python爬虫-淘宝商品密码(图文教程附源码)
今天闲着没事,不想像书上介绍的那样,我相信所有的数据都是有规律可以寻找的,然后去分析了一下淘宝的商品数据的规律和加密方式,用了最简单的知识去解析了需要的数据。
这个也让我学到了,解决问题的方法不止一个,我们要常常学会去思考,学会去学习,相信我们爬虫还是可以拿到我们想要的一切需要的数据。
我也对数据感兴趣,就是感觉,世间万物都是有规律可寻的,就看我们能不能去发现其中的秘密。
当我们去解决一个问题的时候,那一种成就感是别人难以体会的。只有我们去亲身体验才会感到真正的幸福。
所用模块:
re+requests+json
所用环境:
windows10 + pycharm
实战分析:
第一步:根据url来在google chrome中分析数据


分析的结果是:数据就是通过json来存储的
第二步:
得到网页的源码

第三步把得到的数据进行解析

第四步:对数据进行解密
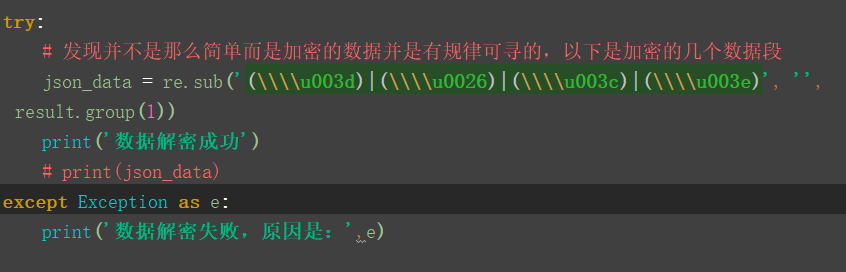
第五步:就可以把json的数据拿到并分析得到相应的数据

以下是源码:
import json
import re import requests # 在搜索框中输入美食得到的数据q=%E7%BE%8E%E9%A3%9F
url = 'https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F'
response = requests.get(url)
# print(response.text) # 用正则对html源码进行解析到一个json数据
pattern = re.compile('g_page_config =(.*?});', re.S)
result = re.search(pattern, response.text)
# print(result.group(1))
try:
# 发现并不是那么简单而是加密的数据并是有规律可寻的,以下是加密的几个数据段
json_data = re.sub('(\\\\u003d)|(\\\\u0026)|(\\\\u003c)|(\\\\u003e)', '', result.group(1))
print('数据解密成功')
# print(json_data)
except Exception as e:
print('数据解密失败,原因是:',e) # json_dumps = json.dumps(json_data)
# print(json_dumps)
data_count = 1
data = json.loads(json_data)
# 分析json的数据并把需要的数据给读取出来
for good in data['mods']['itemlist']['data']['auctions']:
print('商店名:{},商品标题:{},\n商品图片:{},\n商品产地:{},商品价格:{},付款人数:{},\n'.format(good['nick'], good['title'], good['pic_url'], good['item_loc'], good['view_price'],good['view_sales']))
data_count += 1 print(data_count)
python爬虫-淘宝商品密码(图文教程附源码)的更多相关文章
- 淘宝数据库OceanBase SQL编译器部分 源码阅读--生成物理查询计划
淘宝数据库OceanBase SQL编译器部分 源码阅读--生成物理查询计划 SQL编译解析三部曲分为:构建语法树,制定逻辑计划,生成物理执行计划.前两个步骤请参见我的博客<<淘宝数据库O ...
- 淘宝数据库OceanBase SQL编译器部分 源码阅读--生成逻辑计划
body, td { font-family: tahoma; font-size: 10pt; } 淘宝数据库OceanBase SQL编译器部分 源码阅读--生成逻辑计划 SQL编译解析三部曲分为 ...
- 《淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树》
淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树 曾经的学渣 2014-06-05 18:38:00 浏览1455 云数据库Oceanbase OceanBase是 ...
- PHP简单的长文章分页教程 附源码
PHP简单的长文章分页教程 附源码.本文将content.txt里的内容分割成3页,这样浏览起来用户体验很好. 根据分页参数ipage,获取对应文章内容 include('page.class.php ...
- python 获取淘宝商品信息
python cookie 获取淘宝商品信息 # //get_goods_from_taobao import requests import re import xlsxwriter cok='' ...
- Python爬虫--淘宝“泸州老窖”
爬虫淘宝--"泸州老窖" 爬去淘宝"泸州老窖" 相关信息: import requests import re import json import panda ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 安卓sdk webview获取淘宝个人信息100项,源码。
1.贴出主要代码.这个不是python,python只涉及了服务端对信息提取结果的接受.主体是java + android + js.由于淘宝各模块都是二级子域名,不能只在一个页面完成所有请求,aj ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
随机推荐
- 20165234 《Java程序设计》第五周学习总结
第五周学习总结 教材学习内容总结 第七章 内部类与异常类 内部类 内部类:在一个类中定义另一个类. 外嵌类:包含内部类的类,称为内部类的外嵌类. 内部类的类体中不能声明类变量和类方法.外嵌类的类体中可 ...
- C# 判断网络是否连接
bool isconn = true; PingReply pr; Ping ping = new Ping(); pr = ping.Send("lightyiyi.cn"); ...
- 20165325《Java程序设计》第九周学习总结
一.教材学习笔记 ch13 1.URL类 URL类是java.net包中的一个重要的类,URL的实例封装着一个统一资源定位符,使用URL创建对象的应用程序称作客户端程序. 一个URL对象通常包含最基本 ...
- 集合排序 Comparator和Comparable的使用区别
Java 排序 Compare Comparator接口 Comparable接口 区别 在Java中使用集合来存储数据时非常常见的,集合排序功能也是常用功能之一.下面看一下如何进行集合排序,常用的 ...
- python3-元类
原文出处:http://www.cnblogs.com/linhaifeng/articles/8029564.html exec的使用 #可以把exec命令的执行当成是一个函数的执行,会将执行期间产 ...
- 巧用这19条MySQL优化【转】
1.EXPLAIN 做MySQL优化,我们要善用EXPLAIN查看SQL执行计划. 下面来个简单的示例,标注(1.2.3.4.5)我们要重点关注的数据: type列,连接类型.一个好的SQL语句至少要 ...
- Kafka监控KafkaOffsetMonitor【转】
1.概述 前面给大家介绍了Kafka的背景以及一些应用场景,并附带上演示了Kafka的简单示例.然后,在开发的过程当中,我们会发现一些问题,那就是消息的监控情况.虽然,在启动Kafka的相关服务后,我 ...
- 使用new data计算时间以及格式转换
1.时间计算,往后加30(默认一个月的时间),sxTime表示的是在当前时间往后加几天的之后一个月 function maxDate1(){ var nowDate = new Date(); max ...
- python3+selenium入门05-元素操作及常用方法
学习了元素定位之后,来看一些元素的操作,还有一些常用的方法 clear()清空输入框内容 click()点击 send_keys()键盘输入 import time from selenium imp ...
- Windows下文件夹扩展名
回收站.{645ff040-5081-101b-9f08-00aa002f954e} 拨号网络.{992CFFA0-F557-101A-88EC-00DD010CCC48} 打印机.{2227a280 ...