PG数据库基本命令——查询(笔记)
1、插入数据(insert 语句)
语法:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN)
VALUES (value1, value2, value3,...valueN);
实例:
INSERT INTO employees( ID, NAME, AGE, ADDRESS, SALARY)
VALUES
(1, 'Maxsu', 25, '海口市人民大道2880号', 109990.00 ),
(2, 'minsu', 25, '广州中山大道 ', 125000.00 ),
(3, '李洋', 21, '北京市朝阳区', 185000.00),
(4, 'Manisha', 24, 'Mumbai', 65000.00),
(5, 'Larry', 21, 'Paris', 85000.00);
2、查询数据(SELECT语句)
语法:
SELECT "column1", "column2"..."columnN" FROM "table_name";
SELECT * FROM "table_name";
3、更新数据(UPDATE语句)
语法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
4、删除数据(DELETE语句)
语法:
DELETE FROM table_name
WHERE [condition];
实例:
DELETE FROM EMPLOYEES
WHERE ID = 1;
5、ORDER BY子句
语法:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
实例:
SELECT *
FROM EMPLOYEES
ORDER BY AGE ASC;
6、分组(GROUP BY子句)
语法:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
实例:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
在上面的例子中,当我们使用GROUP BY NAME时,重复的名字数据记录被合并。 它指定GROUP BY减少冗余。
7、Having子句
语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
实例:
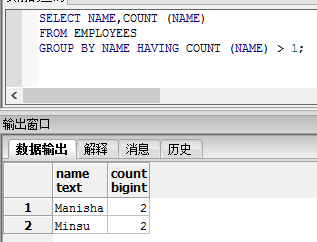
执行以下查询表“EMPLOYEES”中name字段值计数大于1的名称。
SELECT NAME,COUNT (NAME)
FROM EMPLOYEES
GROUP BY NAME HAVING COUNT (NAME) > 1;
8、条件查询
条件查询有:
- AND 条件
- OR 条件
- AND & OR 条件
- NOT 条件
- LIKE 条件
- IN 条件
- NOT IN 条件
- BETWEEN 条件
1)AND条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
AND [search_condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE SALARY > 120000
AND ID <= 4;
2) OR条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
OR [search_condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE NAME = 'Minsu'
OR ADDRESS = 'Noida';
3)AND & OR条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] AND [search_condition]
OR [search_condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE (NAME = 'Minsu' AND ADDRESS = 'Delhi')
OR (ID>= 8);
4)NOT条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] NOT [condition];
实例:
查询那些地址不为 NULL 的记录信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE address IS NOT NULL ;
查询那些年龄不是21和24的所有记录,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE age NOT IN(21,24) ;
5)LIKE条件
like 与 where 子句一起,用于从指定条件满足 like 条件的表中获取数据。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] LIKE [condition];
实例:
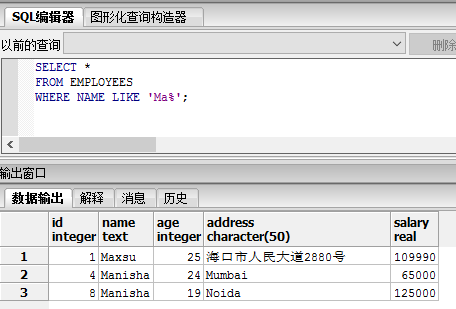
查询名字以 Ma 开头的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE NAME LIKE 'Ma%';
执行结果如下图:
查询名字以su结尾的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE NAME LIKE '%su';
6)IN条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] IN [condition];
实例:
查询employee表中那些年龄为19,21的员工信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE AGE IN (19, 21);
7)NOT IN条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] NOT IN [condition];
8)BETWEEN条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] BETWEEN [condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE AGE BETWEEN 24 AND 27;
PG数据库基本命令——查询(笔记)的更多相关文章
- 【MySQL笔记】数据库的查询
数据库的查询 注:文中 [ ...] 代表该部分可以去掉. 理论基础:对表对象的一组关系运算,即选择(selection).投影(projection)和连接(join) 1.select语句 子语句 ...
- JPA连接PG数据库时间类型查询报错的修改
PG数据库中的时间格式规范: https://blog.csdn.net/sky_limitless/article/details/79527665 to_data 转换为 普通的时间格式 to_t ...
- mySQl数据库的学习笔记
mySQl数据库的学习笔记... ------------------ Dos命令--先在记事本中写.然后再粘贴到Dos中去 -------------------------------- mySQ ...
- Mysql数据库基础学习笔记
Mysql数据库基础学习笔记 1.mysql查看当前登录的账户名以及数据库 一.单表查询 1.创建数据库yuzly,创建表fruits 创建表 ) ) ,) NOT NULL,PRIMARY KEY( ...
- 数据库MySQL学习笔记高级篇
数据库MySQL学习笔记高级篇 写在前面 学习链接:数据库 MySQL 视频教程全集 1. mysql的架构介绍 mysql简介 概述 高级Mysql 完整的mysql优化需要很深的功底,大公司甚至有 ...
- 通过redash query results 数据源实现跨数据库的查询
redash 提供了一个简单的 query results 可以帮助我们进行跨数据源的查询处理 底层数据的存储是基于sqlite的,期望后期有调整(毕竟处理能力有限),同时 query results ...
- MySQL数据操作与查询笔记 • 【目录】
持续更新中- 我的大学笔记>>> 章节 内容 第1章 MySQL数据操作与查询笔记 • [第1章 MySQL数据库基础] 第2章 MySQL数据操作与查询笔记 • [第2章 表结构管 ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- Neo4j图数据库管理系统开发笔记之一:Neo4j Java 工具包
1 应用开发概述 基于数据传输效率以及接口自定义等特殊性需求,我们暂时放弃使用Neo4j服务器版本,而是在Neo4j嵌入式版本的基础上进行一些封装性的开发.封装的重点,是解决Neo4j嵌入式版本Emb ...
随机推荐
- SpringSecurity身份验证基础入门
对于没有访问权限的用户需要转到登录表单页面.要实现访问控制的方法多种多样,可以通过Aop.拦截器实现,也可以通过框架实现(如:Apache Shiro.Spring Security). pom.xm ...
- 2019OO第一单元作业总结
OO第一单元作业的主题是求导,下面将分三次作业分别总结一下. --------------------------------------------------------------------- ...
- Eclipse上传新项目到GitLab
E&T: Eclipse; GitLab; GitLab和GitHub一样属于第三方基于Git开发的作品,免费且开源(https://github.com/gitlabhq/gitlabhq ...
- 关于笔记本安装parrot和kali的一些问题(花屏,息屏,屏幕不能休眠)
新入手了个笔记本,还是想跟原来一样装回熟悉的kali环境中,结果我的天啊,这一路坑,简直了. 写下我遇到的问题吧,算是给大家提供一些解决方法. 1.安装kali和parrot出现无法引导的grub的情 ...
- sequelize 学习笔记
使用 eggjs 和 sequelize 进行开发,一些要注意的地方 1.egg 的 egg-sequelize 插件是 sequelize 的V4版本,目前已经更新到V5版本,API有一些变化,比如 ...
- XSS学习(二)
尝试操作Cookie 创建一个cookie,需要提供cookie的名字,值,过期时间和相关路径等 <?php setcookie('user_id',123); ?> 它的作用是创建一个c ...
- ionic页面间跳转的动画实现
1. 在<ion-view>标签中加入: nav-direction="back"或nav-direction="forward" 2.用$stat ...
- Go 字符串连接+=与strings.Join性能对比
Go字符串连接 对于字符串的连接大致有两种方式: 1.通过+号连接 func StrPlus1(a []string) string { var s, sep string for i := 0; i ...
- jquery案例
调用js成员 <!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head>& ...
- JS实现购物商城商品放大
img属于行内元素 <img src=''>gq</img> 效果 当放大图片时候,文字位置发生改变 文字出现在图片下方,因为图片有一个隐形的g线,这条线的位置和以前上学时候, ...