树为单独的6,所以输出 6
- 3 的左子树遍历完,再遍历 3 的右子树,右子树为单独的 7 ,所以输出 7
整个树遍历完了,所以最终输出的是 1 2 4 5 3 6 7
代码实现
public class ErgodicTree {
@Test
public void test(){
Node root = new Node(1);
Node node = new Node(2);
Node node1 = new Node(3);
Node node2 = new Node(4);
Node node3 = new Node(5);
Node node4 = new Node(6);
Node node5 = new Node(7);
root.setLeft(node);
root.setRight(node1);
node.setLeft(node2);
node.setRight(node3);
node1.setLeft(node4);
node1.setRight(node5);
this.preOrder(root);
}
//先序遍历
//1 => 2 => 4 => 5 => 3 => 6 => 7 =>
public void preOrder(Node node){
if(node != null){
//输出当前节点
System.out.print(node.getValue() + " => ");
//遍历左子树
preOrder(node.getLeft());
//遍历右子树
preOrder(node.getRight());
}
}
}
class Node{
private int value;
private Node left;
private Node right;
public Node(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
}
中序遍历
(中)根左右,即 左根右
先序遍历是先根左右,中序遍历是中根左右,即左根右,左子树,根节点,再右子树,以最开始的图为例
- 先遍历根节点 1 的左子树 2 4 5
- 由于节点 2 还有左子树,所以先遍历 2 的左子树
- 左子树为单独的 4 ,4 没有左子树(若存在左子树,则需要继续往下递推),所以输出 4
- 2 的左子树遍历完,输出 2 的根节点自己,输出 2
- 2 的右子树依旧为 1 的左子树的部分,所以先遍历 2 的右子树
- 2右子树为单独的 5,5 没有左子树,所以输出 5
- 1 的左子树都遍历完了,该遍历 1 的根节点了,输出 1
- 再遍历 1 的右子树 3 6 7,右子树的遍历依旧遵循左根右
- 由于节点 3 还有左子树,所以先遍历 3 的左子树
- 左子树为单独的 6 ,6 没有他左子树,所以输出 6
- 3 的左子树遍历完,输出 3 的根节点自己,输出 3
- 接着遍历 3 的右子树
- 右子树为单独的 7,7 没有左子树,所以输出 7
最终输出为 4 2 5 1 6 3 7
代码实现
public class ErgodicTree {
@Test
public void test(){
Node root = new Node(1);
Node node = new Node(2);
Node node1 = new Node(3);
Node node2 = new Node(4);
Node node3 = new Node(5);
Node node4 = new Node(6);
Node node5 = new Node(7);
root.setLeft(node);
root.setRight(node1);
node.setLeft(node2);
node.setRight(node3);
node1.setLeft(node4);
node1.setRight(node5);
this.midOrder(root);
}
//中序遍历
//4 => 2 => 5 => 1 => 6 => 3 => 7 =>
public void midOrder(Node node){
if(node != null){
//先遍历左子树
midOrder(node.getLeft());
//输出当前节点
System.out.print(node.getValue() + " => ");
//遍历右子树
midOrder(node.getRight());
}
}
}
class Node{
private int value;
private Node left;
private Node right;
public Node(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
}
后序遍历
(后)根左右,即 左右根
后序遍历就是根在最后遍历,顺序为左右根,即左子树,右子树,根节点,依旧以最初的图为例
- 先遍历根节点 1 的左子树 2 4 5
- 由于节点 2 还有左子树,所以先遍历 2 的左子树
- 左子树为单独的 4 ,4 没有左子树,也没有右子树(若存在左/右子树,则需要继续往下递推),所以输出 4
- 遍历完 2 的左子树,再遍历 2 的右子树
- 右子树为单独的 5 ,5 没有左子树,也没有右子树,所以输出 5
- 最后遍历 2 自己,输出 2
- 再遍历根节点 1 的右子树
- 由于节点 3 还有左子树,所以先遍历 3 的左子树
- 左子树为单独的 6 ,6 没有左子树,也没有右子树,所以输出 6
- 遍历完 3 的左子树,再遍历 3 的右子树
- 左子树为单独的 7 ,7 没有左子树,也没有右子树,所以输出 7
- 最后遍历 3 自己,输出 3
- 最后遍历根节点 1 ,输出 1
最后的输出结果为 4 5 2 6 7 3 1
代码实现
public class ErgodicTree {
@Test
public void test(){
Node root = new Node(1);
Node node = new Node(2);
Node node1 = new Node(3);
Node node2 = new Node(4);
Node node3 = new Node(5);
Node node4 = new Node(6);
Node node5 = new Node(7);
root.setLeft(node);
root.setRight(node1);
node.setLeft(node2);
node.setRight(node3);
node1.setLeft(node4);
node1.setRight(node5);
this.postOrder(root);
}
//后序遍历
//4 => 5 => 2 => 6 => 7 => 3 => 1 =>
public void postOrder(Node node){
if(node != null){
postOrder(node.getLeft());
postOrder(node.getRight());
System.out.print(node.getValue() + " => ");
}
}
}
class Node{
private int value;
private Node left;
private Node right;
public Node(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
}
总结
BFS : 不用递归,使用队列来进行遍历操作。
DFS : 通常使用递归,三种遍历方式从代码上看就只是输出的位置的替换。
各有各的优点,不同问题不同分析。
参考文献
[^1]: 维基百科
二叉树的遍历(BFS、DFS)的更多相关文章
- 【数据结构与算法】无向图的结构与遍历 BFS&DFS
1 表示无向图的数据类型 1.1 邻接矩阵 可以使用一个V*V的二维布尔矩阵,当定点v和定点w相连的时候,定义第v行第w列的值为true,否则为false.邻接矩阵不适合定点较多的情况,含有百万的顶点 ...
- 图的创建和遍历(BFS/DFS)
图的表示方法主要有邻接矩阵和邻接表.其中邻接表最为常用,因此这里便以邻接表为例介绍一下图的创建及遍历方法. 创建图用到的结构有两种:顶点及弧 struct ArcNode { int vertexIn ...
- 算法导论—无向图的遍历(BFS+DFS,MATLAB)
华电北风吹 天津大学认知计算与应用重点实验室 最后改动日期:2015/8/22 无向图的存储方式有邻接矩阵,邻接链表,稀疏矩阵等. 无向图主要包括双方面内容,图的遍历和寻找联通分量. 一.无向图的遍历 ...
- 模板 图的遍历 bfs+dfs 图的最短路径 Floyed+Dijkstra
广搜 bfs //bfs #include<iostream> #include<cstdio> using namespace std; ],top=,end=; ][]; ...
- java二叉树遍历——深度优先(DFS)与广度优先(BFS) 递归版与非递归版
介绍 深度优先遍历:从根节点出发,沿着左子树方向进行纵向遍历,直到找到叶子节点为止.然后回溯到前一个节点,进行右子树节点的遍历,直到遍历完所有可达节点为止. 广度优先遍历:从根节点出发,在横向遍历二叉 ...
- 广度优先遍历-BFS、深度优先遍历-DFS
广度优先遍历-BFS 广度优先遍历类似与二叉树的层序遍历算法,它的基本思想是:首先访问起始顶点v,接着由v出发,依次访问v的各个未访问的顶点w1 w2 w3....wn,然后再依次访问w1 w2 w3 ...
- Leetcode题目104.二叉树的最大深度(DFS+BFS简单)
题目描述: 给定一个二叉树,找出其最大深度. 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数. 说明: 叶子节点是指没有子节点的节点. 示例: 给定二叉树 [3,9,20,null,null, ...
- 图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
参考网址:图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS) - 51CTO.COM 深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 遍历二叉树 - 基于栈的DFS
之前已经学过二叉树的DFS的遍历算法[http://www.cnblogs.com/webor2006/p/7244499.html],当时是基于递归来实现的,这次利用栈不用递归也来实现DFS的遍历, ...
随机推荐
- 如何使用ODBC应用程序接口连接数据库
如何使用 ODBC 应用程序接口连接数据库? 安装 unixODBC. yum install -y unixODBC yum install -y unixODBC-devel 下载并安装 open ...
- 《深入理解Java虚拟机》读书笔记:HotSpot的算法实现
HotSpot的算法实现 HotSpot的算法实现概要 1.枚举根节点 由于目前的主流Java虚拟机使用的都是准确式GC(这个概念在第1章介绍Exact VM对Classic VM的改进时讲过),所以 ...
- 进阶 stack smashing--canary 报错利用 && environ泄露栈地址
进阶 stack smashing--canary 报错利用 && environ泄露栈地址 这部分是对进阶stack smashing的使用,以及对 environ的认识,我们可以看 ...
- identity4 系列————用户数据持久化篇[六]
前言 前面的例子已经将各种情形下的例子已经介绍了一遍,那么后面就是用户数据持久化该如何处理了. 正文 例子位置: https://github.com/IdentityServer/IdentityS ...
- 一个.NET开源的功能丰富、灵活易用的 Windows 窗口增强神器
前言 通常情况下 Windows 中的软件窗口界面一般只包含还原.移动.大小.最大化.最小化.关闭等几个基本的操作: 今天大姚给大家推荐一个.NET开源.免费(MIT License).功能丰富.灵活 ...
- Serverless在游戏运营行业进行数据采集分析的最佳实践
简介: 这个架构不光适用于游戏运营行业,其实任何大数据采集传输的场景都是适用的,目前也已经有很多客户正在基于Serverless的架构跑在生产环境,或者正走在改造Serverless 架构的路上. 众 ...
- 云原生时代如何用 Prometheus 实现性能压测可观测-Metrics 篇
简介:可观测性包括 Metrics.Traces.Logs3 个维度.可观测能力帮助我们在复杂的分布式系统中快速排查.定位问题,是分布式系统中必不可少的运维工具. 作者:拂衣 什么是性能压测可观测 ...
- All in one:如何搭建端到端可观测体系
简介:一文看懂可观测! 作者:西杰 & 白玙 可观测的前生今世 系统的可观测与故障可分析作为系统运维中重要的衡量标准,随着系统在架构.资源单位.资源获取方式.通信方式演进过程,遇到了巨大挑战 ...
- [Contract] Solidity 多种访问控制 (Access Control) 实现方式
在 solidity 中控制访问,一般是通过 modifier 修饰符方法来直接做. 那么对于稍复杂的多种访问控制,通常需要一个统一操作的模块化类库. 现在已经有了这样的类库存在,我们通过一个实现功能 ...
- dotnet C# 通过 Vortice 使用 Direct2D 特效入门
本文将告诉大家如何通过 Vortice 使用 D2D 的特效 本文属于 DirectX 系列博客,更多 DirectX 和 D2D 以及 Vortice 库的博客,请参阅我的 博客导航 上一篇: Di ...