不同大小的缓冲区对 MD5 计算速度的影响
最*需要在计算大文件的 MD5 值时显示进度,于是我写了如下的代码:
public long Length {get; private set; }
public long Position { get; private set; }
public async Task ComputeMD5Async(string file, CancellationToken cancellationToken)
{
using var fs = File.OpenRead(file);
Length = fs.Length;
var task = MD5.HashDataAsync(fs, cancellationToken);
var timer = new PeriodicTimer(TimeSpan.FromMilliseconds(10));
while (await timer.WaitForNextTickAsync(cancellationToken))
{
Position = fs.Position;
if (task.IsCompleted)
{
break;
}
}
}
运行的时候发现不对劲儿了,我的校验速度只能跑到 350MB/s,而别人的却能跑到 500MB/s,相同的设备怎么差距有这么大?带这个疑问我去看了看别人的源码,发现是这么写的:
protected long _progressPerFileSizeCurrent;
protected byte[] CheckHash(Stream stream, HashAlgorithm hashProvider, CancellationToken token)
{
byte[] buffer = new byte[1 << 20];
int read;
while ((read = stream.Read(buffer)) > 0)
{
token.ThrowIfCancellationRequested();
hashProvider.TransformBlock(buffer, 0, read, buffer, 0);
_progressPerFileSizeCurrent += read;
}
hashProvider.TransformFinalBlock(buffer, 0, read);
return hashProvider.Hash;
}
这里使用了 HashAlgorithm.TransformBlock 方法,它能计算输入字节数组指定区域的哈希值,并将中间结果暂时存储起来,最后再调用 HashAlgorithm.TransformFinalBlock 结束计算。上述代码中缓冲区 buffer 大小是 1MB,我敏锐地察觉到 MD5 计算速度可能与这个值有关,接着我又去翻了翻 MD5.HashDataAsync 的源码。
// System.Security.Cryptography.LiteHashProvider
private static async ValueTask<int> ProcessStreamAsync<T>(T hash, Stream source, Memory<byte> destination, CancellationToken cancellationToken) where T : ILiteHash
{
using (hash)
{
byte[] rented = CryptoPool.Rent(4096);
int maxRead = 0;
int read;
try
{
while ((read = await source.ReadAsync(rented, cancellationToken).ConfigureAwait(false)) > 0)
{
maxRead = Math.Max(maxRead, read);
hash.Append(rented.AsSpan(0, read));
}
return hash.Finalize(destination.Span);
}
finally
{
CryptoPool.Return(rented, clearSize: maxRead);
}
}
}
源码中最关键的是上面这部分,缓冲区 rented 设置为 4KB,与 1MB 相差甚远,原因有可能就在这里。
为了找到最佳的缓冲区值,我跑了一大堆 BenchMark,覆盖了从 32B 到 64MB 的范围。没什么技术含量,但工作量实在不小。测试使用 1GB 的文件,基准测试是对 1GB 大小的数组直接调用 MD5.HashData,实际的测试代码如下,分别使用内存流 MemoryStream 和文件流 FileStream 作为入参 Stream,对比无硬盘 IO 和实际读取文件的速度。
public async Task HashDataAsync(Stream stream)
{
var hash = MD5.Create();
byte[] buffer = new byte[1 << size];
int read = 0;
while ((read = await stream.ReadAsync(buffer)) != 0)
{
hash.TransformBlock(buffer, 0, read, buffer, 0);
}
hash.TransformFinalBlock(buffer, 0, read);
if (!(hash.Hash?.SequenceEqual(fileHash) ?? false))
{
throw new Exception("Compute error");
}
}
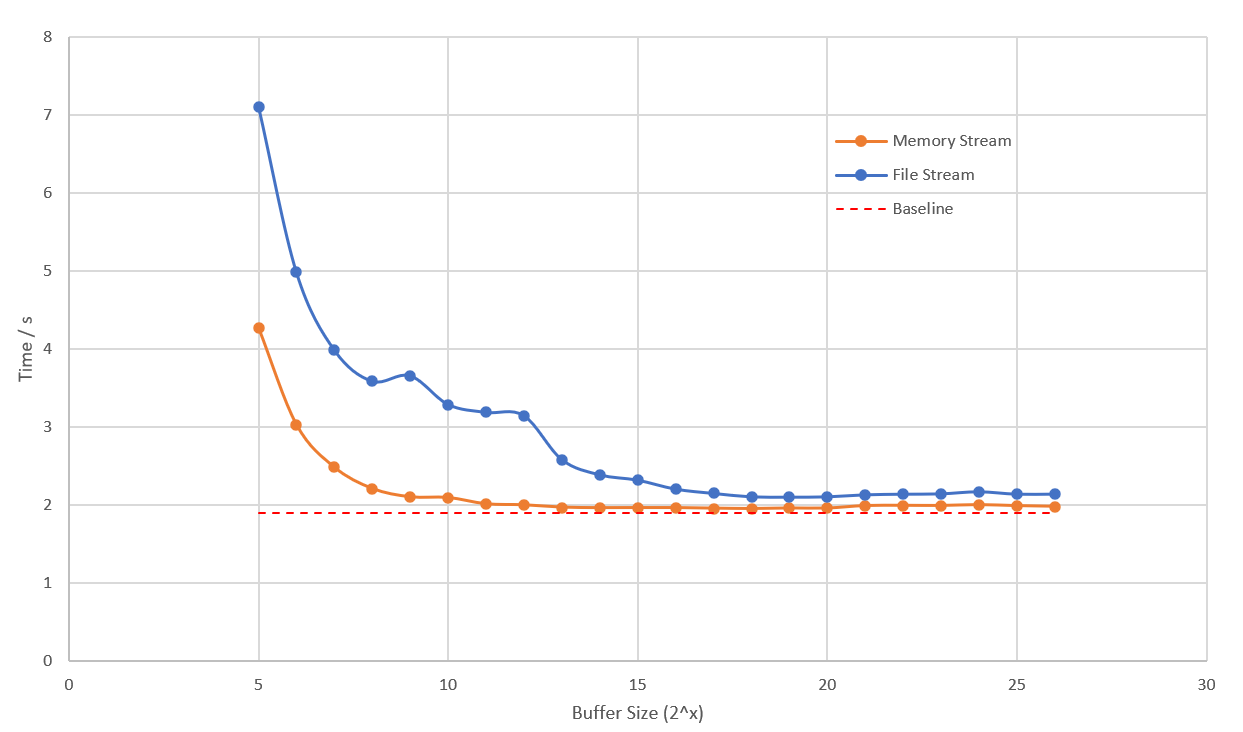
基准测试是那条红色虚线,是所有测试结果中最快的。橙色的曲线是 MemoryStream 的测试结果,在缓存块的 2KB 处降到了一个较低的位置,后续耗时无明显下降。这证明 .NET 源码中使用 4KB 大小的块是一个合理的选择,但是它没有考虑文件 IO 的延迟影响。蓝色的曲线是最接*显示的测试结果,缓存块大于 32KB 时的测试结果才接*于*稳。
总结一下,MD5.HashDataAsync 过慢的原因是文件 IO 影响到了计算速度。使用文件流进行 MD5 校验的时候,缓冲区至少需要 64KB,总体速度才不会被文件 IO 拖后腿。
不同大小的缓冲区对 MD5 计算速度的影响的更多相关文章
- Java中比较不同的MD5计算方式
在项目中经常需要使用计算文件的md5,用作一些用途,md5计算算法,通常在网络上查询时,一般给的算法是读取整个文件的字节流,然后计算文件的md5,这种方式当文件较大,且有很大并发量时,则可能导致内存打 ...
- iOS BCD码、数据流、字节和MD5计算
一.各个之间的相互转换 1.字符串转数据流NSData NSString *str = @"abc123"; NSData *dd = [str dataUsingEncoding ...
- php UTF8 转字节数组,后使用 MD5 计算摘要
Hex.encodeHexString(md5.digest);按 UTF8 转字节数组,后使用 MD5 计算摘要,得到 16 字节数组,使用 Hex 转为长度为 32 的字符串,保持小写 bin2h ...
- 大文本 通过 hadoop spark map reduce 获取 特征列 的 属性值 计算速度
大文本 通过 hadoop spark map reduce 获取 特征列 的 属性值 计算速度
- 一行代码加快pandas计算速度
一行代码加快pandas计算速度 DASK https://blog.csdn.net/sinat_38682860/article/details/84844964 https://cloud.te ...
- Tensorflow使用训练好的模型进行测试,发现计算速度越来越慢
实验时要对多个NN模型进行对比,依次加载直到第8个模型时,发现运行速度明显变慢而且电脑开始卡顿,查看内存占用90+%. 原因:使用过的NN模型还会保存在内存,继续加载一方面使新模型加载特别特别慢,另一 ...
- Cocos Creator 热更新文件MD5计算和需要注意的问题
Creator的热更新使用jsb.热更新基本按照 http://docs.cocos.com/creator/manual/zh/advanced-topics/hot-update.html?h=% ...
- (一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)
摘要: 1.以动态图形式计算一个简单的加法 2.cpu和gpu计算力比较(包括如何指定cpu和gpu) 3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.c ...
- hashlib的md5计算
hashlib的md5计算 hashlib概述 涉及加密服务:Cryptographic Services 其中 hashlib是涉及 安全散列 和 消息摘要 ,提供多个不同的加密算法借口,如SHA1 ...
- .NET 的 Debug 和 Release build 对执行速度的影响
这篇文章发布于我的 github 博客:原文 在真正开始讨论之前先定义一下 Scope. 本文讨论的范围限于执行速度,内存占用什么的不在评估的范围之内. 本文不讨论算法:编译器带来的优化基本上属于底层 ...
随机推荐
- Centos7.9中使用Docker安装云崽机器人
Centos7.9中使用Docker安装云崽机器人 前面我写了如何普通版搭建云崽教程,今天我们来使用docker来安装,感谢docker镜像源作者:如青桑(QQ: 1666633887) 普通版教程: ...
- Hugging Face 社区中蓬勃发展的计算机视觉
在 Hugging Face 上,我们为与社区一起推动人工智能领域的民主化而感到自豪.作为这个使命的一部分,我们从去年开始专注于计算机视觉.开始只是 Transformers 中 Vision Tra ...
- 解决el-checked-group中v-medel绑定的是一个数组对象方法(不用修改源码)
思路:弃用el-checked-group使用el-checked模拟 <!DOCTYPE html> <html> <head> <meta charset ...
- 垃圾回收之G1收集过程
G1 中提供了 Young GC.Mixed GC 两种垃圾回收模式,这两种垃圾回收模式,都是 Stop The World(STW) 的. G1 没有 fullGC 概念,需要 fullGC 时,调 ...
- 【PWN】初见BROP
前言|与BROP的相遇 第一次BROP,它让我觉得pwn,或者说网安很妙,也很折磨 在遇到它之前,之前接触的题目都是简单的栈溢出,感觉没有啥有趣的,很简单,找gadget溢出就可以,一切都看得见 可遇 ...
- pandas之字符串操作
Pandas 提供了一系列的字符串函数,因此能够很方便地对字符串进行处理.在本节,我们使用 Series 对象对常用的字符串函数进行讲解.常用的字符串处理函数如下表所示: 函数名称 函数功能和描述 l ...
- JSON.stringify()与JSON.parse()没有你想的那样简单
重新学习这两个API的起因 在本周五有线上的项目,16:30开始验证线上环境. 开始都是顺顺利利,一帆风顺. 大概17:50左右,我正在收拾东西. 准备下班去王者峡谷骑着我的船溜达一圈. 可是天降意外 ...
- 重新实现hashCode()方法
在Java中,为了让对象在集合中能够更高效地进行查找和比较,我们通常需要重写对象的equals()和hashCode()方法.其中,equals()方法用于比较两个对象是否相等,而hashCode() ...
- 关于Java中值传递和址传递
参数传递在Java中有两种类型 值和址 其实本质都是一份拷贝 在调用函数的时候 进行压栈 传进来的参数会被开辟一份新的空间 传基本类型是把值传过去 传引用数据类型是实例指向实参 void m(int ...
- ES的索引结构与算法解析
作者:京东物流 李洪吉 提到ES,大多数爱好者想到的都是搜索引擎,但是明确一点,ES不等同于搜索引擎.不管是谷歌.百度.必应.搜狗为代表的自然语言处理(NLP).爬虫.网页处理.大数据处理的全文搜索引 ...