正则和xpath在网页中匹配字段的效率比较
1. 测试页面是 https://www.hao123.com/,这个是百度的导航
2. 为了避免网络请求带来的差异,我们把网页下载下来,命名为html,不粘贴其代码。
3.测试办法:
我们在页面中找到 百度新闻 关键字的链接,为了能更好的对比,使程序运行10000次,比较时间差异:
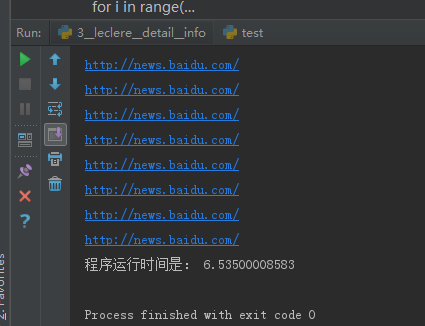
1.正则编码及其时间
start_time = time.time()
for i in range(0,10000):
baidu_news = re.findall('腾讯新闻</a></span><span><a class="sitelink mainlink singglelink" cls="xw,n" alog-custom="ind:xw,sal:0,atd:" href="(.*?)">百度新闻</a>',html)[0]
print baidu_news end_time = time.time()
print "程序运行时间是:",end_time - start_time
运行时间:6.5 秒钟
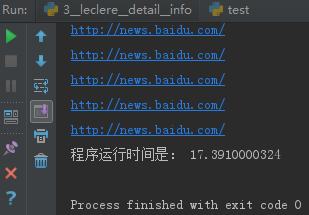
2.xpath 编码及其时间
start_time = time.time()
selector = etree.HTML(html) for i in range(,):
content=selector.xpath('//*[@id="coolsite-top"]/div[4]/span[3]/a/@href')[]
print content end_time = time.time()
print "程序运行时间是:",end_time - start_time
运行时间:17.39 秒钟
总结:其中 selector = etree.HTML(html) 将源码转化为能被XPath匹配的格式,这个过程失比较耗时的。
结论:正则效率优于xpath
如有异议,请联系作者,谢谢
正则和xpath在网页中匹配字段的效率比较的更多相关文章
- 使用Xpath从网页中获取数据
/// <summary> /// 从官方网站中抓取产品信息存放在本地数据库中 /// </summary> /// <returns></returns&g ...
- oracle 正则查询json返回报文中某个字段的值
接口返回报文为json 格式,如下: {"body":{"businessinfo":{"c1rate":"25.00" ...
- python3 利用正则获取网页中的想保存下来的内容
需要获取某个网页中表格部分中某个产品的成份 分析在html中成份的元素代码 <a href="/composition/4c3060178d1184935a48c4e51be4f63f ...
- (转载)MySQL LIKE 用法:搜索匹配字段中的指定内容
(转载)http://www.5idev.com/p-php_mysql_like.shtml MySQL LIKE 语法 LIKE 运算符用于 WHERE 表达式中,以搜索匹配字段中的指定内容,语法 ...
- js正则实现从一段复杂html代码字符串中匹配并处理特定信息
js正则实现从一段复杂html代码字符串中匹配并处理特定信息 问题: 现在要从一个复杂的html代码字符串(包含各种html标签,数字.中文等信息)中找到某一段特别的信息(被一对“|”包裹着),并对他 ...
- 小程序开发-使用xpath解析网页html中的数据
最新有个微信小程序的开发需求,需要从网页中提取一些元素信息,获取有效数据 1. 了解到微信小程序里面不能直接操作dom元素,所以我们需要使用一些其他的npm包 2. 经过查到各方面的文档,最新决定用x ...
- mybitis中对象字段与表中字段名称不匹配(复制)
开发中,实体类中的属性名和对应的表中的字段名不一定都是完全相同的,这样可能会导致用实体类接收返回的结果时导致查询到的结果无法映射到实体类的属性中,那么该如何解决这种字段名和实体类属性名不相同的冲突呢? ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
随机推荐
- 在Windows中监视IO性能
附:在Windows中监视IO性能 本来准备写一篇windows中监视IO性能的,后来发现好像可写的内容不多,windows在细节这方面做的不是那么的好,不过那些基本信息还是有的. 在Windows中 ...
- All you should know about NUMA in VMware!
http://www.elasticvision.info/ All you should know about NUMA in VMware! Lets try answering some typ ...
- 简单的WebRTC例子
webrtc网上封装的很多,demo很多都是一个页面里实现的,今天实现了个完整的 , A 发视频给 B. A offer.html作为offer <!DOCTYPE html> <h ...
- Word转PDF非常好用的软件——pdfFactory Pro
pfdFactory Pro把word转为pdf的操作步骤: 1.打开将要转换的word的文档: 2.文件--->打印: 弹出如下对话框: 单击确定后弹出:
- hive中简单介绍分区表(partition table)——动态分区(dynamic partition)、静态分区(static partition)
一.基本概念 hive中分区表分为:范围分区.列表分区.hash分区.混合分区等. 分区列:分区列不是表中的一个实际的字段,而是一个或者多个伪列.翻译一下是:“在表的数据文件中实际上并不保存分区列的信 ...
- 算法笔记_199:第二届蓝桥杯软件类决赛真题(C语言本科)
前言:以下代码部分仅供参考,C语言解答部分全部来自网友,Java语言部分部分参考自网友,对于答案的正确性不能完全保证. 试题1 数论中有著名的四方定理:所有自然数至多只要用四个数的平方和就可以表示. ...
- Sql server中依据存储过程中的部分信息查找存储过程名称的方法【视图和Function】
1.查询的语句: select a.id,b.name,a.*,b.* from syscomments a join sysobjects b on a.id=b.id where b.xtype= ...
- 〖Linux〗安装和使用virtualenv,方便多个Python版本中切换
1. 安装pip easy_install pip 2. 安装virtualenvwrapper sudo pip install virtualenvwrapper 3. 使用virtualenv ...
- Windows在cmd杀掉进程
问题描述: 在windows根据pid杀进程 问题解决: tasklist查看当前系统中的进程列表,然后针对你要杀的进程使用taskkill命令 #根据服务名taskkill /im nginx.ex ...
- SpringBoot集成MyBatis的分页插件PageHelper
俗话说:好