爬取豆瓣Top250图书数据
爬取豆瓣Top250图书数据
项目的实现步骤
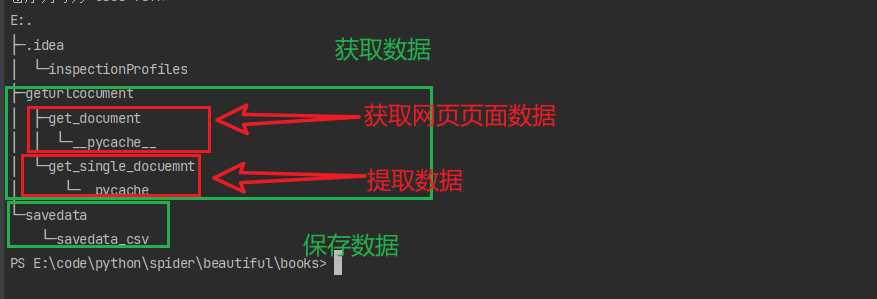
1.项目结构
2.获取网页数据
3.提取网页中的关键信息
4.保存数据
1.项目结构
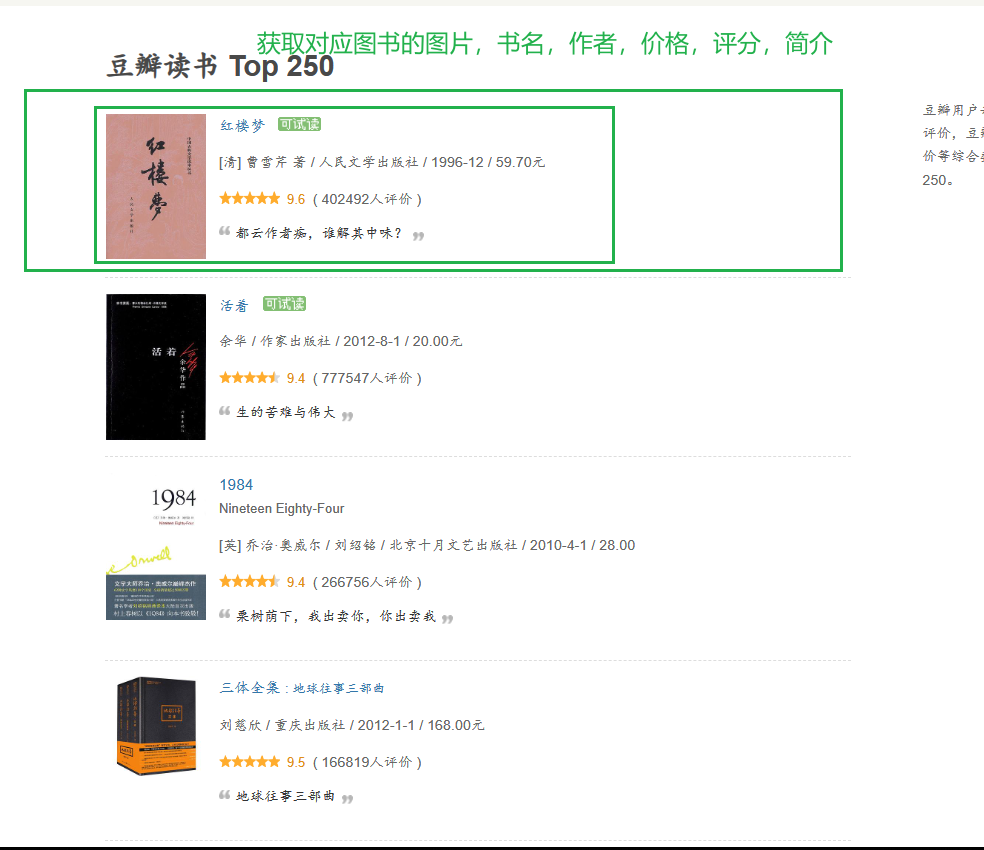
2.获取网页数据
对应的网址为https://book.douban.com/top250
import requests
from bs4 import BeautifulSoup
"""
获取网页数据,解析数据,将相应的数据传出
"""
def get_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Mobile Safari/537.36 Edg/114.0.1823.43'
}
resp=requests.get(url,headers=headers)
soup=BeautifulSoup(resp.text,'html.parser')
return soup
3.提取网页中的关键信息
获取传出的解析后的数据,获取对应的图片,书名,作者,价格,评价,简介
from geturlcocument.get_document import get_page
import re
# 初始数据
pictures=[]
names=[]
authors=[]
prices=[]
scores=[]
sums=[]
def get_single():
# 网址地址
urls = [f"https://book.douban.com/top250?start={num}" for num in range(0,250,25)]
for url in urls:
# 获取对应的网页文本
text = get_page.get_page(url)
# 所有数据的集合
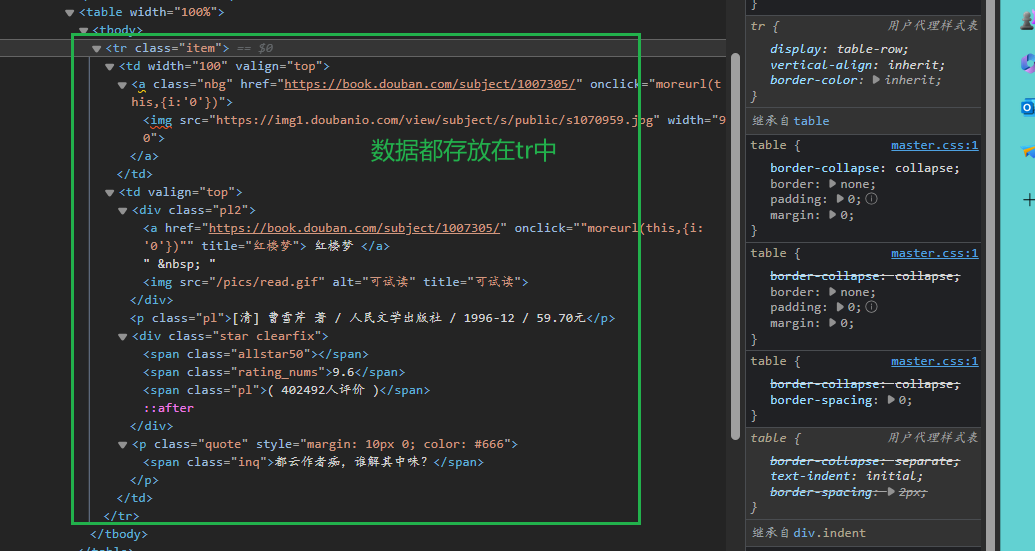
all_tr = text.find_all(name="tr", attrs={"class": "item"})
# 查找每个单项
for tr in all_tr:
# 数据类型:图片,书名,作者,价格,评分,简介
# 图片
picture = tr.find(name="img")
picture = picture.get('src')
# print(picture)
# 书名
div = tr.find(name='div', attrs={'class': 'pl2'})
name = div.find('a').text
name = re.sub(r'\s+', '', name)
# 作者
author = tr.find(name='p', attrs={'class': 'pl'}).text
author = author.split('/')[0]
# 价格
price = author.split('/')[-1]
price = re.sub(r'元', '', price)
# 评分
score = tr.find(name='span', attrs={'class': 'rating_nums'}).text
try:
sum = tr.find(name='span', attrs={'class': 'inq'}).text
except AttributeError:
sum = ''
pictures.append(picture)
names.append(name)
authors.append(author)
prices.append(price)
scores.append(score)
sums.append(sum)
data = {
"picture": pictures,
"name": names,
"author": authors,
"price": prices,
"score": scores,
"sum": sums
}
return data
将获取的数据存入到字典中,将数据传出,使用re库对相应的数据进行处理,运用异常检错
4.保存数据
获取传出的字典类型的数据,将数据存入到pandas的DataFrame类型中
from geturlcocument.get_single_docuemnt import get_single
import pandas as pd
# 获取字典类型的数据
data=get_single.get_single()
# 用pandas的DataFrame类型存储数据
df=pd.DataFrame(data)
df.to_csv('./books.csv',encoding='utf-8')
print('ending of data')
该项目完成!!!
爬取豆瓣Top250图书数据的更多相关文章
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- 正则爬取豆瓣Top250数据存储到CSV文件(6行代码)
利用正则爬取豆瓣TOP250电影信息 电影名字 电影年份 电影评分 评论人数 import requests import csv import re # 不算导包的话正式代码6行 存储到csv文件 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- Python 爬取豆瓣TOP250实战
学习爬虫之路,必经的一个小项目就是爬取豆瓣的TOP250了,首先我们进入TOP250的界面看看. 可以看到每部电影都有比较全面的简介.其中包括电影名.导演.评分等. 接下来,我们就爬取这些数据,并将这 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- re、base64的结合使用爬取豆瓣top250
一.缘由 对于豆瓣的这个网站,记得使用了不少于三种的爬取和解析方式来进行的.今天的这种解析方式是我使用起来较为顺手,后来就更喜欢使用xpath解析,但是这两种也需要掌握. 二.代码展示 '''爬取豆瓣 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
随机推荐
- Vue 路由导航守卫
Vue 路由导航守卫 一:全局守卫 (1) router.beforeEach beforeEach((to, from, next) => {}) 接收三个参数,在路由切换成功之前调用 to ...
- 开发者需掌握的超实用VS Code for Windows快捷键
链接|https://dev.to/devland/100-crucial-keyboard-shortcuts-for-vs-code-users-4474 作者|Thomas Sentre 翻译| ...
- 如何申请 Azure OpenAI
一.前言 众所周知 OpenAI ChatGPT 是不对中国开放的,包括香港.就最近一个月的情况来看,陆续有 API 调用被限制.大规模账号封禁.关闭注册.无法直接使用银联支付(国内信用卡)等等,使用 ...
- kubernetes(k8s)常用deploy模板 并验证
kubernetes常用deploy模板,并验证 编写deploy配置文件 root@hello:~# cat deploy.yaml apiVersion: apps/v1 kind: Deplo ...
- 在Kubernetes上安装Netdata的方法
介绍 Netdata可用于监视kubernetes集群并显示有关集群的信息,包括节点内存使用率.CPU.网络等,简单的说,Netdata仪表板可让您全面了解Kubernetes集群,包括在每个节点上运 ...
- python入门教程之六运算符
什么是运算符? 本章节主要说明Python的运算符.举个简单的例子 4 +5 = 9 . 例子中,4 和 5 被称为操作数,"+" 称为运算符. Python语言支持以下类型的运算 ...
- sip消息拆包原理及组包流程
操作系统 :CentOS 7.6_x64 freeswitch版本 :1.10.9 sofia-sip版本: sofia-sip-1.13.14 freeswitch使用sip协议进行通 ...
- Gartner最新报告,分析超大规模边缘解决方案
当下,酝酿能量的超级边缘. 最近,我们在谈视频化狂飙.谈AIGC颠覆.谈算力动能不足,很少谈及边缘.但"边缘"恰恰与这一切相关,且越发密不可分,它是未来技术发展的极大影响因子. & ...
- 自己动手从零写桌面操作系统GrapeOS系列教程——4.1 在VirtualBox中安装CentOS
学习操作系统原理最好的方法是自己写一个简单的操作系统. 之前讲解开发环境时并没有介绍具体的安装过程,有网友反应CentOS的安装配置有问题,尤其是共享文件夹.本讲我们就来补充介绍一下在VirtualB ...
- Gpssworld仿真(二):并排排队系统模拟
4.3 某一个加油站能够配给三个级别的燃油:①家庭取暖用的燃油:②轻工业用的燃油:③运输用的燃油.每一级别的燃油都有一个对应的油泵.订单中燃油的数量在3000加仑和5000加仑中变化,每次增加10加仑 ...