关于ASL(平均查找长度)的简单总结
ASL(Average Search Length),即平均查找长度,在查找运算中,由于所费时间在关键字的比较上,所以把平均需要和待查找值比较的关键字次数成为平均查找长度。
它的定义是这样的:
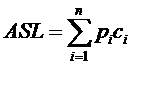
其中n为查找表中元素个数,Pi为查找第i个元素的概率,通常假设每个元素查找概率相同,Pi=1/n,Ci是找到第i个元素的比较次数。
当然,有查找成功,就有查找不成功,即要查找元素不在查找表中。针对不同查找方式的查找成功与不成功,我接下来会说,这也是一我一开始有点乱的地方。
一个算法的ASL越大,说明时间性能差,反之,时间性能好,这也是显而易见的。
- 在顺序查找(Sequence Search)表中,查找方式为从头扫到尾,找到待查找元素即查找成功,若到尾部没有找到,说明查找失败。所以说,Ci(第i个元素的比较次数)在于这个元素在查找表中的位置,如第0号元素就需要比较一次,第一号元素比较2次......第n号元素要比较n+1次。所以Ci=i;所以

可以看出,顺序查找方法查找成功的平均 比较次数约为表长的一半。当待查找元素不在查找表中时,也就是扫描整个表都没有找到,即比较了n次,查找失败

- 折半查找(Binary Search),首先待查找表是有序表,这是折半查找的要求。在折半查找中,用二叉树描述查找过程,查找区间中间位置作为根,左子表为左子树,右子表为右子树,,因为这颗树也被成为判定树(decision tree)或比较树(Comparison tree)。查找方式为(找k),先与树根结点进行比较,若k小于根,则转向左子树继续比较,若k大于根,则转向右子树,递归进行上述过程,直到查找成功或查找失败。在n个元素的折半查找判定树中,由于关键字序列是用树构建的,所以查找路径实际为树中从根节点到被查结点的一条路径,因为比较次数刚好为该元素在树中的层数。所以
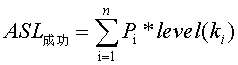 Pi为查找k的概率,level(Ki)为k对应内部结点的层次。而在这样的判定树中,会有n+!种查找失败的情况,因为将判定树构建为完全二叉树,又有n+1个外部结点(用Ei(0<=i<=n)表示),查找失败,即为从根结点到某个外部结点也没有找到,比较次数为该内部结点的结点数个数之和,所以
Pi为查找k的概率,level(Ki)为k对应内部结点的层次。而在这样的判定树中,会有n+!种查找失败的情况,因为将判定树构建为完全二叉树,又有n+1个外部结点(用Ei(0<=i<=n)表示),查找失败,即为从根结点到某个外部结点也没有找到,比较次数为该内部结点的结点数个数之和,所以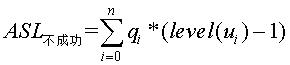 ,qi表示查找属于Ei中关键字的概率,level(Ui)表示Ei对应外部结点的层次。所以,在一颗有n个结点判定树中,总数
,qi表示查找属于Ei中关键字的概率,level(Ui)表示Ei对应外部结点的层次。所以,在一颗有n个结点判定树中,总数 ,所以判定树高度为
,所以判定树高度为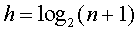 的满二叉树,第i层上结点个数为
的满二叉树,第i层上结点个数为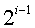 ,查找该层上的结点需要进行i次比较,因此,在等概率情况下ASL为
,查找该层上的结点需要进行i次比较,因此,在等概率情况下ASL为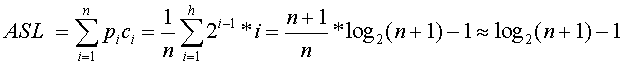
- 例:给11个数据元素有序表(2,3,10,15,20,25,28,29,30,35,40)采用折半查找。则ASL成功和不成功分别是多少?首先画出判定树,
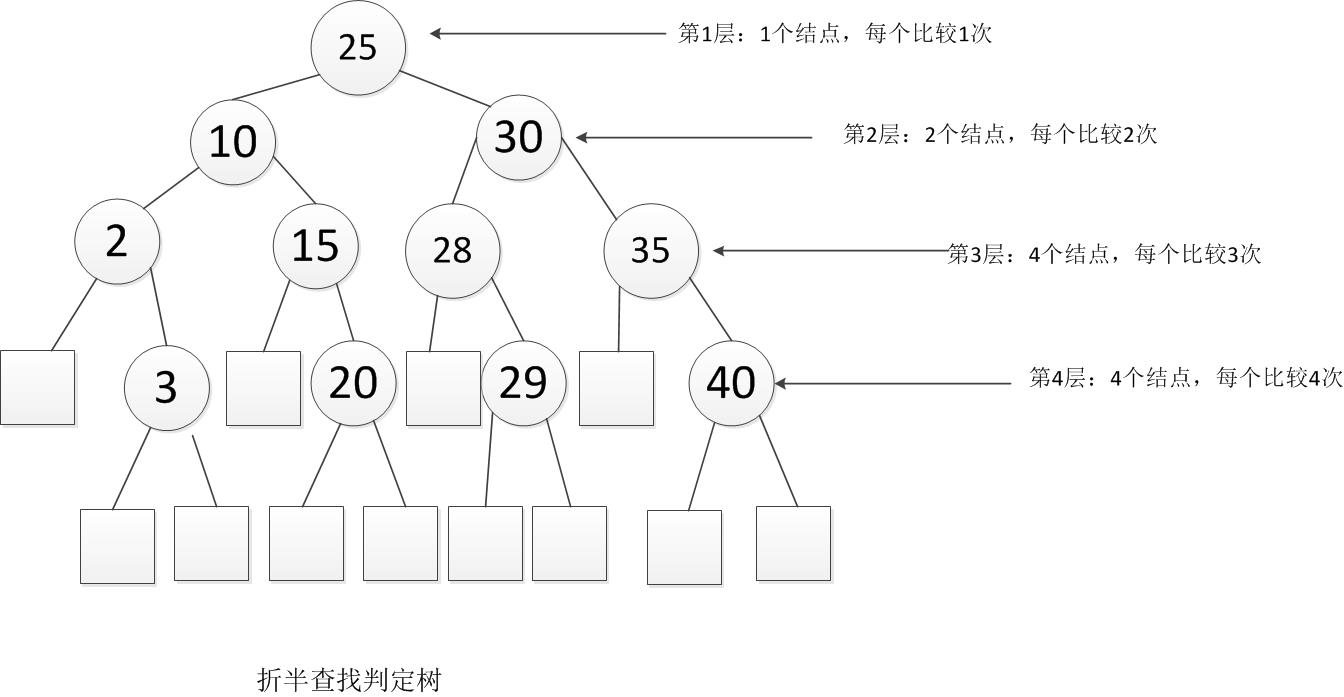 查找成功时总会找到途中某个内部结点,所以成功时的平均查找长度为
查找成功时总会找到途中某个内部结点,所以成功时的平均查找长度为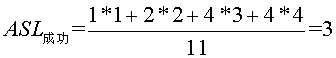 即25查找一次,成功,10,30要查找2次,成功,2,15,28,35要查找3次,成功,3,20,29,40要查找4次,成功。 而不成功的平均查找长度为
即25查找一次,成功,10,30要查找2次,成功,2,15,28,35要查找3次,成功,3,20,29,40要查找4次,成功。 而不成功的平均查找长度为 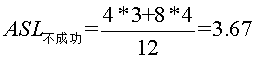 ,为什么这么算呢,因为内部结点都能查找成功,而查找不成功的就是那些空的外部结点,所以到查询到2的左孩子,15的左孩子,28的左孩子,35的左孩子,3的左右孩子,20的左右孩子,29的左右孩子,40的左右孩子时,都是查找不成功的时候。如我要找1,比25小,转向左子树,比较一次,比10小,转左子树,2次,比2 小,转左子树,3次,此时2无左子树,所以失败。所以
,为什么这么算呢,因为内部结点都能查找成功,而查找不成功的就是那些空的外部结点,所以到查询到2的左孩子,15的左孩子,28的左孩子,35的左孩子,3的左右孩子,20的左右孩子,29的左右孩子,40的左右孩子时,都是查找不成功的时候。如我要找1,比25小,转向左子树,比较一次,比10小,转左子树,2次,比2 小,转左子树,3次,此时2无左子树,所以失败。所以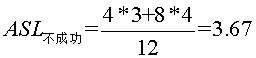 。
。 哈希表中的ASL 查找成功的平均查找长度是指查找到哈希表中已有关键字的平均探测次数。而查找不成功的平均查找长度是指在哈希表中找不到待查的元素,最后找到空位置元素的探测次数平均值。
例:散列表长度为13,地址空间为0~12,散列函数H(k) =K mod 13,对关键字序列{19,14,23,01,68,20,84,27,55,11,10,79} 所以线性探测结果为:
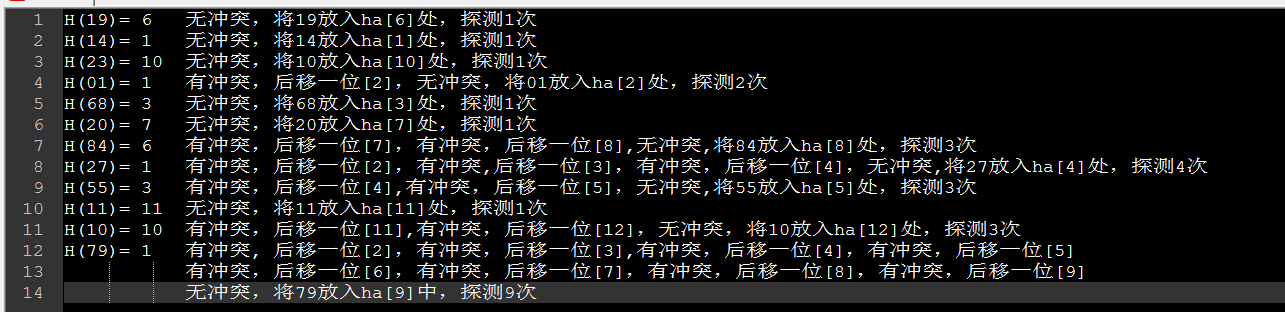

根据探测次数,

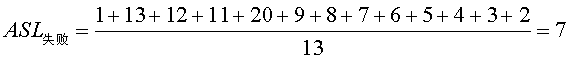 当然成功的很好理解,12个元素,每个元素的探测次数之和除以12就行。而不成功的计算是这样的。散列表长度为13,根据定义,假设待查关键字不在散列表中,要一直找到空元素才算查找失败,如H[0]为空,与待查找元素不等,不成功,比较一次,H[1],此时H[1]的元素与原本放在H[1]的元素不等(假设不在散列表在之中,但也不是空的),继续向后比,与H[2]比也不等,继续向后,一直到H[12],也不等,继续向后时,回到H[0],为空,也不等,查找失败,总计比较13次,然后计算第二号元素,一样的比较,一直把每个位置都统计一遍,从而得出ASL不成功的.
当然成功的很好理解,12个元素,每个元素的探测次数之和除以12就行。而不成功的计算是这样的。散列表长度为13,根据定义,假设待查关键字不在散列表中,要一直找到空元素才算查找失败,如H[0]为空,与待查找元素不等,不成功,比较一次,H[1],此时H[1]的元素与原本放在H[1]的元素不等(假设不在散列表在之中,但也不是空的),继续向后比,与H[2]比也不等,继续向后,一直到H[12],也不等,继续向后时,回到H[0],为空,也不等,查找失败,总计比较13次,然后计算第二号元素,一样的比较,一直把每个位置都统计一遍,从而得出ASL不成功的.
- 以上就是对ASL的小小总结,为了加强自己的理解,也便于自己以后的回顾和修改,还有有一点很开心的是,最为新兰党,总算让我在2019年初等到了洗衣机和兰酱的休学旅行,很满意了。
关于ASL(平均查找长度)的简单总结的更多相关文章
- 链地址法查找成功与不成功的平均查找长度ASL
晚上,好像是深夜了,突然写到这类题时遇到的疑惑,恰恰这个真题只让计算成功的ASL,但我想学一下不成功的计算,只能自己来解决了,翻了李春葆和严蔚敏的教材没有找到相关链地址法的计算,于是大致翻到两篇不错的 ...
- Hash表的平均查找长度ASL计算方法
Hash表的“查找成功的ASL”和“查找不成功的ASL” ASL指的是 平均查找时间 关键字序列:(7.8.30.11.18.9.14) 散列函数: H(Key) = (key x 3) MOD 7 ...
- 使用vs的查找功能,简单大概的统计vs中的代码行数
VS强大的查找功能,可以使用正则表达式来进行查找,这里统计代码行数的原理就是: 在所有指定文件中进行搜索,统计匹配的文本行数. 但是匹配的行需要满足:非注释.非空等特殊非代码行. 使用Ctrl+Shi ...
- 二维数组中的查找 - Java版 -简单二分查找 -<<剑指Offer>> -水题
如题 (总结) -认真读题, 还WA了一次, https://www.nowcoder.com/practice/abc3fe2ce8e146608e868a70efebf62e?tpId=13&am ...
- vim 显示行号 查找的命令简单总结
1. linux vim 进行查找的方法 在command 模式下面 输入 /what-you-search 就可以搜索 注意 n 是向下查找 N 是向上查找 不想搜索了 输入 :set nol 就 ...
- 二叉堆的应用——查找长度为N数组中第M大数
看到这个题目首先想到是排序,那么时间复杂度自然就是O(NlgN).那么使用二叉堆如何解决呢? 对于下面一个数组,共有12个元素,我们的目标就是找出第5大元素——12 首先建立一个具有M个元素的最小堆, ...
- 数据结构---散列表查找(哈希表)概述和简单实现(Java)
散列表查找定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,是的每个关键字key对应一个存储位置f(key).查找时,根据这个确定的对应关系找到给定值的key的对应f(key) ...
- [Data Structure & Algorithm] 七大查找算法
查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找.本文简单概括性的介绍了常见的七种查找算法,说是七种,其实二分查找.插值查找以及斐波那契查找 ...
- 七大查找算法(附C语言代码实现)
来自:Poll的笔记 - 博客园 链接:http://www.cnblogs.com/maybe2030/p/4715035.html 阅读目录 1.顺序查找 2.二分查找 3.插值查找 4.斐波那契 ...
随机推荐
- wireshark使用方法
抓取报文: 下载和安装好Wireshark之后,启动Wireshark并且在接口列表中选择接口名,然后开始在此接口上抓包.例如,如果想要在无线网络上抓取流量,点击无线接口.点击Capture Opti ...
- PHP生成腾讯云COS请求签名
目标 使用 PHP 创建 COS 接口所需要的请求签名 步骤 按照官方示例(也许是我笨,我怎么读都觉得官方文档结构费劲,示例细节互相不挨着,容易引起歧义),请求签名应用在需要身份校验的场景,即非公有读 ...
- 设计模式(Design Patterns)Java版
设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了 ...
- 数据结构 之 二叉堆(Heap)
注:本节主要讨论最大堆(最小堆同理). 一.堆的概念 堆,又称二叉堆.同二叉查找树一样,堆也有两个性质,即结构性和堆序性. 1.结构性质: 堆是一棵被完全填满的二叉树,有可能的 ...
- Ubuntu物理机中解决VirtualBox虚拟机无法连接USB设备的问题
本文由荒原之梦原创,原文链接:http://zhaokaifeng.com/?p=611 问题描述: 在安装完VirtualBox的USB控制器扩展(关于在VirtualBox中安装USB控制器扩展的 ...
- Java 精简Jre jar打包成exe
#开始 最近几天都在忙一个事情,那就是尝试精简jre,我想不明白为什么甲骨文官方不出exe打包工具... 网络上精简jre的文章很多,但是原创的似乎没几个,绝大多数都是转发同一个博客, 这里借鉴了不少 ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- DataSourceBuilder.create().build()
Spring Boot also provides a utility builder class DataSourceBuilder that can be used to create one o ...
- Android 框架炼成 教你如何写组件间通信框架EventBus
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/41096639 ,本文出自:[张鸿洋的博客] 1.概述 关于Eventbus的介绍 ...
- python基础autopep8__python代码规范
关于PEP 8 PEP 8,Style Guide for Python Code,是Python官方推出编码约定,主要是为了保证 Python 编码的风格一致,提高代码的可读性. 官网地址:http ...