Python进阶7--正则表达式
正则表达式***
概述

分类

基本语法
元字符
^ 匹配字符串的开头
$ 匹配字符串的末尾。
. 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
[...] 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k'
[^...] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
re* 匹配0个或多个的表达式。
re+ 匹配1个或多个的表达式。
re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
re{ n} 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。
re{ n,} 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。
re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
a| b 匹配a或b
(re) 匹配括号内的表达式,也表示一个组
一些基本模式:
\w 匹配数字字母下划线,包括中文字
\W 匹配非数字字母下划线
\s 匹配任意空白字符,等价于 [\t\n\r\f]。
\S 匹配任意非空字符
\d 匹配任意数字,等价于 [0-9]。
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。
\z 匹配字符串结束
\G 匹配最后匹配完成的位置。
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。
#Python环境3.6.3
import re
a = '中国'
regex = re.compile('\w+')
res = regex.match(a)
print(res)
#输出结果如下:
# <_sre.SRE_Match object; span=(0, 2), match='中国'>



重复



#Python正则表达式里的单行re.S和多行re.M模式
默认情况下,一个包含换行符的字符串总是被当作多行处理。但是行首符^和行尾符$仅仅匹配整个字符串的起始和结尾。这个时候,包含换行符的字符串又好像被当作一个单行处理
参考:https://www.cnblogs.com/pugang/p/10123285.html#单行模式下,点号(.)匹配了包括换行符在内的所有字符。所以,更本质的说法是:单行模式re.DOTALL/re.S改变了点号(.)的匹配行为
#多行模式下,^除了匹配整个字符串的起始位置,还匹配换行符后面的位置;$除了匹配整个字符串的结束位置,还匹配换行符前面的位置.


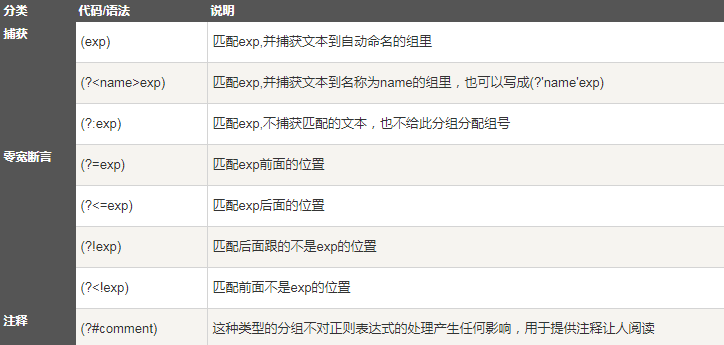
(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面,也不会拥有组号。

贪婪与非贪婪*

正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
修饰符 描述
re.I 使匹配对大小写不敏感(IgnoreCase)(re.DOTALL)
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响^和 $(Multiline)(re.MULTILINE)
re.S 使 . 匹配包括换行符在内的所有字符(Singleline)
re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X 忽略表达式中的空白字符,如果要使用空白字符用转义,#可以用来做注释(re.VERBOSE)
练习1
IP地址


import socket
nw = socket.inet_aton('192.168.05.001')
print(nw,socket.inet_ntoa(nw))

练习2
选出含有ftp的链接,且文件类型是gz或者xz的文件名


Python的正则表达式
python使用re模块提供了正则表达式处理的能力
常量
常量 说明
re.M/re.MULTILINE 多行模式
re.S/re.DOTALL 单行模式
re.I/re.IGNORECASE 忽略大小写
re.X/re.VERBOSE 忽略表达式中的空白字符
#使用|位或运算开启多项选择,如下例:
>>>import re
>>> a = 'This is the first line.\nThis is the second line.\nThis is the third line.'
>>> re.findall(r'^This.*?line.$', a, flags=re.DOTALL+re.MULTILINE)
['This is the first line.', 'This is the second line.', 'This is the third line.']
>>> re.findall(r'^This.*?line.$', a, flags=re.DOTALL | re.MULTILINE)
['This is the first line.', 'This is the second line.', 'This is the third line.']
方法
编译

单次匹配

import re s = '''bottle\nbag\nbig\napple'''
# for x in enumerate(s):
# if x[0]%8==0:
# print()
# print(x,end=' ')
# print('\n') #match:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
result = re.match('b',s)
print(1,result)
result = re.match('a',s)
print(2,result)
#先编译,然后使用正则表达式对象
regex = re.compile('a')
result = regex.match(s)#依旧重头开始找
print(3,result)
result = regex.match(s,15)#把索引15作为开始找
print(4,result) #search:扫描整个字符串并返回第一个成功的匹配
result = re.search('a',s)#search(pattern, string, flags=0):
print(5,result)
regex = re.compile('b')
result = regex.search(s,1)
print(6,result)
regex = re.compile('^b',re.M)#不管是不是多行模式,找到就返回
result =regex.search(s)#search(self, string, pos=0, endpos=-1):
print(7,result) #fullmatch:要完全匹配才会返回非None
result = re.fullmatch('bag',s)
print(8,result)
regex = re.compile('bag')
result = regex.fullmatch(s)
print(9,result)
result = regex.fullmatch(s,7,10)
print(10,result)
全部匹配

import re s = '''bottle\nbag\nbig\napple'''
#findall方法
result = re.findall('^b.*',s)
print(1,result)
regex = re.compile('^b.*',re.S)#单行模式结果:['bottle\nbag\nbig\napple']
result = regex.findall(s)
print(2,result)
regex = re.compile('^b.*',re.M)#多行模式结果:['bottle','bag', 'big']
result = regex.findall(s,7)
print(3,result)
result =re.finditer('^b.*',s)
print(4,result)
#finditer
result = regex.finditer(s)
print(type(result))
匹配替换

分割字符串

分组


练习
1.匹配邮箱地址
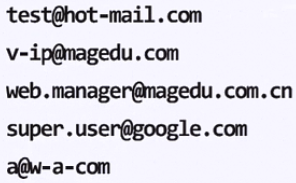
示例:^(\w[\w\.-]*)@(\w[\w\.-]*\.[a-zA-Z]+)
2.匹配html标记的中文内容

示例:(?<=>)\w+(?=<)
3.匹配URL

示例:(\w+)://[\S]+
4.匹配二代中国身份证
示例:\d{17}[xX\d]|\d{15}
5.强密码识别

#利用re模块进行wordcount
#defaultdict类的初始化函数接受一个类型作为参数,当所访问的键不存在的时候,可以实例化一个值作为默认值:
#defaultdict类除了接受类型名称作为初始化函数的参数之外,还可以使用任何不带参数的可调用函数,
# 到时该函数的返回结果作为默认值,这样使得默认值的取值更加灵活
from collections import defaultdict
import re def wordcount(path):
d = defaultdict(lambda :0) with open(path,encoding='utf-8')as f:
for line in f:
for sub in re.split('[^-\w]+',line):
if len(sub)>0:
d[sub.lower()] += 1 return d
Python进阶7--正则表达式的更多相关文章
- python进阶11 正则表达式
python进阶11 正则表达式 一.概念 #正则表达式主要解决什么问题? #1.判断一个字符串是否匹配给定的格式,判断用户提交的又想的格式是否正确 #2.从一个字符串中按指定格式提取信息,抓取页面中 ...
- python进阶(20) 正则表达式的超详细使用
正则表达式 正则表达式(Regular Expression,在代码中常简写为regex. regexp.RE 或re)是预先定义好的一个"规则字符率",通过这个"规 ...
- python进阶之正则表达式
概念: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑. 目的? 给定一个正则表 ...
- Python 进阶 - 正则表达式
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十 ...
- [.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门
[.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门 1. 什么是正则表达式? 1.1 正则表达式概念 正则表达式,又称正则表示法,英文名:Regular Expression(简 ...
- python模块 re模块与python中运用正则表达式的特点 模块知识详解
1.re模块和基础方法 2.在python中使用正则表达式的特点和问题 3.使用正则表达式的技巧 4.简单爬虫例子 一.re模块 模块引入; import re 相关知识: 1.查找: (1)find ...
- Python进阶(十二)----re模块
Python进阶(十二)----re模块 一丶re模块 re模块是python将正则表达式封装之后的一个模块.正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行. #正则表达式: ...
- 尚学python课程---15、python进阶语法
尚学python课程---15.python进阶语法 一.总结 一句话总结: python使用东西要引入库,比如 json 1.python如何创建类? class ClassName: :以冒号结尾 ...
- Python高手之路【五】python基础之正则表达式
下图列出了Python支持的正则表达式元字符和语法: 字符点:匹配任意一个字符 import re st = 'python' result = re.findall('p.t',st) print( ...
- python基础之正则表达式
正则表达式语法 正则表达式 (或 RE) 指定一组字符串匹配它;在此模块中的功能让您检查一下,如果一个特定的字符串匹配给定的正则表达式 (或给定的正则表达式匹配特定的字符串,可归结为同一件事). 正则 ...
随机推荐
- 【Android Studio安装部署系列】十九、Android studio使用SVN
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 概述 在AndroidStudio中开发版本控制,除了Git就是SVN,和Eclipse不同,Android Studio没有提供单独的插 ...
- 个人完善的springboot拦截器
import lombok.extern.slf4j.Slf4j; import org.manage.management.permission.interceptor.LoginIntercept ...
- 只需两步!Eclipse+Maven快速构建第一个Spring Boot项目
随着使用Spring进行开发的个人和企业越来越多,Spring从一个单一简介的框架变成了一个大而全的开源软件,最直观的变化就是Spring需要引入的配置也越来越多.配置繁琐,容易出错,让人无比头疼, ...
- 关于px,分辨率,ppi的辨析
概述 在本篇文章的开始,我先为大家解释一下这三个名词的概念. px全称为pixel--像素.pc及移动设备的屏幕就是通过往像素矩阵中填充颜色,从而在宏观上体现出图像.像素越小,图像越清晰. 分辨 ...
- MySql给表添加列和注释
1.给表添加列 ALTER TABLE supplier_seller ADD COLUMN company_id INT NULL COMMENT '供应主体id'; 默认情况下,添加的列会添加到最 ...
- html meta标签使用及属性介绍
自学前端开始,我对meta标签接触不多,主要把精力都集中在能显示出来的标签上,比如span.button.h1等等.有时候去查看一些知名网站的源码,发现head标签里有一大摞的meta. 今天就来学习 ...
- android - TextView单行显示...或者文字左右滚动(走马灯效果)
条件 TextView单行显示,文字左右滚动(走马灯效果)实现条件: 实现单行设置固定宽度或者设置权重都行 代码 TextView滚动必须写下面几个属性 android:singleLine=&quo ...
- findlibrary returned null
转载请标明出处,维权必究:https://www.cnblogs.com/tangZH/p/10181330.html 该错误是在加载so库的时候出现的,就是找不到so库. 一.检查jinLibs目录 ...
- 【English】九、kids/children/toddlers 三个单词的区别
一.child.kid.toddler 参考:https://www.zybang.com/question/a9150bb1239cf1d667135e9bd8518f75.html child:美 ...
- django mongodb配置
#settings.py import os from mongoengine import * BASE_DIR = os.path.dirname(os.path.dirname(os.path. ...