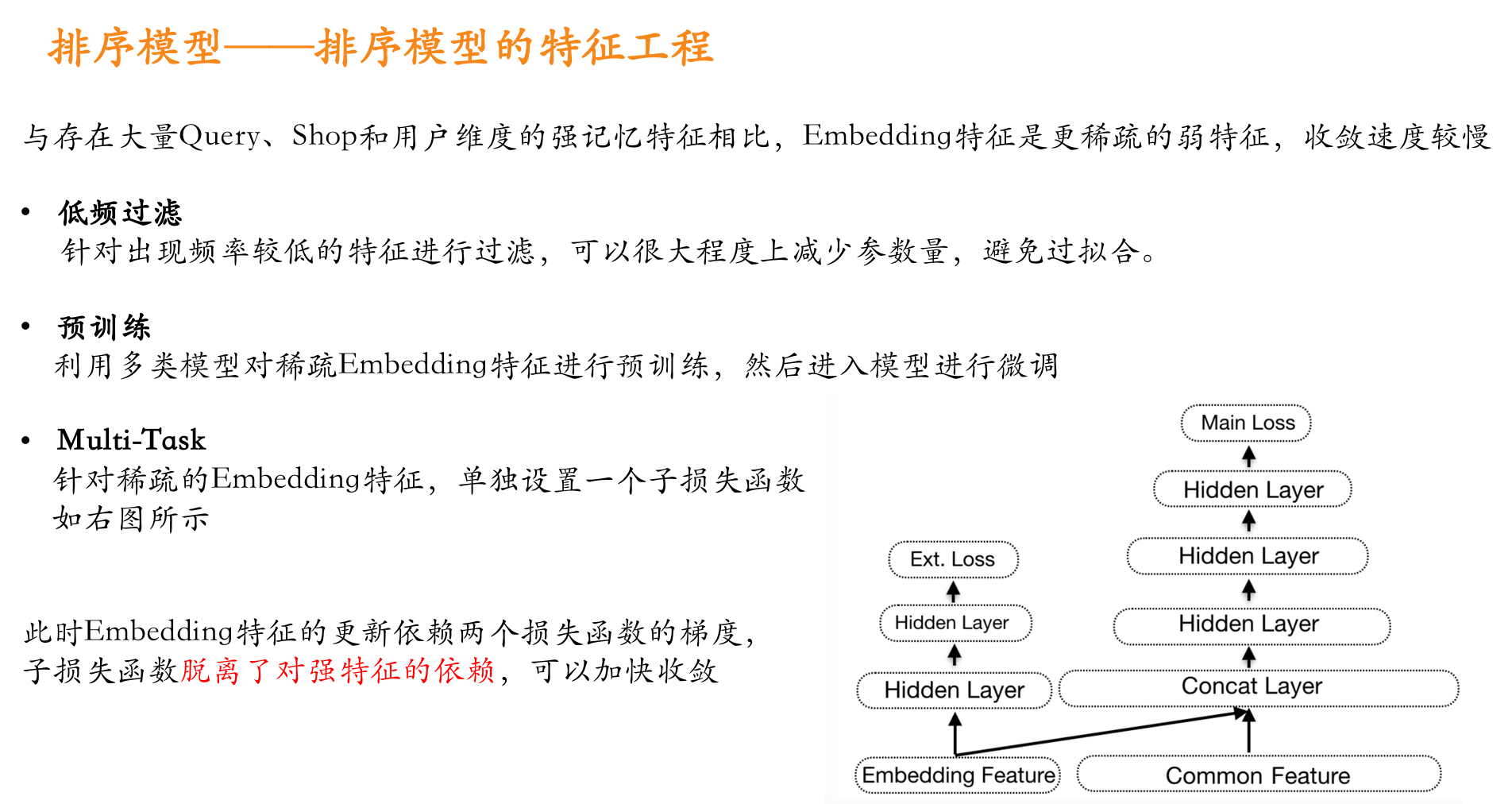
O2O场景下的推荐排序模型:


















推荐系统遇上深度学习(五)--Deep&Cross Network模型理论和实践
推荐系统遇上深度学习系列:
推荐系统遇上深度学习(一)--FM模型理论和实践:https://www.jianshu.com/p/152ae633fb00
推荐系统遇上深度学习(二)--FFM模型理论和实践:https://www.jianshu.com/p/781cde3d5f3d
推荐系统遇上深度学习(三)--DeepFM模型理论和实践:
https://www.jianshu.com/p/6f1c2643d31b
推荐系统遇上深度学习(四)--多值离散特征的embedding解决方案:https://www.jianshu.com/p/4a7525c018b2
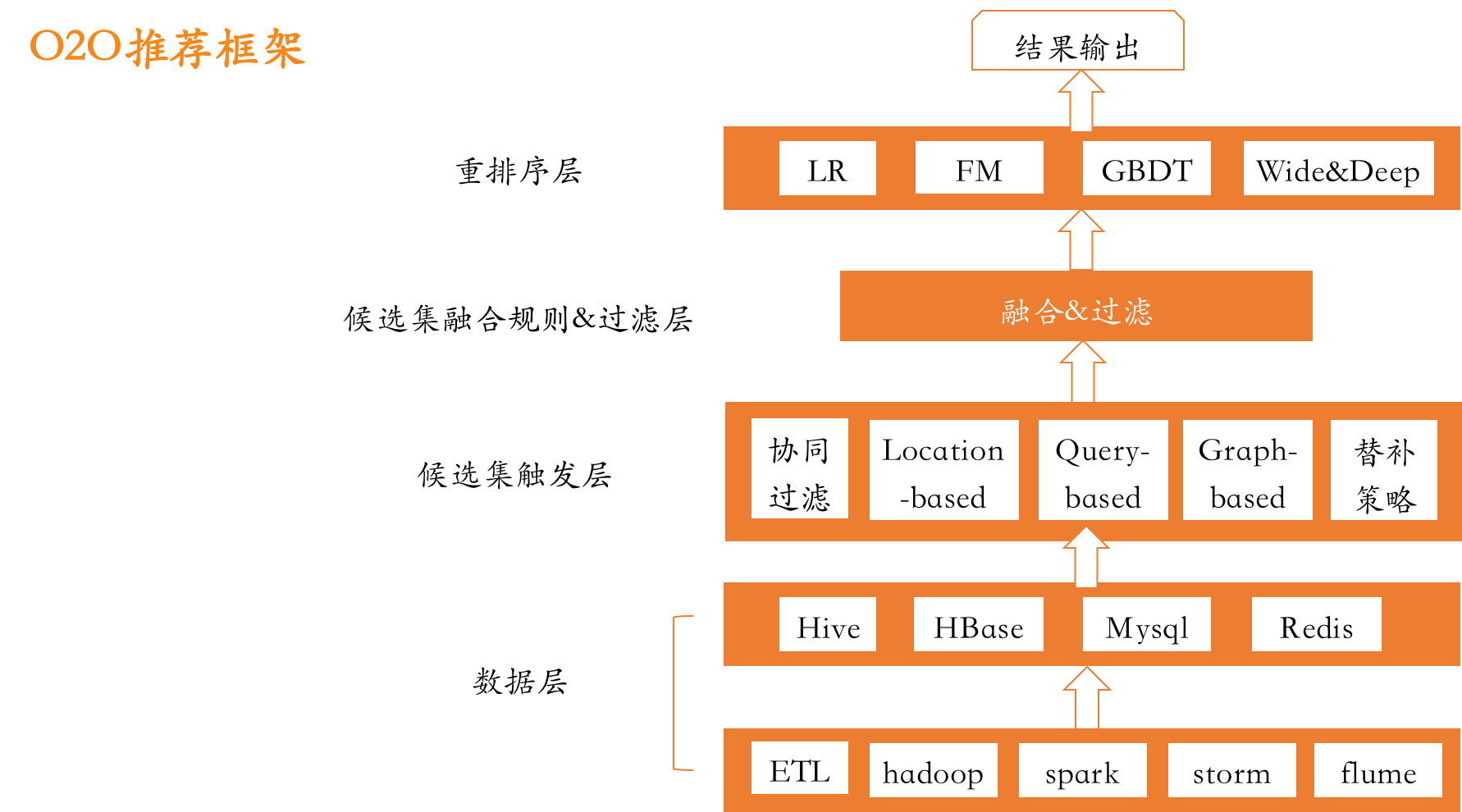
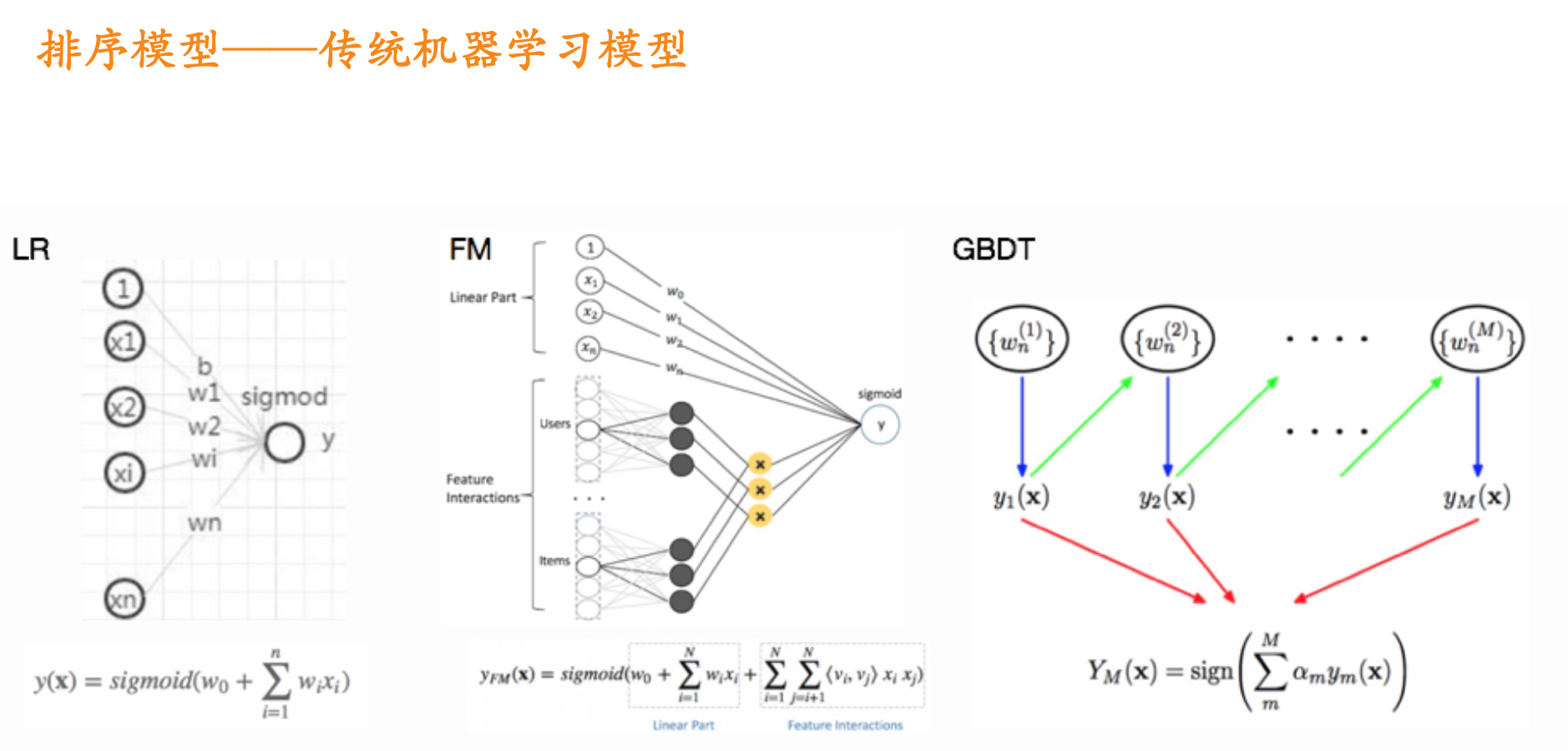
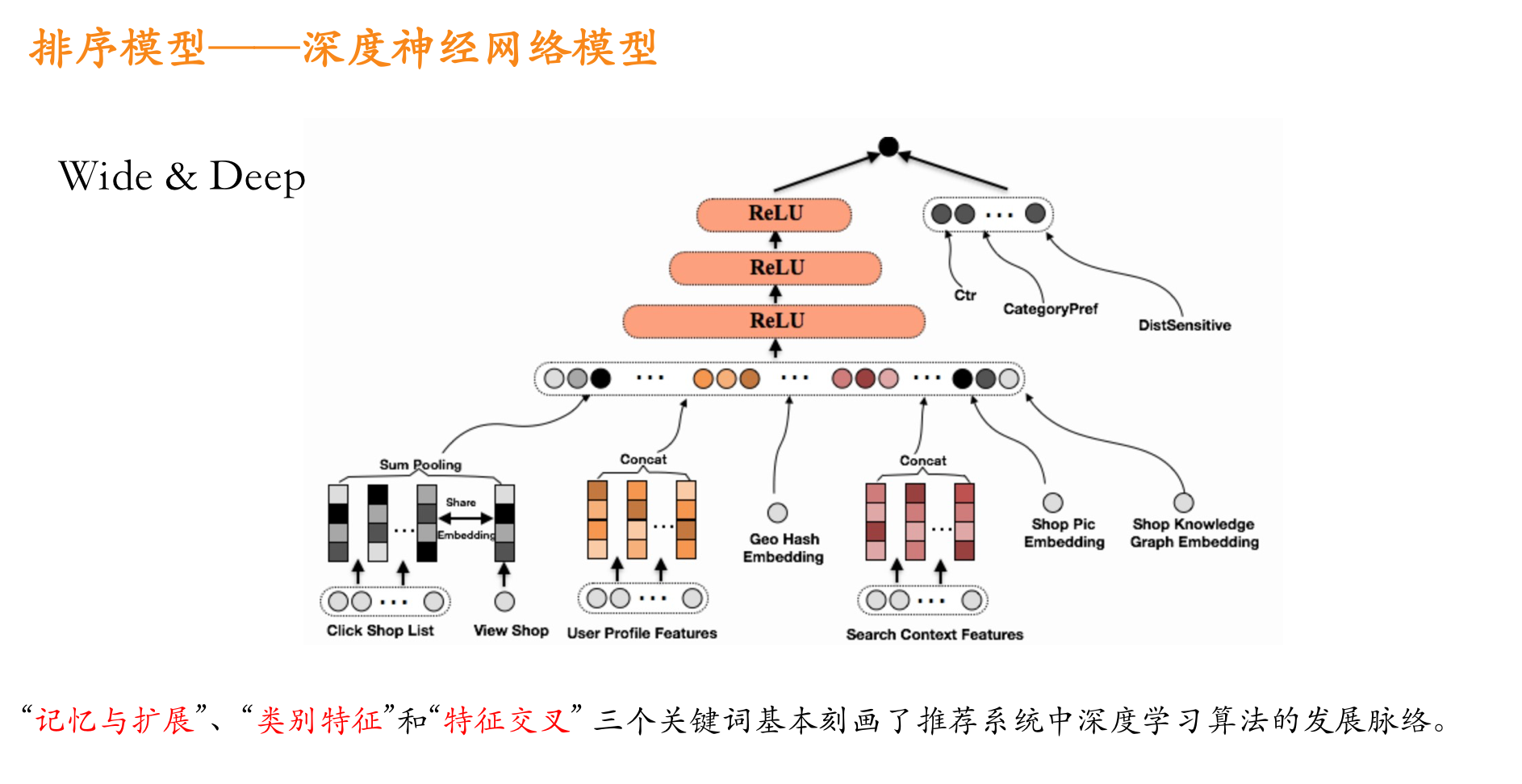
1、原理
Deep&Cross Network模型我们下面将简称DCN模型:
一个DCN模型从嵌入和堆积层开始,接着是一个交叉网络和一个与之平行的深度网络,之后是最后的组合层,它结合了两个网络的输出。完整的网络模型如图:

嵌入和堆叠层
我们考虑具有离散和连续特征的输入数据。在网络规模推荐系统中,如CTR预测,输入主要是分类特征,如“country=usa”。这些特征通常是编码为独热向量如“[ 0,1,0 ]”;然而,这往往导致过度的高维特征空间大的词汇。
为了减少维数,我们采用嵌入过程将这些离散特征转换成实数值的稠密向量(通常称为嵌入向量):

然后,我们将嵌入向量与连续特征向量叠加起来形成一个向量:

拼接起来的向量X0将作为我们Cross Network和Deep Network的输入
Cross Network
交叉网络的核心思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每个层具有以下公式:

一个交叉层的可视化如图所示:

可以看到,交叉网络的特殊结构使交叉特征的程度随着层深度的增加而增大。多项式的最高程度(就输入X0而言)为L层交叉网络L + 1。如果用Lc表示交叉层数,d表示输入维度。然后,参数的数量参与跨网络参数为:d * Lc * 2 (w和b)
交叉网络的少数参数限制了模型容量。为了捕捉高度非线性的相互作用,模型并行地引入了一个深度网络。
Deep Network
深度网络就是一个全连接的前馈神经网络,每个深度层具有如下公式:

Combination Layer
链接层将两个并行网络的输出连接起来,经过一层全链接层得到输出:

如果采用的是对数损失函数,那么损失函数形式如下:

总结
DCN能够有效地捕获有限度的有效特征的相互作用,学会高度非线性的相互作用,不需要人工特征工程或遍历搜索,并具有较低的计算成本。
论文的主要贡献包括:
1)提出了一种新的交叉网络,在每个层上明确地应用特征交叉,有效地学习有界度的预测交叉特征,并且不需要手工特征工程或穷举搜索。
2)跨网络简单而有效。通过设计,各层的多项式级数最高,并由层深度决定。网络由所有的交叉项组成,它们的系数各不相同。
3)跨网络内存高效,易于实现。
4)实验结果表明,交叉网络(DCN)在LogLoss上与DNN相比少了近一个量级的参数量。
这个是从论文中翻译过来的,哈哈。
2、实现解析
本文的代码根据之前DeepFM的代码进行改进,我们只介绍模型的实现部分,其他数据处理的细节大家可以参考我的github上的代码:
https://github.com/princewen/tensorflow_practice/tree/master/Basic-DCN-Demo
数据下载地址:https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
不去下载也没关系,我在github上保留了几千行的数据用作模型测试。
模型输入
模型输入
模型的输入主要有下面几个部分:
self.feat_index = tf.placeholder(tf.int32,
shape=[None,None],
name='feat_index')
self.feat_value = tf.placeholder(tf.float32,
shape=[None,None],
name='feat_value')
self.numeric_value = tf.placeholder(tf.float32,[None,None],name='num_value')
self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')
self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')可以看到,这里与DeepFM相比,一个明显的变化是将离散特征和连续特征分开,连续特征不在转换成embedding进行输入,所以我们的输入共有五部分。
feat_index是离散特征的一个序号,主要用于通过embedding_lookup选择我们的embedding。feat_value是对应离散特征的特征值。numeric_value是我们的连续特征值。label是实际值。还定义了两个dropout来防止过拟合。
权重构建
权重主要包含四部分,embedding层的权重,cross network中的权重,deep network中的权重以及最后链接层的权重,我们使用一个字典来表示:
def _initialize_weights(self):
weights = dict()
#embeddings
weights['feature_embeddings'] = tf.Variable(
tf.random_normal([self.cate_feature_size,self.embedding_size],0.0,0.01),
name='feature_embeddings')
weights['feature_bias'] = tf.Variable(tf.random_normal([self.cate_feature_size,1],0.0,1.0),name='feature_bias')
#deep layers
num_layer = len(self.deep_layers)
glorot = np.sqrt(2.0/(self.total_size + self.deep_layers[0]))
weights['deep_layer_0'] = tf.Variable(
np.random.normal(loc=0,scale=glorot,size=(self.total_size,self.deep_layers[0])),dtype=np.float32
)
weights['deep_bias_0'] = tf.Variable(
np.random.normal(loc=0,scale=glorot,size=(1,self.deep_layers[0])),dtype=np.float32
)
for i in range(1,num_layer):
glorot = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i]))
weights["deep_layer_%d" % i] = tf.Variable(
np.random.normal(loc=0, scale=glorot, size=(self.deep_layers[i - 1], self.deep_layers[i])),
dtype=np.float32) # layers[i-1] * layers[i]
weights["deep_bias_%d" % i] = tf.Variable(
np.random.normal(loc=0, scale=glorot, size=(1, self.deep_layers[i])),
dtype=np.float32) # 1 * layer[i]
for i in range(self.cross_layer_num):
weights["cross_layer_%d" % i] = tf.Variable(
np.random.normal(loc=0, scale=glorot, size=(self.total_size,1)),
dtype=np.float32)
weights["cross_bias_%d" % i] = tf.Variable(
np.random.normal(loc=0, scale=glorot, size=(self.total_size,1)),
dtype=np.float32) # 1 * layer[i]
# final concat projection layer
input_size = self.total_size + self.deep_layers[-1]
glorot = np.sqrt(2.0/(input_size + 1))
weights['concat_projection'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(input_size,1)),dtype=np.float32)
weights['concat_bias'] = tf.Variable(tf.constant(0.01),dtype=np.float32)
return weights
计算网络输入
这一块我们要计算两个并行网络的输入X0,我们需要将离散特征转换成embedding,同时拼接上连续特征:
# model
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K
feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])
self.embeddings = tf.multiply(self.embeddings,feat_value)
self.x0 = tf.concat([self.numeric_value,
tf.reshape(self.embeddings,shape=[-1,self.field_size * self.embedding_size])]
,axis=1)Cross Network
根据论文中的计算公式,一步步计算得到cross network的输出:
# cross_part
self._x0 = tf.reshape(self.x0, (-1, self.total_size, 1))
x_l = self._x0
for l in range(self.cross_layer_num):
x_l = tf.tensordot(tf.matmul(self._x0, x_l, transpose_b=True),
self.weights["cross_layer_%d" % l],1) + self.weights["cross_bias_%d" % l] + x_l
self.cross_network_out = tf.reshape(x_l, (-1, self.total_size))Deep Network
这一块就是一个多层全链接神经网络:
self.y_deep = tf.nn.dropout(self.x0,self.dropout_keep_deep[0])
for i in range(0,len(self.deep_layers)):
self.y_deep = tf.add(tf.matmul(self.y_deep,self.weights["deep_layer_%d" %i]), self.weights["deep_bias_%d"%i])
self.y_deep = self.deep_layers_activation(self.y_deep)
self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[i+1])
Combination Layer
最后将两个网络的输出拼接起来,经过一层全链接得到最终的输出:
# concat_part
concat_input = tf.concat([self.cross_network_out, self.y_deep], axis=1)
self.out = tf.add(tf.matmul(concat_input,self.weights['concat_projection']),self.weights['concat_bias'])定义损失
这里我们可以选择logloss或者mse,并加上L2正则项:
# loss
if self.loss_type == "logloss":
self.out = tf.nn.sigmoid(self.out)
self.loss = tf.losses.log_loss(self.label, self.out)
elif self.loss_type == "mse":
self.loss = tf.nn.l2_loss(tf.subtract(self.label, self.out))
# l2 regularization on weights
if self.l2_reg > 0:
self.loss += tf.contrib.layers.l2_regularizer(
self.l2_reg)(self.weights["concat_projection"])
for i in range(len(self.deep_layers)):
self.loss += tf.contrib.layers.l2_regularizer(
self.l2_reg)(self.weights["deep_layer_%d" % i])
for i in range(self.cross_layer_num):
self.loss += tf.contrib.layers.l2_regularizer(
self.l2_reg)(self.weights["cross_layer_%d" % i])剩下的代码就不介绍啦!
好啦,本文只是提供一个引子,有关DCN的知识大家可以更多的进行学习呦。
参考文章:
1、https://blog.csdn.net/roguesir/article/details/79763204
2、论文:https://arxiv.org/abs/1708.05123

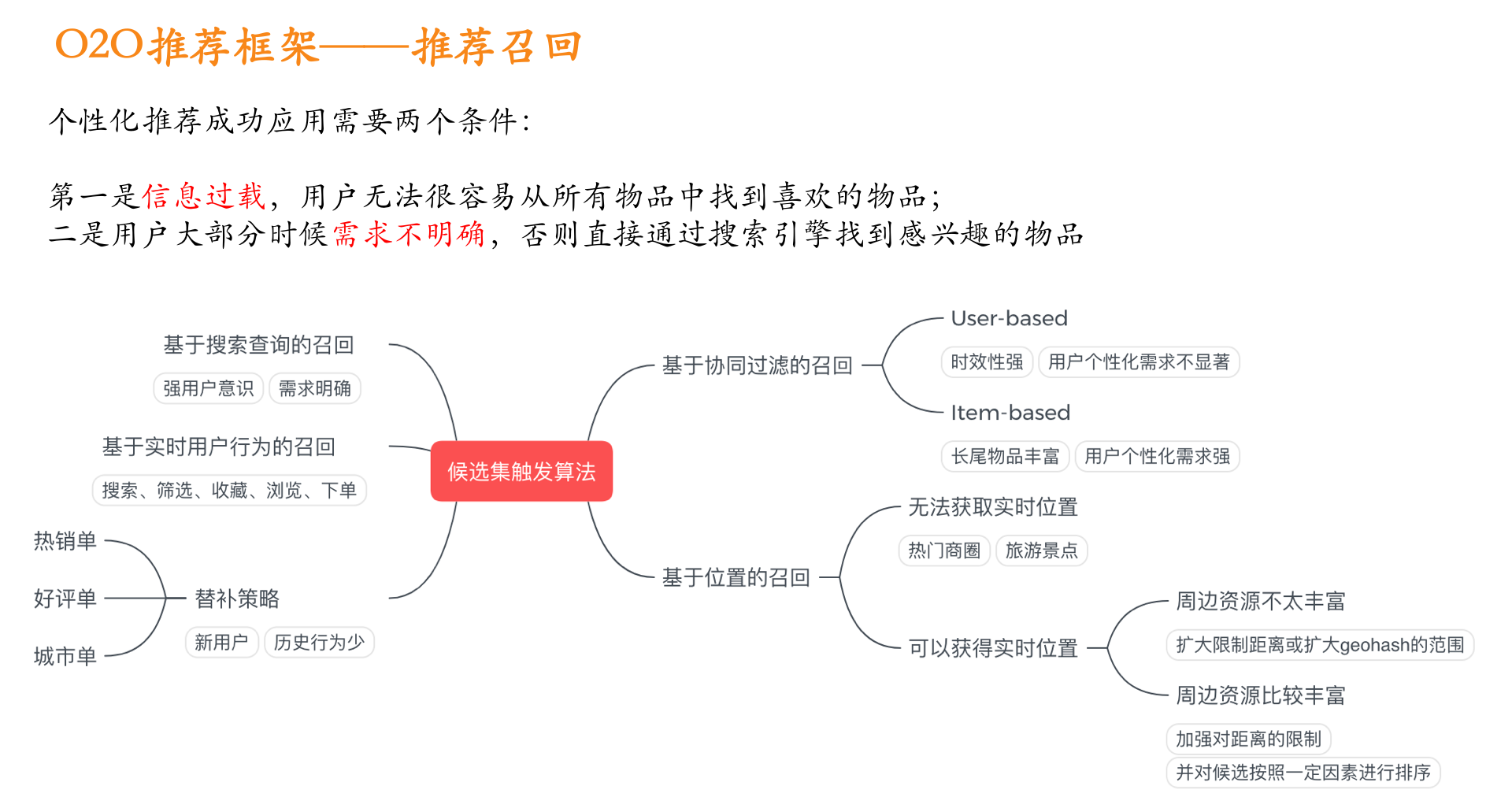
O2O场景下的推荐排序模型:的更多相关文章
- 美团在O2O场景下的广告营销
美团作为中国最大的在线本地生活服务平台,覆盖了餐饮.酒店.旅行.休闲娱乐.外卖配送等方方面面生活场景,连接了数亿用户和数百万商户.如何帮助本地商户开展在线营销,使得他们能快速有效地触达目标用户群体提升 ...
- Entity Framework:如果允许模型处于非法状态,在某些场景下,记得清空DbContext
Entity Framework:如果允许模型处于非法状态,在某些场景下,记得清空DbContext 背景 之前写过两篇文章介绍模型的合法性: DDD:关于模型的合法性,Entity.IsValid( ...
- 深度排序模型概述(一)Wide&Deep/xDeepFM
本文记录几个在广告和推荐里面rank阶段常用的模型.广告领域机器学习问题的输入其实很大程度了影响了模型的选择,因为输入一般维度非常高,稀疏,同时包含连续性特征和离散型特征.模型即使到现在DeepFM类 ...
- 大厂技术实现 | 腾讯信息流推荐排序中的并联双塔CTR结构 @推荐与计算广告系列
作者:韩信子@ShowMeAI,Joan@腾讯 地址:http://www.showmeai.tech/article-detail/tencent-ctr 声明:版权所有,转载请联系平台与作者并注明 ...
- CI Weekly #11 | 微服务场景下的自动化测试与持续部署
又一周过去了,最近我们的工程师正在搞一个"大事情" --「[flow.ci](http://flow.ci/?utm_source=bokeyuan&utm_medium= ...
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- 10.多shard场景下relevence score可能不准确
主要知识点 多shard场景下relevence score可能不准确的原因 多shard场景下relevence score可能不准确解决方式 一.多shard场景下relevance sc ...
- 难道主键除了自增就是GUID?支持k8s等分布式场景下的id生成器了解下
背景 主键(Primary Key),用于唯一标识表中的每一条数据.所以,一个合格的主键的最基本要求应该是唯一性. 那怎么保证唯一呢?相信绝大部分开发者在刚入行的时候选择的都是数据库的自增id,因为这 ...
- 硬核测试:Pulsar 与 Kafka 在金融场景下的性能分析
背景 Apache Pulsar 是下一代分布式消息流平台,采用计算存储分层架构,具备多租户.高一致.高性能.百万 topic.数据平滑迁移等诸多优势.越来越多的企业正在使用 Pulsar 或者尝试将 ...
随机推荐
- 【CF280D】k-Maximum Subsequence Sum(大码量多细节线段树)
点此看题面 大致题意: 给你一个序列,让你支持单点修改以及询问给定区间内选出至多\(k\)个不相交子区间和的最大值. 题意转换 这道题看似很不可做,实际上可以通过一个简单转换让其变可做. 考虑每次选出 ...
- 学习linux开发需要的基础
1.常见的通信协议I2C和SPI,熟悉. 还有时钟. 中断等概念也都了解了. 所以你现在应该先学一下Linux常用的一些命令,网上搜一下,有很多总结的文章,大概看一下用法,想深入学习的话,可以看鸟哥的 ...
- 大话设计模式Python实现-状态模式
状态模式(State Pattern):当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类 下面是一个状态模式的demo: #!/usr/bin/env python # -*- ...
- linux系统中启动daytime服务
环境:vmware下面的cetos6 1. 进入/etc/xinetd.d/目录下,查看是否存在daytime服务,若不存在,则须安装: 执行命令:yum install xinetd 该命令执行后会 ...
- app版本升级的测试点
移动端版本更新升级是一个比较重要的功能点,主要分为强制更新和非强制更新. 1.强制更新需要测试的点有: 1)强制升级是否可以升级成功 从老版本的包升级到新版版的包是否可以升级成功. 2)升级后的数据是 ...
- Docker安装使用以及mlsql的docker安装使用说明
1.检查内核版本,必须是3.10及以上 uname -r 2.安装 yum -y install docker #1.启动 docker systemctl start docker #1.1.验 ...
- Vue动态修改网页标题
业务需求,进入页面的时候,网页有个默认标题,加载的网页内容不同时,标题需要变更. 例:功能授权,功能授权(张三). Vue下有很多的方式去修改网页标题,这里总结下解决此问题的几种方案: 一.最笨方案 ...
- SqlServer 创建数据库两种方式
一个SqlServer 数据库实例大概可以创建三万多个数据库. 创建数据库的第一种方式:SqlServer Management Studio管理工具进行可视化创建. 1).打开数据库管理工具,在&q ...
- APS.NET MVC + EF (06)---模型
在实际开发中,模型往往被划分为视图模型和业务模型两部分,视图模型靠近视图,业务模型靠近业务,但是在具体编码上,它们之间并不是隔离的. 6.1 视图模型和业务模型 模型大多数时候都是用来传递数据的.然而 ...
- Postman 调试请求Asp.Net Core3.0 WebApi几种常见的Get/Post/Put/Delete请求
这里就直接截图了,如下(很简单的操作): 1:Get几种请求 2:Post 3:Put 4:Delete 最后,虽然简单,代码还是给放一下(这里只是抛砖引玉的作用,自己可以根据自身的业务需要来做进一 ...