爬取豆瓣Top250图书数据
爬取豆瓣Top250图书数据
项目的实现步骤
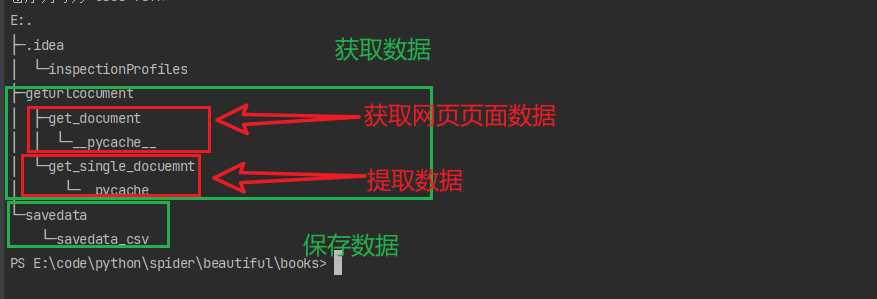
1.项目结构
2.获取网页数据
3.提取网页中的关键信息
4.保存数据
1.项目结构
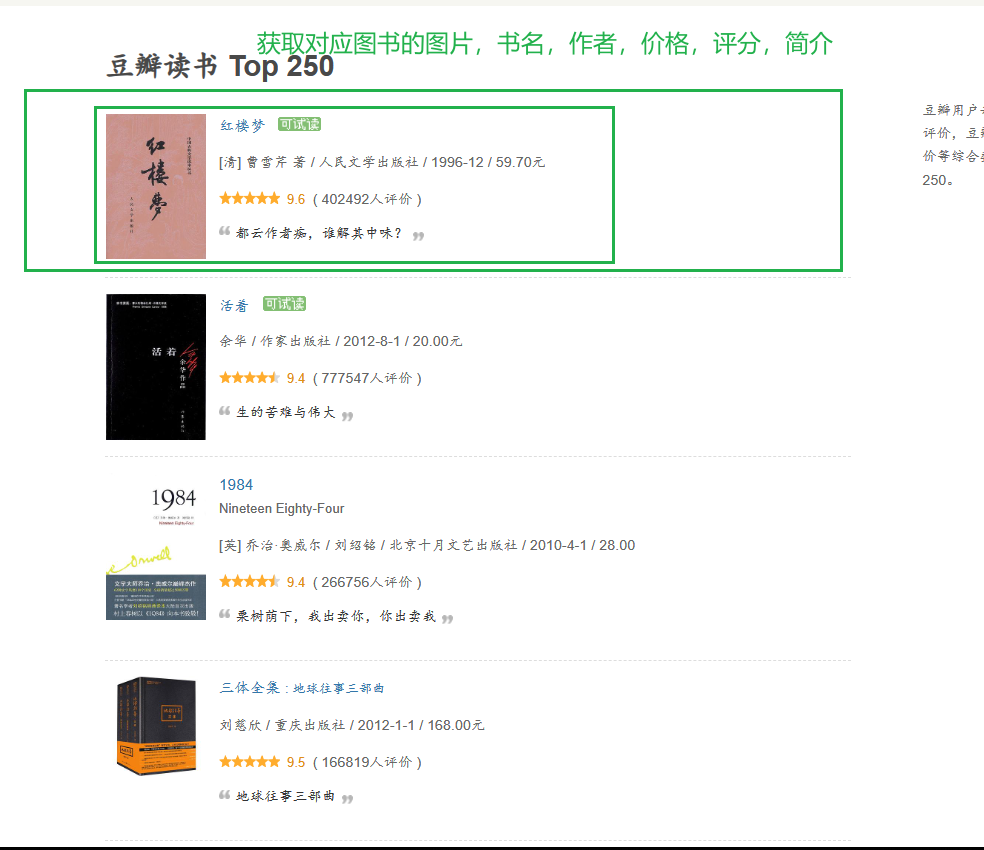
2.获取网页数据
对应的网址为https://book.douban.com/top250
import requests
from bs4 import BeautifulSoup
"""
获取网页数据,解析数据,将相应的数据传出
"""
def get_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Mobile Safari/537.36 Edg/114.0.1823.43'
}
resp=requests.get(url,headers=headers)
soup=BeautifulSoup(resp.text,'html.parser')
return soup
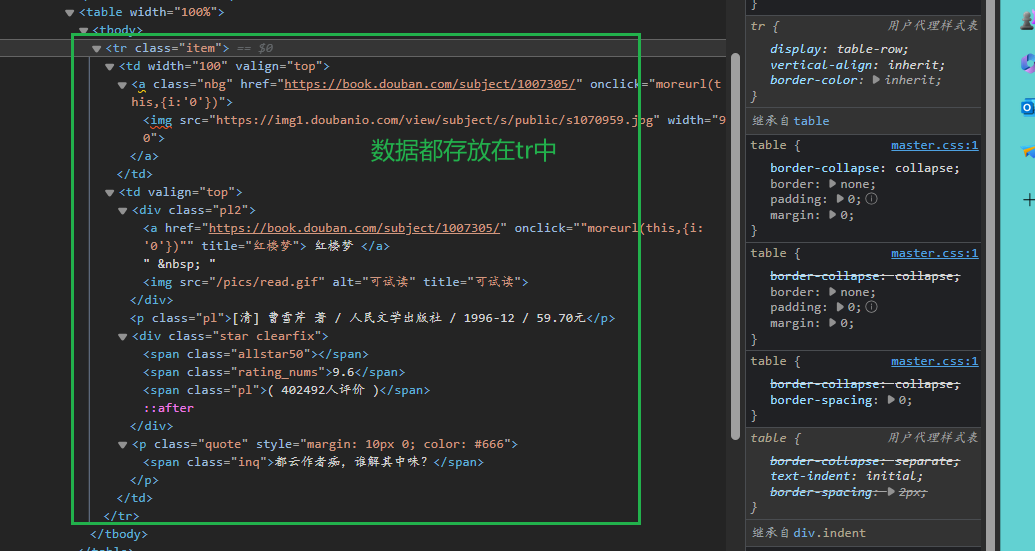
3.提取网页中的关键信息
获取传出的解析后的数据,获取对应的图片,书名,作者,价格,评价,简介
from geturlcocument.get_document import get_page
import re
# 初始数据
pictures=[]
names=[]
authors=[]
prices=[]
scores=[]
sums=[]
def get_single():
# 网址地址
urls = [f"https://book.douban.com/top250?start={num}" for num in range(0,250,25)]
for url in urls:
# 获取对应的网页文本
text = get_page.get_page(url)
# 所有数据的集合
all_tr = text.find_all(name="tr", attrs={"class": "item"})
# 查找每个单项
for tr in all_tr:
# 数据类型:图片,书名,作者,价格,评分,简介
# 图片
picture = tr.find(name="img")
picture = picture.get('src')
# print(picture)
# 书名
div = tr.find(name='div', attrs={'class': 'pl2'})
name = div.find('a').text
name = re.sub(r'\s+', '', name)
# 作者
author = tr.find(name='p', attrs={'class': 'pl'}).text
author = author.split('/')[0]
# 价格
price = author.split('/')[-1]
price = re.sub(r'元', '', price)
# 评分
score = tr.find(name='span', attrs={'class': 'rating_nums'}).text
try:
sum = tr.find(name='span', attrs={'class': 'inq'}).text
except AttributeError:
sum = ''
pictures.append(picture)
names.append(name)
authors.append(author)
prices.append(price)
scores.append(score)
sums.append(sum)
data = {
"picture": pictures,
"name": names,
"author": authors,
"price": prices,
"score": scores,
"sum": sums
}
return data
将获取的数据存入到字典中,将数据传出,使用re库对相应的数据进行处理,运用异常检错
4.保存数据
获取传出的字典类型的数据,将数据存入到pandas的DataFrame类型中
from geturlcocument.get_single_docuemnt import get_single
import pandas as pd
# 获取字典类型的数据
data=get_single.get_single()
# 用pandas的DataFrame类型存储数据
df=pd.DataFrame(data)
df.to_csv('./books.csv',encoding='utf-8')
print('ending of data')
该项目完成!!!
爬取豆瓣Top250图书数据的更多相关文章
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- 正则爬取豆瓣Top250数据存储到CSV文件(6行代码)
利用正则爬取豆瓣TOP250电影信息 电影名字 电影年份 电影评分 评论人数 import requests import csv import re # 不算导包的话正式代码6行 存储到csv文件 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- Python 爬取豆瓣TOP250实战
学习爬虫之路,必经的一个小项目就是爬取豆瓣的TOP250了,首先我们进入TOP250的界面看看. 可以看到每部电影都有比较全面的简介.其中包括电影名.导演.评分等. 接下来,我们就爬取这些数据,并将这 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- re、base64的结合使用爬取豆瓣top250
一.缘由 对于豆瓣的这个网站,记得使用了不少于三种的爬取和解析方式来进行的.今天的这种解析方式是我使用起来较为顺手,后来就更喜欢使用xpath解析,但是这两种也需要掌握. 二.代码展示 '''爬取豆瓣 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
随机推荐
- JVM内存结构与内存模型
这篇文章重点讲一下jvm的内存结构和内存模型的知识点.(2023.3.11) 1.内存结构 jvm内存区域主要分为线程私有区域[程序计数器,虚拟机栈,本地方法栈],线程共享区域[堆,方法区],直接内存 ...
- 微软 New Bing AI 申请与使用保姆级教程(免魔法)
本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问. 大家好,我是小彭. 最近的 AI 技术实在火爆,从 OpenAI 的 ChatGPT,到微软的 New Bi ...
- 使用 Azure OpenAI 打造自己的 ChatGPT
一.前言 当今的人工智能技术正在不断发展,越来越多的企业和个人开始探索人工智能在各个领域中的应用.其中,在自然语言处理领域,OpenAI 的 GPT 系列模型成为了研究热点.OpenAI 公司的 Ch ...
- [数据库/ORALCE]导入/导出数据
ORACLE数据导入/导出 工具介绍:EXP/IMP | EXPDP/IMPDP EXP和IMP是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用. EXPDP和IMPDP是服务端的工具程序 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- DFS手写排列
DFS手写排列 虽然python中有自带的排列函数,但是在某些特殊情况需要手写排列.掌握了DFS手写排列对DFS的理解有一定的帮助. 1.手写排列(非字典序输出) 这种代码比较简单易懂,但是不是按照字 ...
- 2021.05.09【NOIP提高组】模拟赛总结
2021.05.09[NOIP提高组]模拟赛总结 T1 T2
- Python 项目:外星人入侵--第三部分
1.项目内容: 在屏幕左上角添加一个外星人,并指定合适的边框,根据第一个外星人的边距和屏幕尺寸计算屏幕上可容纳多少个外星人. 让外星人群向两边和下方移动,直到外星人被全部击落,有外星人撞到飞船,或有外 ...
- 谁想和我一起做低代码平台!一个可以提升技术,让简历装x的项目
序言 正如文章标题所述,最近一段时间低代码这个概念非常的火,但其实在不了解这个东西的时候觉得它真的很炫酷,从那时就萌生了做一个低代码平台的想法. 但随着时间的变化,现在市面上低代码各个业务方向的平台都 ...
- 学node 之前你要知道这些
初识nodejs 19年年底一个偶然的机会接到年会任务,有微信扫码登录.投票.弹幕等功能,于是决定用node 来写几个服务,结果也比较顺利. 当时用看了下koa2的官方文档,知道怎么连接数据库 ...