表优化 altering table OPTIMIZE TABLE `sta_addr_copy`
表优化 altering table OPTIMIZE TABLE `sta_addr_copy`
【总结】
1、实际测试的结果是,
在
state sql
altering table OPTIMIZE TABLE `test`
insert成功;
13.7.3.4 OPTIMIZE TABLE Syntax
OPTIMIZE [NO_WRITE_TO_BINLOG | LOCAL]
TABLE tbl_name [, tbl_name] ...OPTIMIZE TABLE reorganizes the physical storage of table data and associated index data, to reduce storage space and improve I/O efficiency when accessing the table. The exact changes made to each table depend on the storage engine used by that table.
Use OPTIMIZE TABLE in these cases, depending on the type of table:
After doing substantial insert, update, or delete operations on an
InnoDBtable that has its own .ibd file because it was created with theinnodb_file_per_tableoption enabled. The table and indexes are reorganized, and disk space can be reclaimed for use by the operating system.After doing substantial insert, update, or delete operations on columns that are part of a
FULLTEXTindex in anInnoDBtable. Set the configuration optioninnodb_optimize_fulltext_only=1first. To keep the index maintenance period to a reasonable time, set theinnodb_ft_num_word_optimizeoption to specify how many words to update in the search index, and run a sequence ofOPTIMIZE TABLEstatements until the search index is fully updated.After deleting a large part of a
MyISAMorARCHIVEtable, or making many changes to aMyISAMorARCHIVEtable with variable-length rows (tables that haveVARCHAR,VARBINARY,BLOB, orTEXTcolumns). Deleted rows are maintained in a linked list and subsequentINSERToperations reuse old row positions. You can useOPTIMIZE TABLEto reclaim the unused space and to defragment the data file. After extensive changes to a table, this statement may also improve performance of statements that use the table, sometimes significantly.
This statement requires SELECT and INSERT privileges for the table.
OPTIMIZE TABLE works for InnoDB, MyISAM, and ARCHIVE tables. OPTIMIZE TABLE is also supported for dynamic columns of in-memory NDB tables. It does not work for fixed-width columns of in-memory tables, nor does it work for Disk Data tables. The performance of OPTIMIZE on NDB Cluster tables can be tuned using --ndb_optimization_delay, which controls the length of time to wait between processing batches of rows by OPTIMIZE TABLE. For more information, see Previous NDB Cluster Issues Resolved in NDB Cluster 7.3.
For NDB Cluster tables, OPTIMIZE TABLE can be interrupted by (for example) killing the SQL thread performing the OPTIMIZE operation.
By default, OPTIMIZE TABLE does not work for tables created using any other storage engine and returns a result indicating this lack of support. You can make OPTIMIZE TABLE work for other storage engines by starting mysqld with the --skip-new option. In this case, OPTIMIZE TABLE is just mapped to ALTER TABLE.
This statement does not work with views.
OPTIMIZE TABLE is supported for partitioned tables. For information about using this statement with partitioned tables and table partitions, see Section 23.3.4, “Maintenance of Partitions”.
By default, the server writes OPTIMIZE TABLE statements to the binary log so that they replicate to replication slaves. To suppress logging, specify the optional NO_WRITE_TO_BINLOG keyword or its alias LOCAL.
OPTIMIZE TABLE Output
OPTIMIZE TABLE returns a result set with the columns shown in the following table.
| Column | Value |
|---|---|
Table |
The table name |
Op |
Always optimize |
Msg_type |
status, error, info, note, or warning |
Msg_text |
An informational message |
OPTIMIZE TABLE table catches and throws any errors that occur while copying table statistics from the old file to the newly created file. For example. if the user ID of the owner of the .MYD or .MYI file is different from the user ID of the mysqld process, OPTIMIZE TABLE generates a "cannot change ownership of the file" error unlessmysqld is started by the root user.
InnoDB Details
For InnoDB tables, OPTIMIZE TABLE is mapped to ALTER TABLE ... FORCE, which rebuilds the table to update index statistics and free unused space in the clustered index. This is displayed in the output of OPTIMIZE TABLE when you run it on an InnoDB table, as shown here:
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+-------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | status | OK |
+----------+----------+----------+-------------------------------------------------------------------+OPTIMIZE TABLE uses online DDL for regular and partitioned InnoDB tables, which reduces downtime for concurrent DML operations. The table rebuild triggered by OPTIMIZE TABLE and performed under the cover by ALTER TABLE ... FORCE is completed in place. An exclusive table lock is only taken briefly during the prepare phase and the commit phase of the operation. During the prepare phase, metadata is updated and an intermediate table is created. During the commit phase, table metadata changes are committed.
OPTIMIZE TABLE rebuilds the table using the table copy method under the following conditions:
When the
old_alter_tablesystem variable is enabled.When the mysqld
--skip-newoption is enabled.
OPTIMIZE TABLE using online DDL is not supported for InnoDB tables that contain FULLTEXT indexes. The table copy method is used instead.
InnoDB stores data using a page-allocation method and does not suffer from fragmentation in the same way that legacy storage engines (such as MyISAM) will. When considering whether or not to run optimize, consider the workload of transactions that your server will process:
Some level of fragmentation is expected.
InnoDBonly fills pages 93% full, to leave room for updates without having to split pages.Delete operations might leave gaps that leave pages less filled than desired, which could make it worthwhile to optimize the table.
Updates to rows usually rewrite the data within the same page, depending on the data type and row format, when sufficient space is available. See Section 15.9.1.5, “How Compression Works for InnoDB Tables” and Section 15.10, “InnoDB Row Formats”.
High-concurrency workloads might leave gaps in indexes over time, as
InnoDBretains multiple versions of the same data due through its MVCC mechanism. SeeSection 15.3, “InnoDB Multi-Versioning”.
MyISAM Details
For MyISAM tables, OPTIMIZE TABLE works as follows:
If the table has deleted or split rows, repair the table.
If the index pages are not sorted, sort them.
If the table's statistics are not up to date (and the repair could not be accomplished by sorting the index), update them.
Other Considerations
OPTIMIZE TABLE is performed online for regular and partitioned InnoDB tables. Otherwise, MySQL locks the table during the time OPTIMIZE TABLE is running.
OPTIMIZE TABLE does not sort R-tree indexes, such as spatial indexes on POINT columns. (Bug #23578)
来看看手册中关于 OPTIMIZE 的描述:
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... 如果您已经删除了表的一大部分,或者如果您已经对含有可变长度行的表(含有VARCHAR, BLOB或TEXT列的表)进行了很多更改,则应使用
OPTIMIZE TABLE。被删除的记录被保持在链接清单中,后续的INSERT操作会重新使用旧的记录位置。您可以使用OPTIMIZE TABLE来重新
利用未使用的空间,并整理数据文件的碎片。 在多数的设置中,您根本不需要运行OPTIMIZE TABLE。即使您对可变长度的行进行了大量的更新,您也不需要经常运行,每周一次或每月一次
即可,只对特定的表运行。 OPTIMIZE TABLE只对MyISAM, BDB和InnoDB表起作用。 注意,在OPTIMIZE TABLE运行过程中,MySQL会锁定表。【注释:不正确】
原始数据
1,数据量
mysql> select count(*) as total from ad_visit_history;
+---------+
| total |
+---------+
| 1187096 | //总共有118万多条数据
+---------+
1 row in set (0.04 sec)
2,存放在硬盘中的表文件大小
[root@ www.linuxidc.com test1]# ls |grep visit |xargs -i du {}
382020 ad_visit_history.MYD //数据文件占了380M
127116 ad_visit_history.MYI //索引文件占了127M
12 ad_visit_history.frm //结构文件占了12K
3,查看一下索引信息
mysql> show index from ad_visit_history from test1; //查看一下该表的索引信息
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
| ad_visit_history | 0 | PRIMARY | 1 | id | A | 1187096 | NULL | NULL | | BTREE | |
| ad_visit_history | 1 | ad_code | 1 | ad_code | A | 46 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | unique_id | 1 | unique_id | A | 1187096 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | ad_code_ind | 1 | ad_code | A | 46 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | from_page_url_ind | 1 | from_page_url | A | 30438 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | ip_ind | 1 | ip | A | 593548 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | port_ind | 1 | port | A | 65949 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | session_id_ind | 1 | session_id | A | 1187096 | NULL | NULL | YES | BTREE | |
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
8 rows in set (0.28 sec)
索引信息中的列的信息说明。
Table :表的名称。
Non_unique:如果索引不能包括重复词,则为0。如果可以,则为1。
Key_name:索引的名称。
Seq_in_index:索引中的列序列号,从1开始。
Column_name:列名称。
Collation:列以什么方式存储在索引中。在MySQLSHOW INDEX语法中,有值’A’(升序)或NULL(无分类)。
Cardinality:索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
Packed:指示关键字如何被压缩。如果没有被压缩,则为NULL。
Null:如果列含有NULL,则含有YES。如果没有,则为空。
Index_type:存储索引数据结构方法(BTREE, FULLTEXT, HASH, RTREE)
二,删除一半数据
mysql> delete from ad_visit_history where id>598000; //删除一半数据
Query OK, 589096 rows affected (4 min 28.06 sec)
[root@ www.linuxidc.com test1]# ls |grep visit |xargs -i du {} //相对应的MYD,MYI文件大小没有变化
382020 ad_visit_history.MYD
127116 ad_visit_history.MYI
12 ad_visit_history.frm
按常规思想来说,如果在数据库中删除了一半数据后,相对应的.MYD,.MYI文件也应当变为之前的一半。但是删除一半数据后,.MYD.MYI尽然连1KB都没有减少,这是多么的可怕啊。
我们在来看一看,索引信息
mysql> show index from ad_visit_history;
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
| ad_visit_history | 0 | PRIMARY | 1 | id | A | 598000 | NULL | NULL | | BTREE | |
| ad_visit_history | 1 | ad_code | 1 | ad_code | A | 23 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | unique_id | 1 | unique_id | A | 598000 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | ad_code_ind | 1 | ad_code | A | 23 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | from_page_url_ind | 1 | from_page_url | A | 15333 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | ip_ind | 1 | ip | A | 299000 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | port_ind | 1 | port | A | 33222 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | session_id_ind | 1 | session_id | A | 598000 | NULL | NULL | YES | BTREE | |
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
8 rows in set (0.00 sec)
对比一下,这次索引查询和上次索引查询,里面的数据信息基本上是上次一次的一本,这点还是合乎常理。
三,用optimize table来优化一下
??mysql> optimize table ad_visit_history; //删除数据后的优化
+------------------------+----------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------------------+----------+----------+----------+
| test1.ad_visit_history | optimize | status | OK |
+------------------------+----------+----------+----------+
1 row in set (1 min 21.05 sec)
1,查看一下.MYD,.MYI文件的大小
??[root@ www.linuxidc.com test1]# ls |grep visit |xargs -i du {}
182080 ad_visit_history.MYD //数据文件差不多为优化前的一半
66024 ad_visit_history.MYI //索引文件也一样,差不多是优化前的一半
12 ad_visit_history.frm
2,查看一下索引信息
??mysql> show index from ad_visit_history;
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
| ad_visit_history | 0 | PRIMARY | 1 | id | A | 598000 | NULL | NULL | | BTREE | |
| ad_visit_history | 1 | ad_code | 1 | ad_code | A | 42 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | unique_id | 1 | unique_id | A | 598000 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | ad_code_ind | 1 | ad_code | A | 42 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | from_page_url_ind | 1 | from_page_url | A | 24916 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | ip_ind | 1 | ip | A | 598000 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | port_ind | 1 | port | A | 59800 | NULL | NULL | YES | BTREE | |
| ad_visit_history | 1 | session_id_ind | 1 | session_id | A | 598000 | NULL | NULL | YES | BTREE | |
+------------------+------------+-------------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+
8 rows in set (0.00 sec)
从以上数据我们可以得出,ad_code,ad_code_ind,from_page_url_ind等索引机会差不多都提高了85%,这样效率提高了好多。
四,小结
结合mysql官方网站的信息,个人是这样理解的。当你删除数据时,mysql并不会回收,被已删除数据的占据的存储空间,以及索引位。而是空在那里,而是等待新的数据来弥补这个空缺,这样就有一个缺少,如果一时半会,没有数据来填补这个空缺,那这样就太浪费资源了。所以对于写比较频烦的表,要定期进行optimize,一个月一次,看实际情况而定了。
前言
当对MySQL进行大量的增删改操作的时候,很容易产生一些碎片,这些碎片占据着空间,所以可能会出现删除很多数据后,数据文件大小变化不大的现象。当然新插入的数据仍然会利用这些碎片。但过多的碎片,对数据的插入操作是有一定影响的,此时,我们可以通过optimize来对表的优化。
为了更加直观的看到数据碎片,Mysql可以使用如下命令查看
show table status [like table_name]
如下图

data_free选项代表数据碎片。
针对MySQL的不同数据库存储引擎,在optimize使用清除碎片,回收闲置的数据库空间,把分散存储(fragmented)的数据和索引重新挪到一起(defragmentation),对I/O速度有好处。
当然optimize在对表进行操作的时候,会加锁,所以不宜经常在程序中调用。
MyISAM存储引擎
针对MyISAM表,直接使用如下命令进行优化
optimize table table1[,table2][,table3]
如果同时优化多个表可以使用逗号分隔。
下面优化dede_member_vhistory表,可以看出,优化后data_free值为0。

#InnoDB存储引擎
InnoDB引擎的表分为独享表空间和同享表空间的表,我们可以通过show variables like ‘innodb_file_per_table’;来查看是否开启独享表空间。
我本地是开启了独享表空间的。此时是无法对表进行optimize操作的,如果操作,会返回如图信息,最后的一条Table does not support optimize, doing recreate + analyze instead。因为该结构下删除了大量的行,此时索引会重组并且会释放相应的空间因此不必优化。 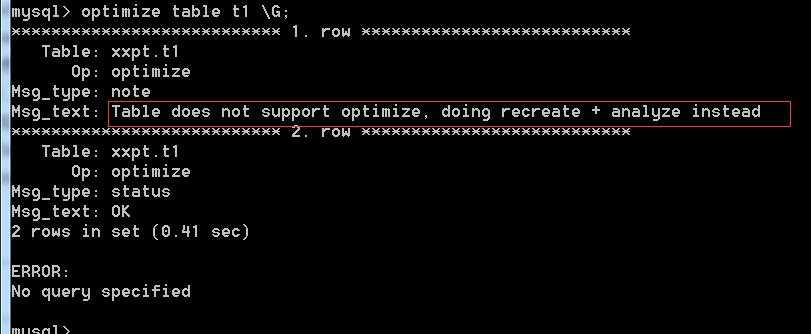
表优化 altering table OPTIMIZE TABLE `sta_addr_copy`的更多相关文章
- MySQL check table/optimize table/analyze table/REPAIR TABLE
MySQL check table/optimize table/analyze table/REPAIR TABLE 转自:https://www.cnblogs.com/datastack/p/3 ...
- OPTIMIZE TABLE linked list 表优化原理 链表数据结构 空间再利用
小结: 1.加快读写: 2.对于InnoDB表,在一定条件下,通过复制旧表重建: 3.实践中, 3.1.show processlist;查看线程,发现,认为堵塞读请求: 3.2.数据长度空间不变,索 ...
- 实例说明optimize table在优化MySQL时很重要
今天在看CU的时候,发现有人问有关optimize来表优化的问题,当年因为这个问题,困扰我很长一段时间,今天有空我把这个问题,用实际数据来展示出来,让大家可以亲眼来看看,optimize table的 ...
- OPTIMIZE TABLE的作用--转载
当您的库中删除了大量的数据后,您可能会发现数据文件尺寸并没有减小.这是因为删 除操作后在数据文件中留下碎片所致.Discuz! 在系统数设置界面提供了数据表优化的功能,可以去除删除操作后留下的数据文件 ...
- optimize table 删除空洞--MYSQL
来看看手册中关于 OPTIMIZE 的描述: OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... 如果您已经删除 ...
- mysql中OPTIMIZE TABLE的作用及使用
来看看手册中关于 OPTIMIZE 的描述: OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... 如果您已经删除 ...
- OPTIMIZE TABLE
INNODB 不支持 mysql> OPTIMIZE TABLE t; +--------+----------+----------+----------------------------- ...
- mysql optimize table
mysql 数据文件的使用是只扩展,不回收.对表执行delete之后,磁盘上数据文件是不会缩小的. 通常的做法,是先逻辑导出,然后truncate 原表(或者删除重建),再导入. 另外还有一种方法是o ...
- mysql数据导入导出与数据表优化
一.数据导入 mysqlimport -uroot oa d:/aa.txt --fields-terminated-by=, --fields-optionally-enclosed-by= --l ...
随机推荐
- js数组sort方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 关于丢失或者损坏/etc/fstab文件后的一些探讨
1.模仿,假设不小心删除了/etc/fstab文件:大家都知道,Linux系统启动的时候会读取该文件来挂载分区,如果缺失该文件,系统一般不能正常启动. 2.采用reboot命令或者alt+ctrl+d ...
- 用Copy命令合并文件
用Copy命令合并文件 这个文章是在我以前的百度空间里面发表过的,后来因为某个内分泌失调的管理员把我的空间http://hi.baidu.com/kamdy 封了! 旧事不提,还是回到主题吧,这个 ...
- Qt——文件对话框
教程:https://www.devbean.net/2012/09/qt-study-road-2-file-dialog/ 代码如下: //mainwindow.h #ifndef MAINWIN ...
- Church 整数前驱的推导
Church 整数前驱的推导比其后继复杂得多,wiki中一个前驱的定义据王垠的博客里说,是他一个数学系的同学花一星期时间推导出来的, 其定义确实比其它介绍lambda的文章中用pair来实现(据说是图 ...
- 例说hg(五)————创建repository
本文由博主原创,转载请注明出处(保留此处和链接): IT人生(http://blog.csdn.net/robinblog/article/details/17933747) 有很多网站提供了免费的M ...
- delphi 函数参数传递 默认参数(传值)、var(传址)、out(输出)、const(常数)四类
参数可以分为: 默认参数(传值).var(传址).out(输出).const(常数)四类 {默认参数是传值, 不会被改变} function MyF1(x: Integer): Integer; be ...
- shell 获取脚本的绝对路径
basepath=$(cd `dirname $0`; pwd) 在此解释下basepath : dirname $0,取得当前执行的脚本文件的父目录 cd `dirname $0`,进入这个目录(切 ...
- 不同.NET Framework版本下ASP.NET FormsAuthentication的兼容性
假设站点A加密使用.NET Framework 2.0,站点B解密使用.NET Framework 4.0,除了保持MachineKey相同外还需要进行如下设置: 1.Web.config的<a ...
- calloc(), malloc(), realloc(), free(),alloca()
内存区域可以分为栈.堆.静态存储区和常量存储区,局部变量,函数形参,临时变量都是在栈上获得内存的,它们获取的方式都是由编译器自动执行的. 利用指针,我们可以像汇编语言一样处理内存地址,C 标准函数库提 ...