推荐系统——online(上)
框架介绍
上一篇从总体上介绍了推荐系统,推荐系统online和offline是两个组成部分,其中offline负责数据的收集,存储,统计,模型的训练等工作;online部分负责处理用户的请求,模型数据的使用,online learning等。本篇因为online中有比较复杂的ranking,ranking又分为离线训练和online learning,本篇主要介绍online部分的reall,ranking部分下篇介绍。先从整体流程图开始绍,数据流分为两部分:
- 用户请求数据,一般是由用户下拉刷新或APP发送的默认请求,通过连接网关,请求发送到推进引擎;
- 用户产生[隐式反馈或显示反馈]1,这部分数据是由APP从后台收集,通过网关进入flume,然后进入kafka为后面模块使用做准备。
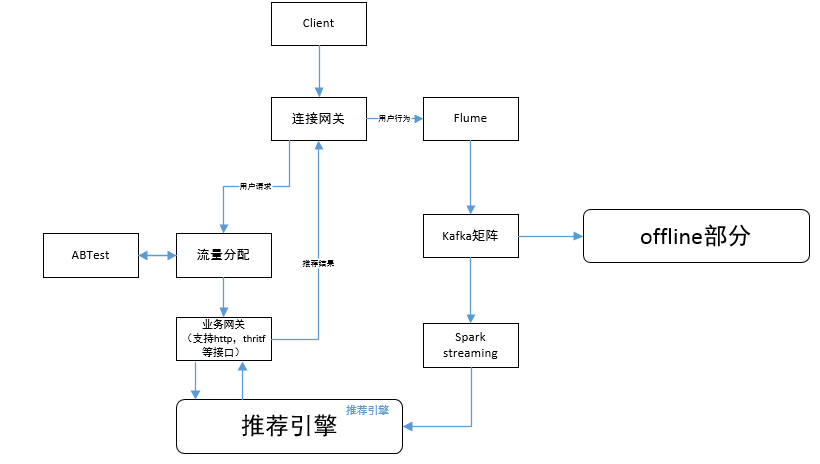
下面会根据这两部分展开讨论。
流量分配
这部分包括流量分配和ABTest两个模块,流量分配模块主要是根据需求来动态进行流量的分配,需要做到线上实时修改实时响应;ABTest是为Web和App的页面或流程设计两个版本(A/B)或多个版本(A/B/n),同时随机的分别让一定比例的客户访问,然后通过统计学方法进行分析,比较各版本对于给定目标的转化效果。你们可能觉得这两个模块功能有些冗余,其实并非如此,有一些单纯营运的需求是不需要进ABTest的。以视频推荐为例解释一下 这个问题,假设营运有这样的需求:“他们根据数据发现,iOS用户观看视频更喜欢购买会员进行免除广告,Andriod用户更倾向于观看网剧”(当然这只是一种假设),所以iOS在进行流量分配的时候会把付费视频比例提高,而Andriod会把原创网剧比例提高。然后新的一种算法或者UI希望知道是否会表现更好,这种情况就需要进行ABTest了,对照组和实验组里面iOS和Android都是包含的。这个部分并非是推荐系统的重点,以后有机会再开专题讲ABTest,所以这里就不再详细介绍了。
推荐引擎
推荐引擎主要就包括,gateway,recall(match),ranking,其中reall主要offline通过各种算法,最经典的就是基于用户行为的矩阵分解,包括itemCF、userCF、ALS,还有基于深度学习的wise&&deep等方法,后面讲offline的时候会着重说各种算法如何使用和适合的场景。
现在我们就默认为,各种算法已经训练完毕,然后会生成一些二进制文件,如下图,这些就是offline算法收敛后的权重向量结果

文件格式都是二进制,打开我们也看不懂,这里就不打开了,如果有人好奇可以私信我。这些产生后,如何到线上使用呢?用最土的办法,通过脚本每天定时cp到线上的server。也可以通过sql或者nosql数据库等方法,但是这个文件一般比较大,图里展示的只是我其中一个实验,日活大约百万级用户的训练结果数据,如果后面用户更多,item更丰富这个文件也就越大,使用数据库是不是好方式有待商榷。
gateway
这个模块只要负责用户请求的处理,主要功能包括请求参数检查,参数解析,结果组装返回。gateway业务比较轻量级,其中只有一个问题就是“假曝光”,假曝光是相对真曝光而言的,真曝光是指推送给用户的内容且用户看到了,假曝光就是指,推送给用户,但是未向用户展示的内容。推荐系统为了避免重复推荐,所以基于UUID存储推荐历史,存储时间是几小时,或者1天,再或几天,这个需要根据各自的业务情况,也要考虑资源库的大小。假曝光的处理可以在gateway中,把推送的message_id在gateway写入到nosql中,然后根据真曝光数据在离线pipeline中可以获取到,在离线pipeline定时运行时把假曝光的message_id的数据归还到recall队列中。
recall
用户请求到recall引擎后,会根据用户行为和相关配置,启动不同的召回器,下发召回任务,用户行为只要是看是否为新用户进冷启动,相关配置可能就是地区,国家等差异。用户的userprofile如果少于几个行为,一般建议为5-10个点击行为,少于这个标准属于冷启动用户,那么在recall manager的队列里只有冷启动召回器和热门召回器。热门召回器是为了保证推荐内容的热门度,而冷启动召回器是保证推荐结果的新鲜度。recall引擎还要负责任务分配,根据推荐场景,按召回源进行任务拆分,关键是让分布式任务到达负载均衡。
在各个召回器返回后recall manager收集返回结果,也就是各个召回器的返回的message_id的倒排队列,然后再进行一次整体的ranking。

下面再展开介绍一下召回器内部框架
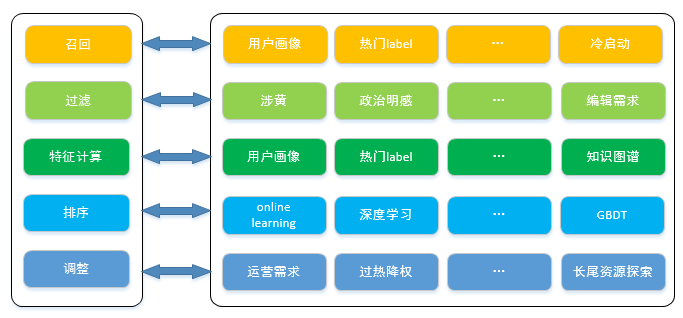
召回阶段,获取候选集,一般从基于用户画像、用户偏好、热门label等维度进行召回,如果是用户画像中点击少于10个会使用冷启动服务进行召回;
过滤阶段,对人工规则,涉黄,政治明感,政策因素,例如最近的未成年孕妇等进行过滤,总之计算保留合法的,合乎运营需要的结果;
特征计算阶段,结合用户实时行为、用户画像、知识图谱,计算出召回的候选集的特征向量;
排序阶段,使用算法模型对召回候选集进行粗排序,因为一般用户请求10条数据,召回样本大概在200-400个所以在召回器的排序内会进行序列重新调整。
- 调整阶段,在我们系统中调整策略有几十种,需要配合不同的运营需要,例如新闻内网比例要70%,头条的资源占10%,视频推荐中付费比例占40%等,调整可以理解为精细控制的过滤。
现在阶段召回,排序的都是message_id,并没有包含文章内容或是视频信息,这些内容会在ranking后,在detial服务中对推荐的返回结果的进行拼装,detail服务后还会有一层对整体结果的调整,下篇会详细介绍。
PS:最近小红和小熊都在忙着修改冷启动部分,后面会把我们的实践经验分享出来,经过了一个清明假期,更新有些晚了。
我们的文章只会迟到,从不缺席。
推荐系统——online(上)的更多相关文章
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- 【RS】Collaborative Memory Network for Recommendation Systems - 基于协同记忆网络的推荐系统
[论文标题]Collaborative Memory Network for Recommendation Systems (SIGIR'18) [论文作者]—Travis Ebesu (San ...
- 揭秘Keras推荐系统如何建立模型、获取用户爱好
你是否有过这样的经历?当你在亚马逊商城浏览一些书籍,或者购买过一些书籍后,你的偏好就会被系统学到,系统会基于一些假设为你推荐相关书目.为什么系统会知道,在这背后又藏着哪些秘密呢? 荐系统可以从百万甚至 ...
- hadoop实现购物商城推荐系统
1,商城:是单商家,多买家的商城系统.数据库是mysql,语言java. 2,sqoop1.9.33:在mysql和hadoop中交换数据. 3,hadoop2.2.0:这里用于练习的是伪分布模式. ...
- Paper Reading:个性化推荐系统的研究进展
论文:个性化推荐系统的研究进展 发表时间:2009 发表作者:刘建国,周涛,汪秉宏 论文链接:论文链接 本文发表在2009,对经典个性化推荐算法做了基本的介绍,是非常好的一篇中文推荐系统方面的文章. ...
- 推荐系统实践 0x0d GBDT+LR
前一篇文章我们介绍了LR->FM->FFM的整个演化过程,我们也知道,效果最好的FFM,它的计算复杂度已经达到了令人发指的\(n^2k\).其实就是这样,希望提高特征交叉的维度来弥补稀疏特 ...
- AFM论文精读
深度学习在推荐系统的应用(二)中AFM的简单回顾 AFM模型(Attentional Factorization Machine) 模型原始论文 Attentional Factorization M ...
- GBDT+LR算法解析及Python实现
1. GBDT + LR 是什么 本质上GBDT+LR是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题.这个方法出自于Facebook 2014年的论文 Practical L ...
- 推荐算法之用矩阵分解做协调过滤——LFM模型
隐语义模型(Latent factor model,以下简称LFM),是推荐系统领域上广泛使用的算法.它将矩阵分解应用于推荐算法推到了新的高度,在推荐算法历史上留下了光辉灿烂的一笔.本文将对 LFM ...
- O2O场景下的推荐排序模型:
推荐系统遇上深度学习(五)--Deep&Cross Network模型理论和实践 发表: 2018-04-22 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模型理论和实践:ht ...
随机推荐
- TPYBoard v102 DIY照相机(视频和制作流程)
前段时间的帖子,利用TPYBoard v102做的DIY照相机,周末实物终于做出来了,加了两个按键模块和一个5110,做的有点糙啊----望大家勿怪,哈哈哈.拍出来图片还算清晰,串口摄像头模块用的30 ...
- 【Zabbix】大规模监控误报发生时的处理方案
今天遇到了这样一件事..Zabbix一直在用的数据库突然间崩溃,无法连接了.在down掉的那一时刻开始,zabbix向管理员报了警.然后随之而来的是铺天盖地的所有主机zabbix agent无法连接的 ...
- 【windows】 配置一个本地的tomcat服务器
配置tomcat 公司的许多业务都是用java+tomcat模式的,做本地测试的时候经常要搭建一个自己的tomcat服务器.整个操作不难,但是记录一下,万一以后遇到什么问题也可以放这里. ■ 安装ja ...
- 大数据 --> Hadoop集群搭建
Hadoop集群搭建 1.修改/etc/hosts文件 在每台linux机器上,sudo vim /etc/hosts 编写hosts文件.将主机名和ip地址的映射填写进去.编辑完后,结果如下: 2. ...
- hibernate的一级和二级缓存
一级缓存就是Session级别的缓存,close后就没了. 二级缓存就是SessionFactory级别的缓存,全局缓存,要配置其他插件. 什么样的数据适合存放到第二级缓存中? 1.很少被修改的数据 ...
- C语言第四次作业--嵌套循环
一.PTA实验作业 题目1:打印九九口诀表 1.本题PTA提交列表 2.设计思路 (1)定义三个整形变量n,j,i,n表示任意给定的正整数. (2)输入一个正整数n. (3)令i=1,i<=n, ...
- Week1绪论--抽象数据类型
一.作业题目 1.构造有理数T,元素e1,e2分别被赋以分子.分母值 2.销毁有理数T 3.用e(引用类型参数)返回有理数T的分子或分母,当入参i为1时返回分子, i为2是返回分母. 4.将有理数T的 ...
- 下载文件downloadFile
public static void downLoadFile(InputStream inStream, String fileName) { if (StringUtils.isBlank(fil ...
- org.apache.jasper.JasperException: The absolute uri: http://java.sun.com/jsp/jstl/core cannot be res
解决:web项目出现如上问题,据查是版本问题: JSTL 1.0 的声明是: <%@ taglib prefix="c" uri="http://java.sun. ...
- android 广播安装指定下载的apk
// 广播出去,由广播接收器来处理下载完成的文件 Intent sendIntent = new Intent("com.test.downloadComplete"); ...