遍历二叉树 - 基于栈的DFS
之前已经学过二叉树的DFS的遍历算法【http://www.cnblogs.com/webor2006/p/7244499.html】,当时是基于递归来实现的,这次利用栈不用递归也来实现DFS的遍历,这里先只学习如何用它进行二叉树的前序遍历,具体何为前序遍历这里不多解释,可以参考之前写的博客有详细的说明,下面开始实现。
实现一个栈:
为了能让栈里面可以放任何类型的数据,则使用C++的模板来实现,先新建一个stack头文件,以便在我们需要用的文件中只要引用头文件既可:
然后再新建一个Stack类,里面定义栈的几个经典方法: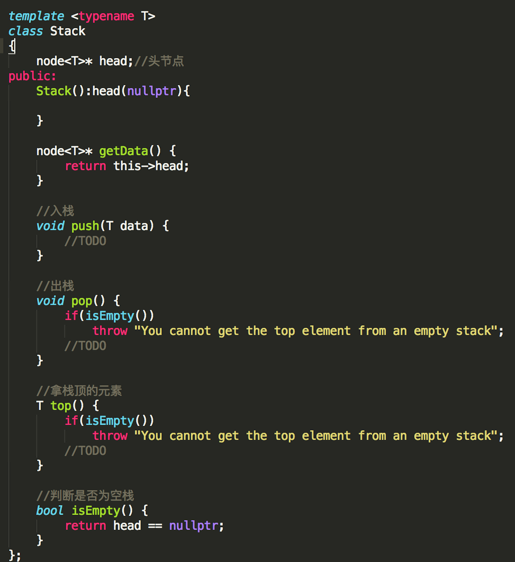
由于比较好理解,下面直接给出具体实现,不多解释:
/*
* 利用模板来实现一个栈,可以往里面添加任意一个元素
*/ template <typename T>
struct node
{
T data;
struct node* next;
node(T data) {this->data = data;};
}; template <typename T>
class Stack
{
node<T>* head;//头节点
public:
Stack():head(nullptr){ } node<T>* getData() {
return this->head;
} //入栈
void push(T data) {
node<T>* new_node = new node<T>(data);
new_node->next = head;
head = new_node;
} //出栈
void pop() {
if(isEmpty())
throw "You cannot get the top element from an empty stack";
node<T>* temp = head;
head = temp->next;
delete temp;
} //拿栈顶的元素
T top() {
if(isEmpty())
throw "You cannot get the top element from an empty stack";
return head->data;
} //判断是否为空栈
bool isEmpty() {
return head == nullptr;
}
};
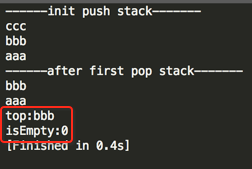
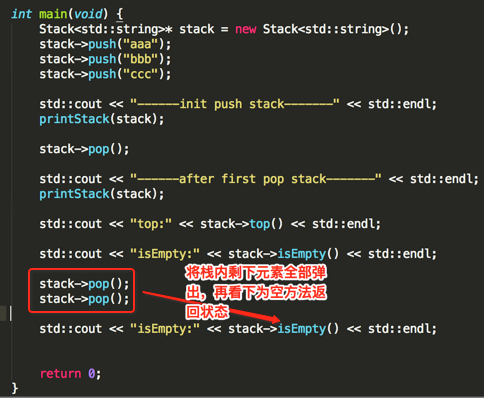
下面来使用一下咱们实现的Stack,如下:
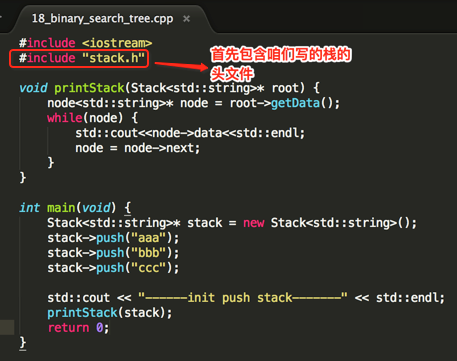
编译运行:

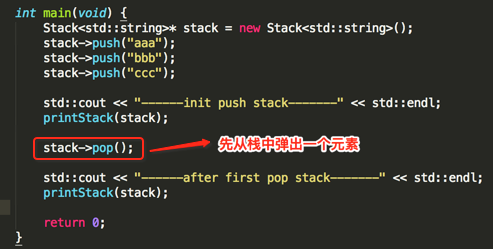
编译运行:
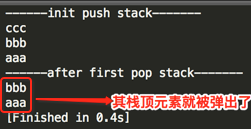

编译运行:
编译运行:

ok,一切如预期~
利用栈构建一个二叉树:
新建一个结构体用来构造二叉树:
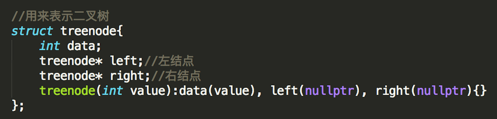
接着用它来构建一个二叉树,还是构建之前已经使用过的如下二叉树:

下面开始构建:

利用栈对二叉树进行前序遍历:
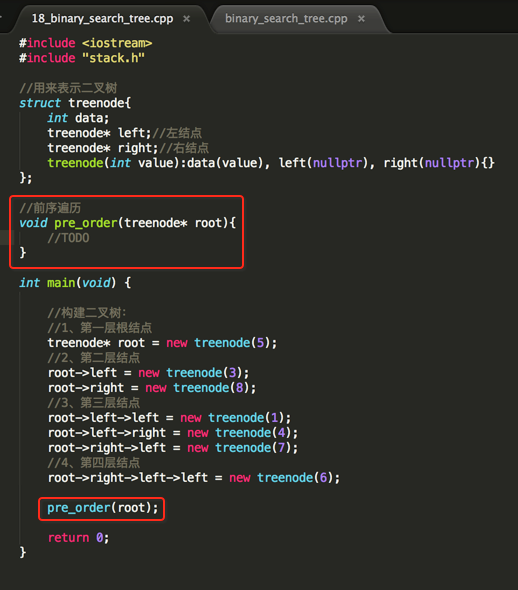
下面看下具体实现:
#include <iostream>
#include "stack.h" //用来表示二叉树
struct treenode{
int data;
treenode* left;//左结点
treenode* right;//右结点
treenode(int value):data(value), left(nullptr), right(nullptr){}
}; //前序遍历
void pre_order(treenode* root){
Stack<treenode*> stack;//声明一个栈
treenode* current_node = root;
while(current_node) {
//1、首先打印当前结点,因为是前序遍历
std::cout << current_node->data << std::endl;
//2、如果存在右结点则将其入栈暂存,待左结点输出完之后再去处理这些右结点
if(current_node->right) stack.push(current_node->right);
//3、不断去处理左结点,直到左结点处理完了,则从栈中拿右点进行处理
if(current_node->left)//如果有左结点,则将它做为当前处理的结点不断输出
current_node = current_node->left;
else {
//这时左结点已经处理完了
if(stack.isEmpty())//如果缓存栈已经为空了则说明整个二叉树的遍历结束了
current_node = nullptr;
else {
//则取出栈顶的右结点进行处理,由于是后进先出,所以拿出来的永远是最新插入的右结点
current_node = stack.top();
stack.pop();//将其元素从栈顶弹出
} }
}
} int main(void) { //构建二叉树:
//1、第一层根结点
treenode* root = new treenode();
//2、第二层结点
root->left = new treenode();
root->right = new treenode();
//3、第三层结点
root->left->left = new treenode();
root->left->right = new treenode();
root->right->left = new treenode();
//4、第四层结点
root->right->left->left = new treenode(); pre_order(root); return ;
}
可见其遍历过程并未用到递归,编译运行:

Debug分析:

root = new treenode(5);
①、 ,新建一个栈,用来存放暂存的结点。
,新建一个栈,用来存放暂存的结点。
②、
③、开始进行循环遍历:
Loop1: current_node = new treenode(5);
a、打印当有结点【5】。
b、current_node->right = new treenode(8);条件为真,则将它添加入栈暂存。此是栈为:

c、current_node->left = new treenode(3);有左结点,条件为真,current_node = new treenode(3);
Loop2:current_node = new treenode(3);
a、打印当有结点【3】。
b、current_node->right = new treenode(4);条件为真,则将它添加入栈暂存。此是栈为:

c、current_node->left = new treenode(1);有左结点,条件为真,current_node = new treenode(1);
Loop3:current_node = new treenode(1);
a、打印当有结点【1】。
b、current_node->right = null;条件为假,继续c:
c、current_node->left = null;木有左结点,条件为假,执行d;
d、这时左结点已经处理完,则从栈中去处理右结点
①、当前栈不为空,条件不满足执行②。
②、取出栈顶的右结点进行处理:current_node = new treenode(4);并将这上结点从栈中弹出。
Loop4:current_node = new treenode(4);
a、打印当有结点【4】。
b、current_node->right = null;条件为假,继续c:
c、current_node->left = null;木有左结点,条件为假,执行d;
d、这时左结点已经处理完,则从栈中去处理右结点
①、当前栈不为空,条件不满足执行②。
②、取出栈顶的右结点进行处理:current_node = new treenode(8);并将这上结点从栈中弹出。
Loop5:current_node = new treenode(8);
a、打印当有结点【8】。
b、current_node->right = null;条件为假,继续c:
c、current_node->left = new treenode(7);有左结点,条件为真,current_node = new treenode(7);
Loop6:current_node = new treenode(7);
a、打印当有结点【7】。
b、current_node->right = null;条件为假,继续c:
c、current_node->left = new treenode(6);有左结点,条件为真,current_node = new treenode(6);
Loop7:current_node = new treenode(6);
a、打印当有结点【6】。
b、current_node->right = null;条件为假,继续c:
c、current_node->left = null;木有左结点,条件为假,执行d;
d、这时左结点已经处理完,则从栈中去处理右结点
①、当前栈为空,条件满足,current_node = null;
Loop8:current_node = null;其循环条件不满足退出循环。
复杂度分析:
时间复杂度:由于每个结点都会循环到,所以说它的复杂度是O(N)。
空间复杂度:从上面的debug分析结果可以看出,栈中最多只会存树的深度大小,所以说空间复杂度正常情况下是:O(logN);除非是一个极端的二叉树,结点都放到一边了,那最差也是O(N)。
遍历二叉树 - 基于栈的DFS的更多相关文章
- 遍历二叉树 - 基于递归的DFS(前序,中序,后序)
上节中已经学会了如何构建一个二叉搜索数,这次来学习下树的打印-基于递归的DFS,那什么是DFS呢? 有个概念就行,而它又分为前序.中序.后序三种遍历方式,这个也是在面试中经常会被问到的,下面来具体学习 ...
- 遍历二叉树 - 基于队列的BFS
之前学过利用递归实现BFS二叉树搜索(http://www.cnblogs.com/webor2006/p/7262773.html),这次学习利用队列(Queue)来实现,关于什么时BFS这里不多说 ...
- 基于visual Studio2013解决面试题之0401非递归遍历二叉树
题目
- SpiralOrderTraverse,螺旋遍历二叉树,利用两个栈
问题描述:s型遍历二叉树,或者反s型遍历二叉树 算法分析:层序遍历二叉树只需要一个队列,因为每一层都是从左往右遍历,而s型遍历二叉树就要用两个栈了,因为每次方向相反. public static vo ...
- 二叉树中序遍历,先序遍历,后序遍历(递归栈,非递归栈,Morris Traversal)
例题 中序遍历94. Binary Tree Inorder Traversal 先序遍历144. Binary Tree Preorder Traversal 后序遍历145. Binary Tre ...
- 图的基本遍历算法的实现(BFS & DFS)复习
#include <stdio.h> #define INF 32767 typedef struct MGraph{ ]; ][]; int ver_num, edge_num; }MG ...
- 数据结构算法C语言实现(二十)--- 6.3.1遍历二叉树
一.简述 二叉树的遍历主要是先序.中序.后序及对应的递归和非递归算法,共3x2=6种,其中后序非递归在实现上稍复杂一些.二叉树的遍历是理解和学习递归及体会栈的工作原理的绝佳工具! 此外,非递归所用的栈 ...
- 【面经】用递归方法对二叉树进行层次遍历 && 二叉树深度
void PrintNodeAtLevel(BiTree T,int level) { // 空树或层级不合理 ) return; == level) { cout << T->da ...
- Leetcode 94. Binary Tree Inorder Traversal (中序遍历二叉树)
Given a binary tree, return the inorder traversal of its nodes' values. For example: Given binary tr ...
随机推荐
- Facebook程序员跳楼事件:技术路线会越走越窄吗?
这是小川的第417次更新,第450篇原创 这几天有个刷屏的文章,讲的是Facebook有位程序员跳楼了,这位程序员的一些信息也"被曝光",比如年轻时是浙大的学霸,后来又赴美读硕,中 ...
- 【Matlab开发】matlab删除数组中符合条件的元素与散点图绘制
[Matlab开发]matlab删除数组中符合条件的元素与散点图绘制 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ matlab删除数组中符合条件的元素 如 ...
- 洛谷 题解 P1133 【教主的花园】
$n<=10^5 $ O(n)算法 状态 dp[i][j][k]表示在第i个位置,种j*10的高度的树,且这棵树是否比相邻两棵树高 转移 dp[i][1][0]=max(dp[i-1][2][1 ...
- leveldb单元测试之宏定义源码剖析
前言 leveldb 是一个库,没有 main() 函数入口, 故非常难理清其中的代码逻辑.但好在库中有非常多的单元测试代码,帮助读者理解其中的各个模块的功能.然而,测试代码个人觉得一开始看时非常费解 ...
- Java核心第五章继承
5.1类 超类(父类.基类) 子类(派生类) 使用关键字extends来继承 对于子类想访问父类的私有域,则必须要借助公有接口,在父类中的公有方法正是这样的接口 为了防止子类定义了与父类一样的成员函 ...
- Java编程思想(三)控制程序流程
3.1.10逗号运算符 我们可以使用一系列由逗号分隔的语句,而且哪些语句均会独立执行. 3.1.15复习计算顺序
- [CF132C] Logo Turtle
[CF132C] Logo Turtle , Luogu A turtle moves following by logos.(length is \(N\)) \(F\) means "m ...
- NIT校赛-- 雷顿女士与平衡树
题意:https://ac.nowcoder.com/acm/contest/2995/E 给你一棵树,节点有权值,让你求所有路径max-min的和. 思路: 我们计算每个点的贡献,对于一个点,当它为 ...
- 【Trie】L 语言
[题目链接]: https://loj.ac/problem/10053 [题意]: 给出n个模式串.请问文本串是由多少个模式串组成的. [题解]: 当我学完AC自动机后,发现这个题目也太简单了吧. ...
- js判断变量是否为整数
//返回false则不为整数数字,返回ture则反之 var isIntNumber=function(val){ if (isNaN(val) || Math.floor(val) != val) ...