python爬虫-淘宝商品密码(图文教程附源码)
今天闲着没事,不想像书上介绍的那样,我相信所有的数据都是有规律可以寻找的,然后去分析了一下淘宝的商品数据的规律和加密方式,用了最简单的知识去解析了需要的数据。
这个也让我学到了,解决问题的方法不止一个,我们要常常学会去思考,学会去学习,相信我们爬虫还是可以拿到我们想要的一切需要的数据。
我也对数据感兴趣,就是感觉,世间万物都是有规律可寻的,就看我们能不能去发现其中的秘密。
当我们去解决一个问题的时候,那一种成就感是别人难以体会的。只有我们去亲身体验才会感到真正的幸福。
所用模块:
re+requests+json
所用环境:
windows10 + pycharm
实战分析:
第一步:根据url来在google chrome中分析数据


分析的结果是:数据就是通过json来存储的
第二步:
得到网页的源码

第三步把得到的数据进行解析

第四步:对数据进行解密
第五步:就可以把json的数据拿到并分析得到相应的数据

以下是源码:
import json
import re import requests # 在搜索框中输入美食得到的数据q=%E7%BE%8E%E9%A3%9F
url = 'https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F'
response = requests.get(url)
# print(response.text) # 用正则对html源码进行解析到一个json数据
pattern = re.compile('g_page_config =(.*?});', re.S)
result = re.search(pattern, response.text)
# print(result.group(1))
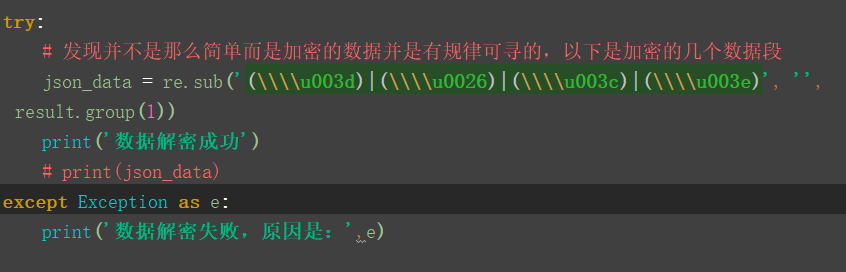
try:
# 发现并不是那么简单而是加密的数据并是有规律可寻的,以下是加密的几个数据段
json_data = re.sub('(\\\\u003d)|(\\\\u0026)|(\\\\u003c)|(\\\\u003e)', '', result.group(1))
print('数据解密成功')
# print(json_data)
except Exception as e:
print('数据解密失败,原因是:',e) # json_dumps = json.dumps(json_data)
# print(json_dumps)
data_count = 1
data = json.loads(json_data)
# 分析json的数据并把需要的数据给读取出来
for good in data['mods']['itemlist']['data']['auctions']:
print('商店名:{},商品标题:{},\n商品图片:{},\n商品产地:{},商品价格:{},付款人数:{},\n'.format(good['nick'], good['title'], good['pic_url'], good['item_loc'], good['view_price'],good['view_sales']))
data_count += 1 print(data_count)
python爬虫-淘宝商品密码(图文教程附源码)的更多相关文章
- 淘宝数据库OceanBase SQL编译器部分 源码阅读--生成物理查询计划
淘宝数据库OceanBase SQL编译器部分 源码阅读--生成物理查询计划 SQL编译解析三部曲分为:构建语法树,制定逻辑计划,生成物理执行计划.前两个步骤请参见我的博客<<淘宝数据库O ...
- 淘宝数据库OceanBase SQL编译器部分 源码阅读--生成逻辑计划
body, td { font-family: tahoma; font-size: 10pt; } 淘宝数据库OceanBase SQL编译器部分 源码阅读--生成逻辑计划 SQL编译解析三部曲分为 ...
- 《淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树》
淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树 曾经的学渣 2014-06-05 18:38:00 浏览1455 云数据库Oceanbase OceanBase是 ...
- PHP简单的长文章分页教程 附源码
PHP简单的长文章分页教程 附源码.本文将content.txt里的内容分割成3页,这样浏览起来用户体验很好. 根据分页参数ipage,获取对应文章内容 include('page.class.php ...
- python 获取淘宝商品信息
python cookie 获取淘宝商品信息 # //get_goods_from_taobao import requests import re import xlsxwriter cok='' ...
- Python爬虫--淘宝“泸州老窖”
爬虫淘宝--"泸州老窖" 爬去淘宝"泸州老窖" 相关信息: import requests import re import json import panda ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 安卓sdk webview获取淘宝个人信息100项,源码。
1.贴出主要代码.这个不是python,python只涉及了服务端对信息提取结果的接受.主体是java + android + js.由于淘宝各模块都是二级子域名,不能只在一个页面完成所有请求,aj ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
随机推荐
- CentOS7.4安装部署KVM虚拟机
命令:virt-manager 可以查看已经安装的虚拟机 参考文档:1.https://blog.csdn.net/qq_39452428/article/details/80781403
- CVE-2019-0797漏洞:Windows操作系统中的新零日在攻击中被利用
https://securelist.com/cve-2019-0797-zero-day-vulnerability/89885/ 前言 在2019年2月,卡巴实验室的自动漏洞防护(AEP)系统检测 ...
- Segmentation metrics
(1)FCN中引入的四种Metrics:
- mlock实现原理及应用【转】
转自:https://blog.csdn.net/yiyeguzhou100/article/details/78085857 https://wenku.baidu.com/view/e25b4af ...
- aiohttp的笔记之TCPConnector
TCPConnector维持链接池,限制并行连接的总量,当池满了,有请求退出再加入新请求.默认是100,limit=0的时候是无限制 1.use_dns_cache: 使用内部DNS映射缓存用以查询D ...
- for..of和for..in和map、filter等循环区别
1.for in遍历的是数组的索引(即键名),而for of遍历的是数组元素值. for in遍历比较适合遍历对象,不太适合数组,有可能遍历出来的不按照顺序 遍历数组 ,,,,,] for (var ...
- zabbix3监控php-fpm的状态
php-fpm和nginx一样内建了一个状态页,对于想了解php-fpm的状态以及监控php-fpm非常有帮助 . 启用php-fpm状态功能 [root@node1:~]# vim /usr/loc ...
- docker里面运行jenkins详解
需求:将jenkins运行在docker中 思路:1.安装docker,并启动docker 服务 2.下载jenkins的docker镜像,然后运行. 前提知识:1.dockde ...
- Golang -- range小坑铭记
废话少叙,先上一段代码,猜猜预期的效果. package main import ( "fmt" ) type student struct { Name string Age i ...
- event & signals & threads
The Event Systemhttp://doc.qt.io/qt-4.8/eventsandfilters.html Each thread can have its own event loo ...