Kafka技术内幕 读书笔记之(三) 生产者——消费者:高级API和低级API——基础知识
1. 使用消费组实现消息队列的两种模式
分布式的消息系统Kafka支持多个生产者和多个消费者,生产者可以将消息发布到集群中不同节点的不同分区上;消费者也可以消费集群中多个节点的多个分区上的消息 。
写消息时,多个生产者可以写到同一个分区 。
读消息时,如果多个消费者同时读取一个分区,为了保证将日志文件的不同数据分配给不同的消费者,需要采用加锁 、 同步等方式,在分区级别的日志文件上做些控制 。
如果约定“同一个分区只可被一个消费者处理”,就不需要加锁同步了,从而可提升消费者的处理能力 。
下图给出了一种最简单的消息系统部署模式,生产者的数据源多种多样,它们都统一写人Kafka集群 。 处理消息时有多个消费者分担任务 ,
这些消费者的处理逻辑都相同, 每个消费者处理的分区都不会重复。
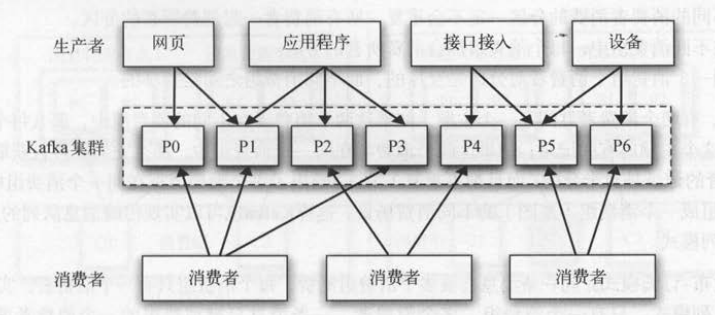
Kafka使用消费组的概念,允许一组消费者进程对消费工作进行划分。 每个消费者都可以配置一个所属的消费组,并且订阅多个主题。
Kafka会发送每条消息给每个消费组中的一个消费者进程( 同一条消息广播给多个消费组,单播给同一组中的消费者)。 被订阅主题的所有分区会平均地负载给订
阅方,即消费组中的所有消费者 。 比如 1个主题有4个分区, 1个消费组有2个消费者,那么每个消费者都会分配到2个分区 。
如下图所示,典型的Kafka集群部署方式会有多个消费组,并且每个消费组中也有多个消费者。这样既允许多种业务逻辑的消费组存在,也可以保证同一个消费组内
的多个消费者协调工作,避免因一个消费组中只有一个消费者导致数据丢失 。
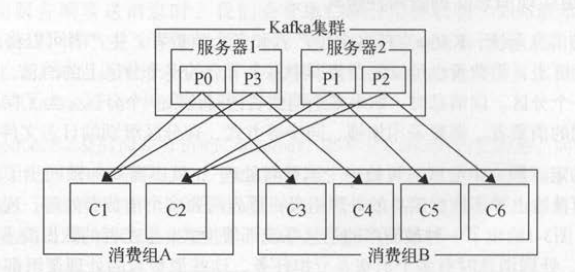
Kafka采用消费组保证了“一个分区只可被消费组中的一个消费者所消费” ,这意味着 :
(1)在一个消费组中,一个消费者可以消费多个分区 。
(2)不同的消费者消费的分区一定不会重复,所有消费者一起消费所有的分区 。
(3)在不同消费组中,每个消费组都会消费所有的分区 。
(4)同一个消费组下消费者对分区是互斥的,而不同消费组之间是共享的 。
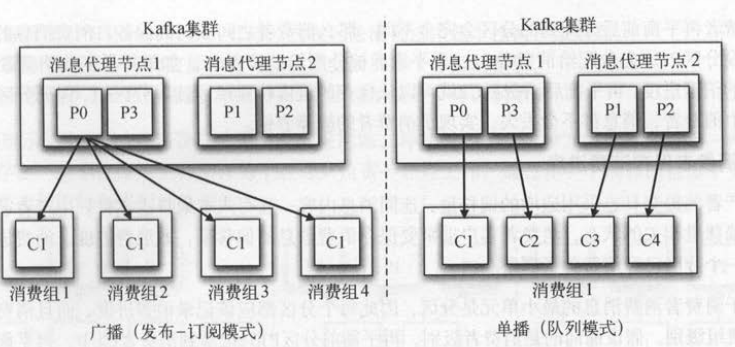
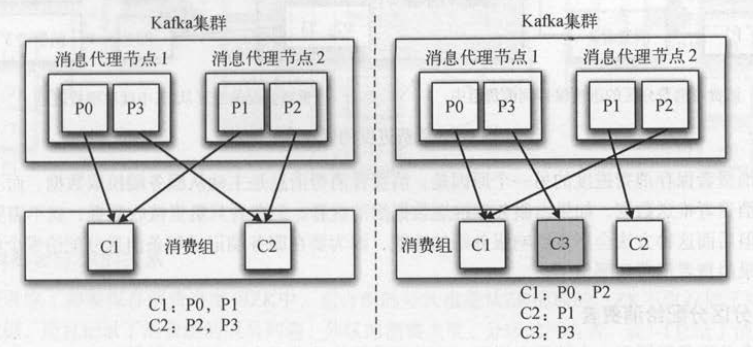
比如,有两个消费者订阅了一个主题 , 如果这两个消费者在不同的消费组中,那么每个消费者都会获取到这个主题所有的记录 ,如果这两个消费者在
同一个消费组中,那么它们会各自获取到一半的记录(两者的记录是对半分的,而且都不重复)。下图给出了多个消费者都在同一个消费组中(有图),
或者各自组成一个消费组(左图)的不同消费场景,这样Kafka也可以实现传统消息队列的发布一订阅模式和队列模式 。
发布-订阅模式。同一条消息会被多个消费组消费,每个消费组只有一个消费者,实现广播。
队列模式。只有一个消费组、多个消费者 一条消息只被消费组的一个消费者消费 ,实现单播 。
2. 消费组再平衡实现故障容错
消费者是客户端的业务处理逻辑程序,因此要考虑消费者的故障容错。一个消费组有多个消费者,因此消费组需要维护所有的消费者 。
如果一个消费者宕机了,分配给这个消费者的分区需要重新分配给相同组的其他消费者;
如果一个消费者加入了同一个组,之前分配给其他消费组的分区需要分配给新加入的消费者。
一旦有消费者加入或退出消费组,导致消费组成员列表发生变化 ,消费组中所有的消费者就要执行再平衡( rebalance ) 工作 。
如果订阅主题的分区有变化,所有的消费者也都要再平衡。 如下图 所示 ,
在加入一个新的消费者后,需要为所有的消费者重新分配分区 , 因此所有消费者都会执行再平衡。
消费者再平衡前后分配到的分区会完全不同,那么消费者之间如何确保各向消费消息的平滑过渡呢?
假设分区P1原先分配给消费者C1,再平衡后被分配给消费者C2 。 如果再平衡前消费者C1保存了分区P1 的消费进度,再平衡后消费者C2就可以从保存的
进度位置继续读取分区进度,保证分区P1不管分配给哪个消费者,消息都不会丢失,实现了消费者的故障容错。
3 . 消费者保存消费进度
生产者的提交日志采用递增的偏移量,连同消息内容一起写入本地日志文件。 消费者客户端则要保存消费消息的偏移盘 即消费进度 。 消费进度表示消
费者对一个分区已经消费到了哪里 。
由于消费者消费消息的最小单元是分区,因此每个分区都应该记录消费进度,而且消费进度应该面向消费组级别 。假设面向的是消费者级别,
虽然分区是以消费者级别被消费的,但分区的消费进度要保存成消费组级别的 。消费者对分区的消费进度通常保存在外部存储系统中,
比如 ZK或者 Kafka 的内部主题( _consume_offsets )。 这样分区的不同拥有者总是可以读取同一个存储系统的消费进度,即使消费
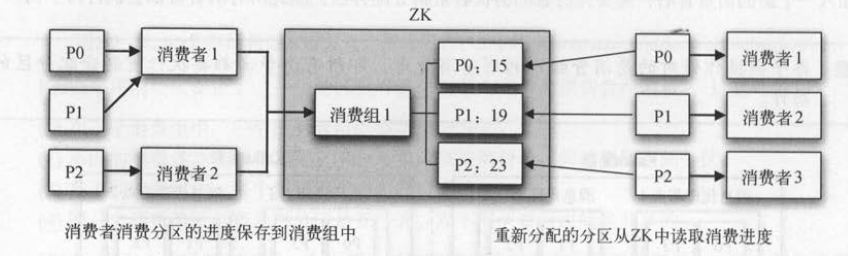
者成员发生变化,也不会影响消息的消费和处理。 如下图所示,消费者消费消息时,需要定时将分区的最新消费进度保存到ZK中 。
当发生再平衡时,消费者拥有的新分区消费进度都可以从ZK中读取出来,从而恢复到最近的消费状态。
4 . 分区分配给消费者
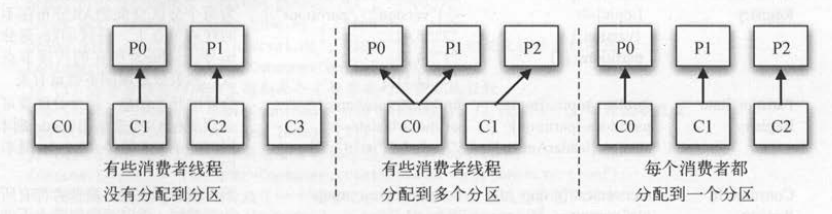
一个分区只能属于一个消费者线程,将分区分配给消费者有以下几种场景。
线程数量多于分区的数量,有部分线程无法消费该主题下任何一条消息 。
线程数量少于分区的数量,有一些线程会消费多个分区的数据 。
线程数量等于分区的数量,则正好一个钱程消费一个分区的数据 。
下图展示了上面这3种场景,正常情况下采用第二种是最好的,这种方案既不会有第一种的资源浪费现象存在,也不会像第三种那样
每个线程只负责一点点工作 。 通过让一个线程消费多个分区,可以最大限度地利用每个线程的处理能力 。
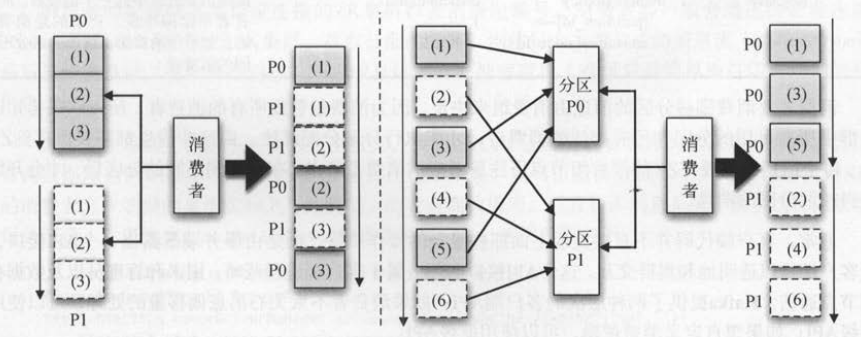
一个消费者线程消费多个分区,可以保证消费同一个分区的消息一定是有序的,但并不保证消费者接收到多个分区的消息完全有序 。
如下图所示,消费者分配了分区P0和分区P1 ,虽然消费者收到的消息整体上不是有序的,但是针对同一个分区的消息是有序的 。
比如下图(左)中分区内的消息
顺序()(2)(3)对应的消费者读取顺序也一定是( 1 )(2)(坷,图 3-7 (右)中分区PO的消息顺序( 1)(3)(5)对应
的消费者读取顺序也一定是( 1)(3)(5) 。
5 . 消费者与 ZK的关系
消费者除了需要保存消费进度到ZK中,它分配的分区也是从ZK读取的 。 ZK不仅存储了 Kafka的
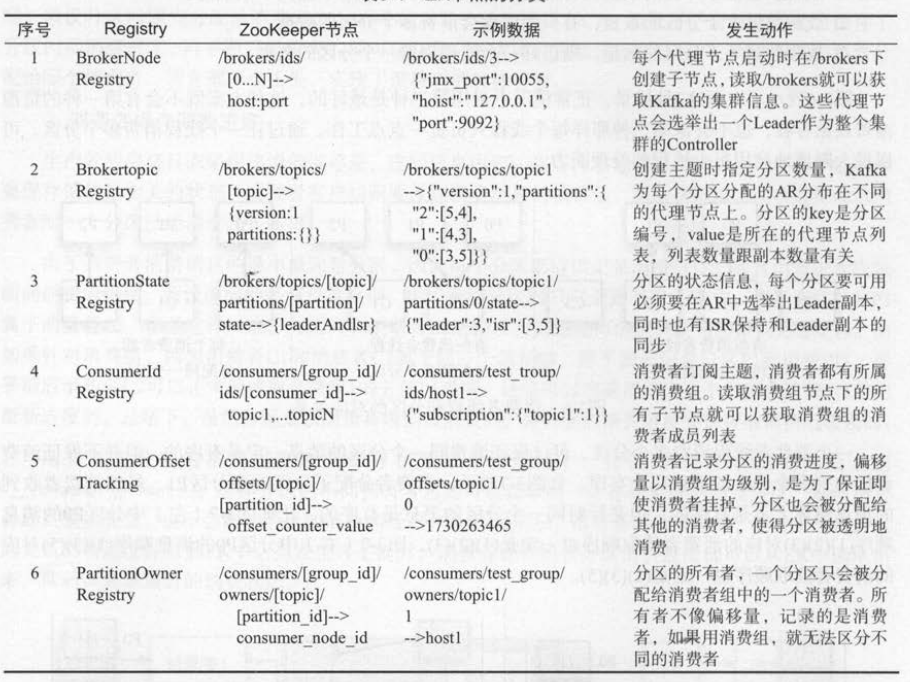
内部元数据,而且记录了消费组的成员列表、分区的消费进度、分区的所有者 。 表3 -1总结了消息代理
节点、主题 、 分区 、 消费者、偏移量( offset )、所有权( ownership )在ZK中的注册信息 。
消费者要消费哪些分区的消息由消费组来决定,因为消费组管理所有的消费者,所以它需要知道集群中所有可用的分区和所有存活的消费者,
才能执行分区分配算法,而这些信息都需要保存到ZK中 。 每个消费者都要在ZK的消费组节点下注册对应的消费者节点,在分配到不同的分区后,
才会开始各自拉取分区的消息 。
通常,客户端代码并不直接完成上面那些复杂的操作步骤,而是由服务端暴露出一个API接口,让客户端可以透明地和集群交互。 这个API接口实际
上属于客户端进程范畴,用来和管理员以及数据存储节点通信。 Kafka提供了两种层次的客户端API : 如果消费者不太关心消息偏移量的处理,可以使用
高级API ;如果想自定义消费逻辑,可以使用低级API。
高级API :消费者客户端代码不需要管理偏移量的提交,并且采用了消费组的自动负载均衡功能,确保消费者的增减不会影响消息的消费 。
高级API提供了从Kafka消费数据的高层抽象 。
低级API :通常针对特殊的消费逻辑,比如消费者只想消费某些特定的分区 。 低级API的客户端代码需要自己实现一些和Kafka服务端相关的底层逻辑,
比如选择分区的主副本 、 处理主副本的故障转移等。
Kafka技术内幕 读书笔记之(三) 生产者——消费者:高级API和低级API——基础知识的更多相关文章
- Kafka技术内幕 读书笔记之(六) 存储层——日志的读写
-Kafka是一个分布式的( distributed ).分区的( partitioned ).复制的( replicated )提交日志( commitlog )服务 . “分布式”是所有分布式系统 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——新消费者客户端(二)
消费者拉取消息 消费者创建拉取请求的准备工作,和生产者创建生产请求的准备工作类似,它们都必须和分区的主副本交互.一个生产者写入的分区和消费者分配的分区都可能有多个,同时多个分区的主副本有可能在同一个节 ...
- Kafka技术内幕 读书笔记之(五) 协调者——消费组状态机
协调者保存的消费组元数据中记录了消费组的状态机 , 消费组状态机的转换主要发生在“加入组请求”和“同步组请求”的处理过程中 .协调者处理“离开消费组请求”“迁移消费组请求”“心跳请求” “提交偏移量请 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——消费者提交偏移量
消费组发生再平衡时分区会被分配给新的消费者,为了保证新消费者能够从分区的上一次消费位置继续拉取并处理消息,每个消费者需要将分区的消费进度,定时地同步给消费组对应的协调者节点 .新AP I为客户端提供了 ...
- Kafka技术内幕 读书笔记之(二) 生产者——新生产者客户端
消息系统通常由生产者(producer ). 消费者( consumer )和消息代理( broker ) 三大部分组成,生产者会将消息写入消息代理,消费者会从消息代理中读取消息 . 对于消息代理而言 ...
- Kafka技术内幕 读书笔记之(三) 消费者:高级API和低级API——消费者消费消息和提交分区偏移量
消费者拉取钱程拉取每个分区的数据,会将分区的消息集包装成一个数据块( FetchedDataChunk )放入分区信息的队列中 . 而每个队列都对应一个消息流( KafkaStream ),消费者客户 ...
- Kafka技术内幕 读书笔记之(二) 生产者——服务端网络连接
KafkaServer是Kafka服务端的主类, KafkaServer中和网络层有关的服务组件包括 SocketServer.KafkaApis 和 KafkaRequestHandlerPool后 ...
- Kafka技术内幕 读书笔记之(一) Kafka入门
在0.10版本之前, Kafka仅仅作为一个消息系统,主要用来解决应用解耦. 异步消息 . 流量削峰等问题. 在0.10版本之后, Kafka提供了连接器与流处理的能力,它也从分布式的消息系统逐渐成为 ...
- Kafka技术内幕 读书笔记之(六) 存储层——服务端处理读写请求、分区与副本
如下图中分区到 日 志的虚线表示 : 业务逻辑层的一个分区对应物理存储层的一个日志 . 消息集到数据文件的虚线表示 : 客户端发送的消息集最终会写入日志分段对应的数据文件,存储到Kafka的消息代理节 ...
随机推荐
- yarn如何全局安装命令以及和环境变量的关系
npm全局安装 npm i -g xxx yarn 全局安装 yarn global add xxx 然而你可能会发现npm全局安装后的命令可以直接使用,而yarn却不行,这是为什么呢? 我们来查看下 ...
- Hdoj 1007 Quoit Design 题解
Problem Description Have you ever played quoit in a playground? Quoit is a game in which flat rings ...
- 【arc073e】Ball Coloring(线段树,贪心)
[arc073e]Ball Coloring(线段树,贪心) 题面 AtCoder 洛谷 题解 大型翻车现场,菊队完美压中男神的模拟题 首先钦定全局最小值为红色,剩下的袋子按照其中较大值排序. 枚举前 ...
- 【WC2018】通道(边分治,虚树,动态规划)
[WC2018]通道(边分治,虚树,动态规划) 题面 UOJ 洛谷 题解 既然是三棵树,那么显然就是找点什么东西来套个三层. 一棵树怎么做?入门dp. 两棵树?假设在第一棵树中的深度为\(dep\). ...
- [ZJOI2019]游记之我的第一次省选--自闭记
2019/3/23 day -1 今天是体育中考....(祝我好运) 实心球再次投出测量范围,虽然成绩是10.5,但是目测有15米. 立定跳远2.70,好近,我爸叫我跳2.8的QwQ. 1000米最后 ...
- [CF1132E]Knapsack【暴力搜索】
你有一个容量为\(w\)的背包,和\(8\)件物品,重量分别为\(1~8\)的整数,分别有\(cnt_1 ... cnt_8\),求最大容量. 解法 笨蛋chh一开始打了一个背包模板乱搞压缩容量\(j ...
- mac上安装memcache
1. 安装 brew (http://brew.sh/) /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/H ...
- Java,mysql String与date类型转换
String 与 date类型转换 字符串转换成日期类型: SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd");//小写 ...
- java 子类强转父类 父类强转子类
Java 继承 继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为. Java 子类强转父类 父类引用指向子类对象: jav ...
- JS时间戳转换成时间格式
TimeNow: function (val) { var date = new Date(val); var Y = date.getFullYear(); var m = date.getMont ...