使用seaborn探索泰坦尼克号上乘客能否获救
titanic数据集是个著名的数据集.kaggle上的titanic乘客生还率预测比赛是一个很好的入门机器学习的比赛.
数据集下载可以去https://www.kaggle.com/c/titanic/data.
本身写这个系列笔记是作为自己机器学习的记录,也为了加深自己对机器学习相关知识的理解.但是写了前两篇seaborn的笔记以后,感觉缺乏实际的比赛数据的例子,写起来比较枯燥,读的人看的可能也很枯燥,浏览量也寥寥.读的人可能看完了会有一种,"哦,这样啊,原来如此,懂了懂了",然鹅,一拿到真实的数据,还是一筹莫展,无从下手.
所以,今天就拿真实的数据来学习一下seaborn要怎么用.怎么在开始正式的机器学习算法之前探索我们的数据关系.
titanic数据集给出了891行,12列已经标记的数据.即我们已知train.csv中891名乘客是否生还.我们需要预测test.csv中的418名乘客是否能够生还.
首先看一眼我们的数据.
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |

意思是一名名字叫harris的22岁男性乘客,乘坐三等仓,船上有1个兄弟姐妹/配偶,0个父母/子女,在Southampton上船,票价7.25,在此次灾难中没有生还.
拿到数据,我有几个简单的设想
- 票的级别越高,越容易获救 其实就是有钱有地位的容易获救
- 票价越高越容易获救 同上
- 兄弟姐妹或者父母子女多,容易获救 因为可以互相帮助
- 女性更容易获救
- 孩子更容易获救
好了,下面用seaborn来画画图,观察一下我们的数据,看看我拿到数据后第一想法对不对.
我主要用catplot 和 displot来绘图.
先来看看Pclass和Survived的关系.
catplot顾名思义,主要用来绘制分类数据(Categorical values).kind表示绘制什么样的图,bar,box,violin等等.
sns.catplot(x="Pclass",y="Survived", kind="bar", data=titanic_train);
以此为例,我们的数据集中Pclass的取值共有3种,1,2,3,分别表示一等票,二等票,三等票.
当我们选择bar图时,y轴绘制出的是一个矩形,表示的是"Survived"这个数据的均值.(默认是均值,也可以调整为中位值).由于我们的Survived取值只有0(遇难了),1(获救了).那么均值等于获救比例.
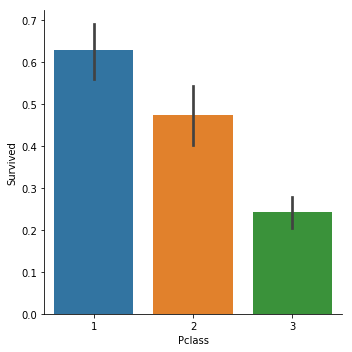
很明显1等票的生还率更高.
再来看下票价和生还之间的关系.
票价的数据各种各样,不像Pclass就3种.
sns.catplot(y="Fare",x="Survived", kind="bar", data=titanic_train);
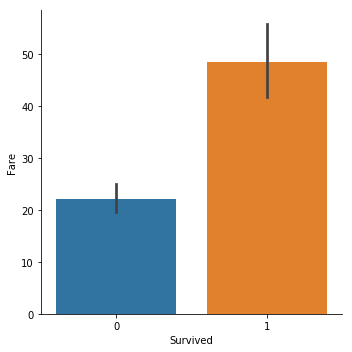
很明显,获救的人平均票价更高.
fare的值很多,我们想看看具体有哪些,大致的分布,可以用box.
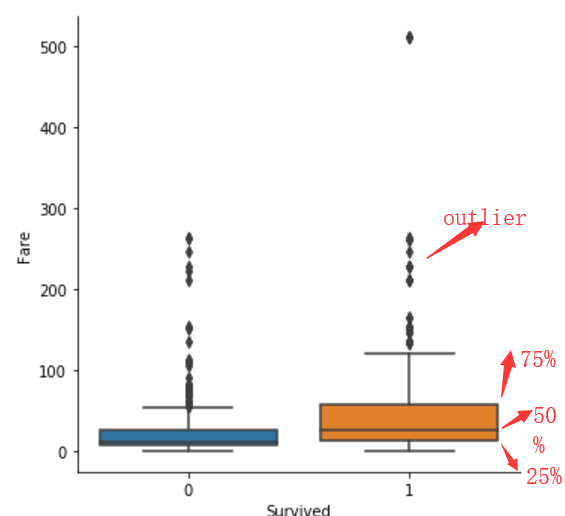
sns.catplot(y="Fare",x="Survived", kind="box", data=titanic_train);
box绘图,会绘制出一个箱体,并标注出数据的25%(Q1),50%(Q2),75%(Q3)及outlier处的位置.
其中怎么判断哪些点是属于异常值呢?根据IQR=Q3-Q1. 距离Q1或Q3的距离超过1.5IQR的就算是异常.
比如,下图的Q1=12 Q2=26 Q3=57.那么IQR=Q3-Q1=45. 超过Q3+1.5IQR=57+67.5=124.5的就会被算成异常点.会用黑色的小菱形绘制出来.
如果我们想要绘制出概率估计图.则可以用displot,或者kdeplot.这个在之前的文章里介绍过了.
sns.kdeplot(titanic_train["Fare"][(titanic_train["Survived"] == 1) & (titanic_train["Fare"].notnull())], shade=1, color='red')
sns.kdeplot(titanic_train["Fare"][(titanic_train["Survived"] == 0) & (titanic_train["Fare"].notnull())], shade=1, color='green');
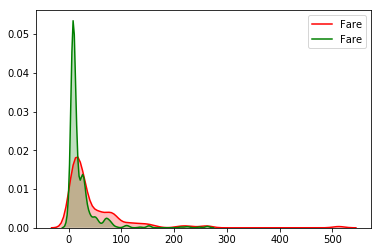
可以得到同样的结论,票价高的,获救概率更高一点.
注意:知识点来了
不止这一点,我们还看到,fare的分布并不是正态分布的,分布的极其不规则,也就是所谓的数据偏移,可以看到高收入的分布概率是很低的,但是高收入的样本分布确并不少,即假如我们把100认为高票价,一个人的票价是100以上的概率是很低的,但是在100-500之间分布的确很多,各种各样的都有.那机器学习算法在处理这个数据的时候就要注意了,要对数据做处理,可以用log函数做转换,或者你把0-20,20-50,50-100,100+的分别归类为1(很低),2(一般),3(较贵),4(很贵),用这种思想也可以.
实际上,对这个数据的处理,让我最终的预测率直接提高了2个百分点.
titanic_train["Fare"].skew()
可以通过这个skew()来检测数据的偏移度.如果数据偏移度比较高的话,如果skew()>0.75,一般需要对数据做分布变换,可以使用log变换.
这个skew()>0.75中的0.75怎么来的,我不太清楚,可能是一种经验值.我们的这个例子中skew()值已经接近5了.
下面来验证我们的猜想3,家人越多越容易得救
sns.catplot(x="SibSp",y="Survived", kind="bar", data=titanic_train);
sns.catplot(x="Parch",y="Survived", kind="bar", data=titanic_train);

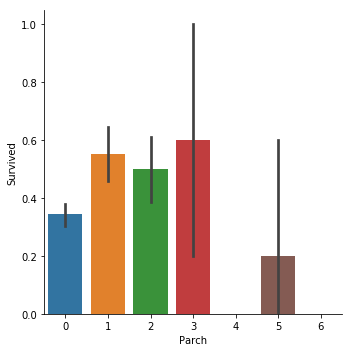
可以看到和我们的猜想并不一致,当有一个兄弟姐妹的时候,获救概率大概有0.55.而有4个兄弟姐妹的时候,获救概率反而只有0.15了.
在父母子女上,也是类似的,当父母子女达到5个的时候,获救概率反而低了.
titanic_train["family"] = titanic_train["SibSp"] + titanic_train["Parch"] + 1
sns.catplot(x="family",y="Survived", kind="bar", data=titanic_train);
我们创建一个新特征,家庭成员数,可以看到,当家庭人数比较少的时候,生还概率大.当家庭过于庞大,生还概率更低了.
猜想,是不是人少的时候,可以互相帮助,人多了,寻找家人会更困难,导致本可以获救的最终因为寻找家人也没活下来?

接下来看我们的猜想4,女人更容易获救
sns.catplot(x="Sex",y="Survived", kind="bar", data=titanic_train);
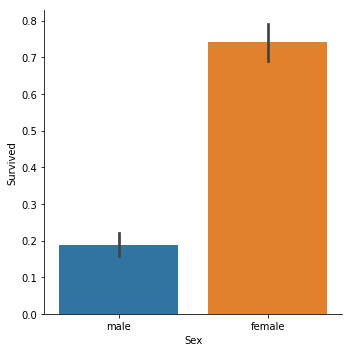
结论显而易见,女性获救概率高得多,lady first。
再来探索一下年龄与获救的关系,验证我们的猜想5.
sns.catplot(y="Age",x="Survived", kind="bar", data=titanic_train);

生还乘客的平均年龄是低了一点,但是两者区别不大,也都在正常区间,似乎看不出来什么.
我们来看看概率估计.
sns.kdeplot(titanic_train["Age"][(titanic_train["Survived"] == 1) & (titanic_train["Age"].notnull())], shade=1, color='red')
sns.kdeplot(titanic_train["Age"][(titanic_train["Survived"] == 0) & (titanic_train["Age"].notnull())], shade=1, color='green');
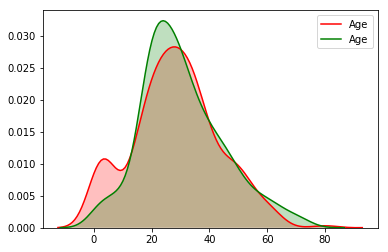
这个图就很明显了,在age很小的时候,红线(获救)明显有个波峰.说明在这个年级段,获救概率更高. 在age很大的时候(60岁以上),
绿线在红线之上,说明老人更可能遇难.
至此我们的5个猜想基本被验证,除了猜想3. 说明直觉还是比较准的嘛.
现在还剩下Name,Ticket,Cabin,Embarked这4个特征与Survived的关系没有验证.
其中Name,Ticket,Cabin都是不规则的字符串,需要做更多的特征工程,找到其中的规律以后,才好观察数据之间的关系.Embarked的取值只有S,C,Q3种.我们来看下Embarked与Survived的关系.
老套路:
sns.catplot(y="Survived", x = "Embarked",data = titanic_train, kind="bar")
C = Cherbourg, Q = Queenstown, S = Southampton
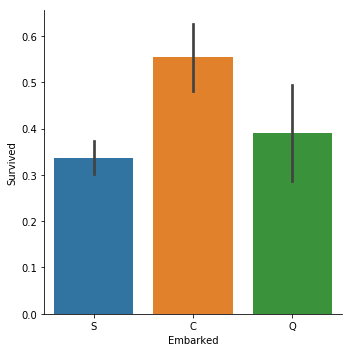
说实话,这个真的非常出乎我的意料.我原以为,是否生还和上船港口没有关系,三者的生还概率应该是基本一样才对.
然后我就开始胡思乱想了,总不能Cherbourg登船的人命好吧,越想越没道理.或者说Cherbourg登船的人都坐在船的某个位置,受到冰山撞击比较小?又或者只是因为样本数量太少了,是个偶然的巧合?
然后我想到是不是这个港口登船的都是有钱人?
sns.catplot(y="Fare", x = "Embarked",data = titanic_train, kind="bar")
sns.catplot(x="Pclass", hue="Embarked", data=titanic_train,kind="count")
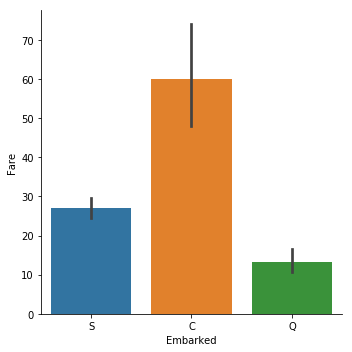
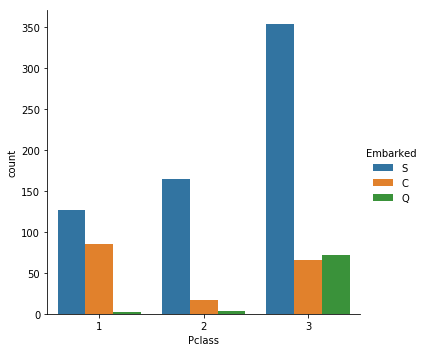
这么一看,还真是.所以Embarked=C的乘客生还概率高不是什么偶然.
所以这就引发了一个问题,数据之间其实有关联的,比如Embarked和Fare就有一定的相关性.我们可以用heatmap来探索各个特征数据之间的相关性.
sns.heatmap(titanic_train.corr(),annot=True,fmt ='.2f')
titanic_train.corr()计算出来的是各个特征的皮尔逊相关系数.皮尔逊相关系数。 wiki上解释一大堆,说实在的里面很多数学和统计学上的公式我没看懂.其实我们也不需要搞的特别清楚这些数学公式. 说白了,皮尔逊相关系数就是求两个向量之间的距离或者说夹角,越小越相关.(这个说法不严谨,但是原理上这么理解是没问题的).皮尔逊相关系数求出来在-1到1之间.

因为是求向量之间距离,所以展示的只有特征值是数字型的特征,Embarked特征的值是字符,所以没展示.你可以把字符映射成数字,比如S-->1,C-->2,Q-->3,再计算皮尔逊相关系数.当然这样做是有问题的.因为,S,C,Q本来不存在大小关系,这么映射以后存在了大小关系.这里涉及到一个one-hot编码问题.有兴趣的自己搜索一下,这篇就先不讲了.
ok,以上就是本篇文章使用seaborn探索titanic数据的内容,更多有趣有用的关于数据预处理可视化,关于seaborn使用等着大家去学习探索.希望这篇文章对大家有帮助和启发.
使用seaborn探索泰坦尼克号上乘客能否获救的更多相关文章
- 你能在泰坦尼克号上活下来吗?Kaggle的经典挑战
Kaggle Kaggle是一个数据科学家共享数据.交换思想和比赛的平台.人们通常认为Kaggle不适合初学者,或者它学习路线较为坎坷. 没有错.它们确实给那些像你我一样刚刚起步的人带来了挑战.作为一 ...
- deque、queue和stack深度探索(上)
deque是可双端扩展的双端队列,蓝色部分就是它的迭代器类,拥有四个指针,第一个cur用来指向当前元素,first指向当前buffer头部,last指向当前buffer尾部,node指向map自己当前 ...
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键: 1.要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看! 2.训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合: 3.欠拟合的话,说明模 ...
- Kaggle泰坦尼克数据科学解决方案
原文地址如下: https://www.kaggle.com/startupsci/titanic-data-science-solutions --------------------------- ...
- TensorFlow从1到2(十四)评估器的使用和泰坦尼克号乘客分析
三种开发模式 使用TensorFlow 2.0完成机器学习一般有三种方式: 使用底层逻辑 这种方式使用Python函数自定义学习模型,把数学公式转化为可执行的程序逻辑.接着在训练循环中,通过tf.Gr ...
- Kaggle案例泰坦尼克号问题
泰坦里克号预测生还人口问题 泰坦尼克号问题背景 - 就是那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇#### 的数量有限,无法人人都有,副船长发话了l ...
- 利用python进行泰坦尼克生存预测——数据探索分析
最近一直断断续续的做这个泰坦尼克生存预测模型的练习,这个kaggle的竞赛题,网上有很多人都分享过,而且都很成熟,也有些写的非常详细,我主要是在牛人们的基础上,按照数据挖掘流程梳理思路,然后通过练习每 ...
- 利用python分析泰坦尼克号数据集
1 引言 刚接触python与大数据不久,这个是学长给出的练习题目.知识积累太少,学习用了不少的时间.尽量详细的写,希望对各位的学习有所帮助. 2 背景 2.1 Kaggle 本次数据集来自于Kagg ...
- Kaggle 入门题-泰坦尼克号灾难存活预测
这个题目的背景概况来讲就是基于泰坦尼克号这个事件,然后大量的人员不幸淹没在这个海难中,也有少部分人员在这次事件之中存活,然后这个问题提供了一些人员的信息如姓名.年龄.性别.票价,所在客舱等等一些信息, ...
随机推荐
- layer的删除询问框的使用
删除是个很需要谨慎的操作 我们需要进行确认 对了删除一般使用ajax操作 因为如果同url请求 处理 再返回 会有空白页 1.js自带的样式 <button type="button& ...
- 聊聊Socket、TCP/IP、HTTP、FTP及网络编程
1 这些都是什么 既然是网络传输,涉及几个系统之间的交互,那么首先要考虑的是如何准确的定位到网络上的一台或几台主机,另一个是如何进行可靠高效的数据传输.这里就要使用到TCP/IP协议. 1.1 TCP ...
- 【STM32H7教程】第13章 STM32H7启动过程详解
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第13章 STM32H7启动过程详解 本章教 ...
- 记一次重大生产事故,在那 0.1s 我想辞职不干了!
一.发生了什么? 1.那是一个阳光明媚的下午,老婆和她的闺蜜正在美丽的湖边公园闲逛(我是拎包拍照的). 2.突然接到甲方运营小妹的微信:有个顾客线上付款了,但是没有到账,后台卡在微信支付成功(正常状态 ...
- 如何扩展分布式日志组件(Exceptionless)的Webhook事件通知类型?
写在前面 从上一篇博客高并发.低延迟之C#玩转CPU高速缓存(附示例)到现在又有几个月没写博客了,啥也不说,变得越来越懒了,懒惰产生了拖延后遗症. 最近一周升级了微服务项目使用的分布式日志组件Exce ...
- Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)
一.作业说明 给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(0.1分类). 训练集介绍: (1)CSV文件,大小为4000行X5 ...
- 在MySQL中实现Rank高级排名函数【转】
MySQL中没有Rank排名函数,当我们需要查询排名时,只能使用MySQL数据库中的基本查询语句来查询普通排名.尽管如此,可不要小瞧基础而简单的查询语句,我们可以利用其来达到Rank函数一样的高级排名 ...
- vue之$root,$parent
$root vue状态管理使用vuex,如果项目不大,逻辑不多,name我们没必要用vuex给项目增加难度,只需要用$root设置vue实例的data就行了,如下 main.js new Vue({ ...
- 驰骋工作流引擎-流程数据md5加密
关键字:工作流程数据加密 md5 数据保密流程数据防篡改软加密设置方式: 对工作流引擎的数据加密研究, 流程数据的加密方案与实现过程.输入图片说明需求背景1, 流程数据加密是为了防止流程数据被篡改 ...
- 驰骋工作流引擎-底层开发API 说明文档
驰骋工作引擎-底层开发API 登录与门户API 首先要进行代码集成与组织机构的集成 其次在自己的系统登录界面,登录成功后要执行ccbpm的框架登录. 所谓的登录就是调用ccbpm的登录接口,如左边的代 ...