Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程
第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下

点击Network之后出现如下内容:

第二步:进入如下页面分析Network中的内容(网址、编码方式一般为gbk)


第三步:程序详细分析如下所示:
# _*_ utf-8 _*_:
# author:Administrator
from urllib import request #导入请求库,有的版本是import requests
import re #用于正则表达式
first_url="http://www.quanshuwang.com/book/9/9055" #你所需要下载的小说的网址
html=request.urlopen(first_url).read().decode('gbk') #上图箭头所示
novel_info={} #创建一个空的字典,注意不是空的集合序列
novel_info['title']=re.findall(r' <div class="chapName">.*<strong>(.*)</strong>',html) #()中的正则表达式,提取的内容放到novel_info里面 re.findall返回的是一个列表 而之后要把它转化为字符串处理 一定要注意那些是列表那些是字符串
novel_info['author']=re.findall(r' <div class="chapName"><span class="r">作者:(.*)</span><strong>盗墓笔记</strong><div class="clear"></div></div>',html)
div_info=re.findall(r'<DIV class="clearfix dirconone">(.*?)</DIV> ',html,re.S|re.I)[0] #此处在re.finall()返回一个序列,序列里只有一个元素,在后面加个[0]将他访问出来,转化为字符串,re.S|re.I不能丢否则得到空集
#获取每一个章节的地址
tag_a=re.findall(r'<a.*?</a>',div_info)
#循环每个章节依次获得内容
for i in range(0,60):
chapter_title = re.findall(r'title="(.*?)"', tag_a[i])[0]
chapter_url=re.findall(r'href="(.*?)"',tag_a[i])[0]
chapter_content=request.urlopen( chapter_url).read().decode('gbk') #与上面的思路一样
chapter_text = re.findall(r'<div class="mainContenr" (.*)style6', chapter_content, re.I | re.S)[0]
# print(chapter_content)
chapter_clear = chapter_text.replace(r" ", "") #都是清洗数据的步骤,可以依据具体环境而定
chapter_clear1 = chapter_clear.replace(r"<br />", "")
chapter_clear2 = chapter_clear1.replace(r'id="content"><script type="text/javascript">style5();</script>', "")
chapter_clear3 = chapter_clear2.replace(r'<script type="text/javascript">', "")
file = open(r'E:\老九门全书网.txt', 'a')
file.write(chapter_title+'\n'+chapter_clear3+'\n\n') #文件的读写操作
print(chapter_title)
file.close()
其他:
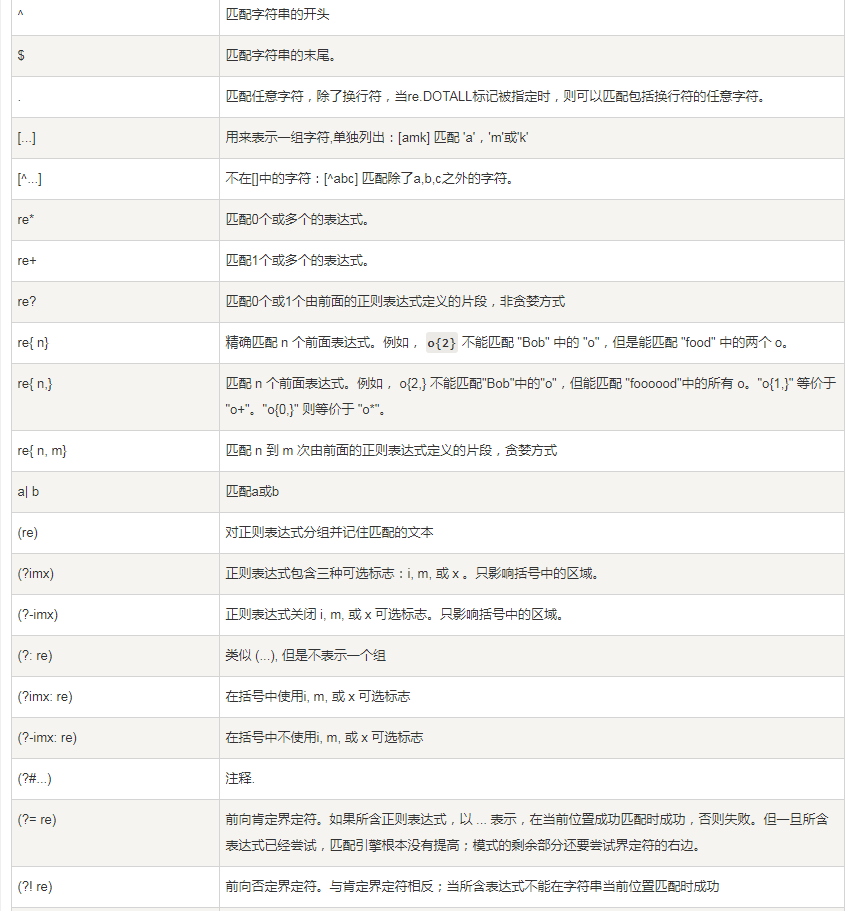
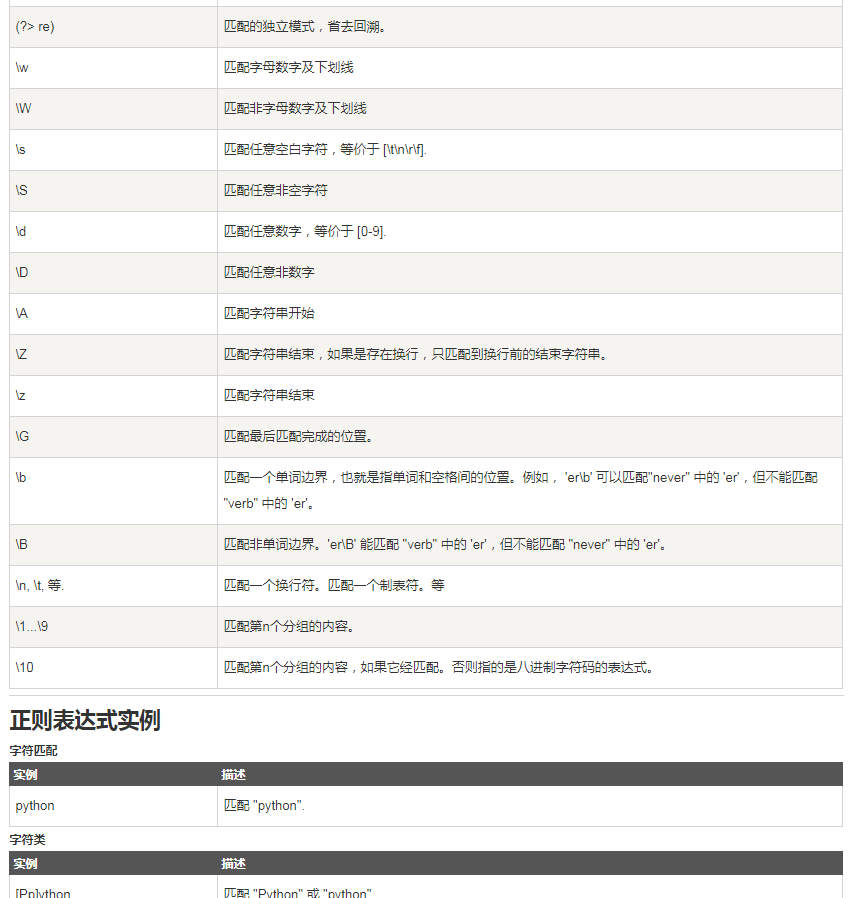
正则表达式附录:


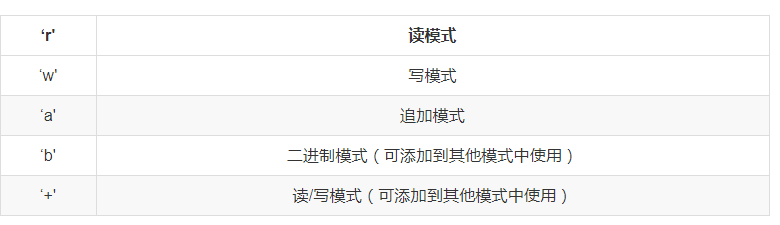
Python文件读写:
Python爬虫爬取全书网小说,程序源码+程序详细分析的更多相关文章
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- Python爬虫 爬取百合网的女人们和男人们
学Python也有段时间了,目前学到了Python的类.个人感觉Python的类不应称之为类,而应称之为数据类型,只是数据类型而已!只是数据类型而已!只是数据类型而已!重要的事情说三篇. 据书上说一个 ...
- python爬虫爬取赶集网数据
一.创建项目 scrapy startproject putu 二.创建spider文件 scrapy genspider patubole patubole.com 三.利用chrome浏览器 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
随机推荐
- ThinkPHP 5.0 配置
ThinkPHP 5.0 配置 目录 <!-- 系统默认的配置文件目录就是应用目录(APP_PATH), 也就是默认的application下面,并分为应用配置 (整个应用有效)和模块配置(仅针 ...
- Python生成器和构造器
什么是生成器? 参考link:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00 ...
- 0728 history
-- :: cd /etc/yum.repos.d/ -- :: wget http://download.virtualbox.org/virtualbox/rpm/rhel/virtualbox. ...
- 转发后找不到css
当在jsp中引入css时,如果其相对路径相对于当前jsp文件的,而在一个和这个jsp的路径不一样的servlet中forward这个jsp时,就会发现这个css样式根本没有起作用. 这是因为在serv ...
- python 的几种数据类型
列表 列表是 Python 的主力数据类型.当提到 " 列表 " 时,您脑海中可 能会闪现" 必须进一步声明大小的数组,只能包含同一类对象 " 等想法.千 ...
- 【Python-Django】浏览器同源策略
1995年,同源政策由 Netscape 公司引入浏览器.目前,所有浏览器都实行这个政策. 同源策略是浏览器的一个安全功能,不同源的客户端脚本(js文件)在没有明确授权的情况下,不能读写对方资源.只有 ...
- linux自学
Linux文件与目录管理 所有不太会的命令,可以用man +命令,查看相关解释文档 绝对路径:从根路径写起的路径,/usr/local 相对路径:例如:路径a:~/demo/test 路径b ...
- Mobile game forensics
My friend Carrie'd like to know "Garena 传说对决" violates any mobile risks such as insecure d ...
- Sring 的 @AliasFor 使用规则
一.该标签存在的意义 顾名思义 @AliasFor 表示别名,它可以注解到自定义注解的两个属性上,表示这两个互为别名,也就是说这两个属性其实同一个含义.该标签存在的含义,从网上查发现有个点, 若 自 ...
- java8中用流收集数据
用流收集数据 汇总 long howManyDishes = menu.stream().collect(Collectors.counting()); int totalCalories = men ...