mxnet(gluon) 实现DQN简单小例子
参考文献
关于增强学习的基本知识可以参考第二个链接,讲的挺有意思的。DQN的东西可以看第一个链接相关视频。课程中实现了Tensorflow和pytorch的示例代码。本文主要是改写成了gluon实现
Q-learning的算法流程

DQN的算法流程

对于DQN的理解:
增强学习中需要学习的东西是Q-table,决策表。而针对于state space空间太大的情形,很难甚至不可能构建这个决策表。而决策表其实就是一种映射 (s,a)->R, 那么这种映射可以通过网络来构建,于是就有了DQN
下面来看代码
import mxnet as mx
import mxnet.ndarray as nd
import mxnet.gluon as gluon
import numpy as np
import mxnet.gluon.nn as nn
import gym
BATCH_SIZE=64 # 训练网络时的batchsize
LR=0.01 # 权重更新的学习率
EPSILON=0.9 # 每次以概率选择最有策略,有点类似于生物算法的思想
GAMMA=0.5 # 计算q_target是下一个状态收益对当前的影响
TARGET_REPLACE_ITER=100 # 保存网络参数,可以理解为上一次的映射,的频率
MEMORY_CAPACITY=1000 # 历史决策
env = gym.make('CartPole-v0') # 调用OpenAI.gym构建的env
env = env.unwrapped
N_ACTIONS=env.action_space.n # 备选策略的个数
N_STATES = env.observation_space.shape[0] # 状态向量的长度
# 定义所需要的网络,示例仅随意设置了几层
class Net(nn.HybridBlock):
def __init__(self,**kwargs):
super(Net, self).__init__(**kwargs)
with self.name_scope():
self.fc1 = nn.Dense(16, activation='relu')
self.fc2 = nn.Dense(32, activation='relu')
self.fc3 = nn.Dense(16, activation='relu')
self.out = nn.Dense(N_ACTIONS)
def hybrid_forward(self, F, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
actions_value = self.out(x)
return actions_value
# 定义网络权重的拷贝方法。主要是因为DQN learning中采用off-policy更新,也就是说需要上一次的映射图,这可以使用网络上一次的权重保存,这个用以保存权重的网络只有前向功能,类似于查表,并不更新参数,直到满足一定条件时将当前网络参数再次存储
def copy_params(src, dst):
dst.initialize(force_reinit=True, ctx=mx.cpu())
layer_names = ['dense0_weight', 'dense0_bias','dense1_weight','dense1_bias',
'dense2_weight','dense2_bias','dense3_weight','dense3_bias']
for i in range(len(layer_names)):
dst.get(layer_names[i]).set_data(src.get(layer_names[i]).data())
# 定义DQN类,包含网络、策略选择、保存记录等
class DQN(object):
def __init__(self):
self.eval_net, self.target_net = Net(), Net()
self.eval_net.initialize()
self.target_net.initialize()
x=nd.random_uniform(shape=(1,N_STATES))
_ = self.eval_net(x)
_ = self.target_net(x) # mxnet的延迟初始化特性
self.learn_step_counter = 0
self.memory_counter = 0
self.memory = np.zeros(shape=(MEMORY_CAPACITY, N_STATES*2+2))
# 每一行存储的是当前状态,选择的action, 当前的回报, 下一步的状态
self.trainer = gluon.Trainer(self.eval_net.collect_params(), 'sgd',\
{'learning_rate': LR,'wd':1e-4})
self.loss_func = gluon.loss.L2Loss()
self.cost_his=[]
def choose_action(self, x):
if np.random.uniform()<EPSILON:
# EPSILON的概率选择最可能动作
x = nd.array([x])
actions_value = self.eval_net(x)
action = int(nd.argmax(actions_value, axis=1).asscalar())
else:
action = np.random.randint(0, N_ACTIONS)
return action
def store_transition(self,s,a,r,s_):
# 存储历史纪录
transition = np.hstack((s,[a,r],s_))
index = self.memory_counter % MEMORY_CAPACITY
# 主要是为了循环利用存储空间
self.memory[index,:] = transition
self.memory_counter += 1
def learn(self):
if self.learn_step_counter % TARGET_REPLACE_ITER==0:
# 每学习一定间隔之后,将当前的状态
copy_params(self.eval_net.collect_params(), self.target_net.collect_params())
self.learn_step_counter += 1
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE)
# 随机选择一组状态
b_memory = self.memory[sample_index,:]
b_s = nd.array(b_memory[:,:N_STATES])
b_a = nd.array(b_memory[:,N_STATES:N_STATES+1])
b_r = nd.array(b_memory[:,N_STATES+1:N_STATES+2])
b_s_= nd.array(b_memory[:,-N_STATES:])
with mx.autograd.record():
q_eval = self.eval_net(b_s) # 预估值
with mx.autograd.pause():
q_next = self.target_net(b_s_) # 历史值 batch x N_ACTIONS
q_target = b_r + GAMMA*nd.max(q_next, axis=1)
loss = self.loss_func(q_eval, q_target)
self.cost_his.append(nd.mean(loss).asscalar())
loss.backward()
self.trainer.step(BATCH_SIZE)
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
# 训练
dqn = DQN()
for i_episode in range(500):
s = env.reset()
while True:
env.render()
a = dqn.choose_action(s)
s_, r, done, info = env.step(a)# 到达的状态,收益,是否结束
x,x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians-0.5
r = r1 + r2
dqn.store_transition(s,a,r,s_)
if dqn.memory_counter > MEMORY_CAPACITY:
dqn.learn()
if done:
break
s = s_
dqn.plot_cost()
loss曲线
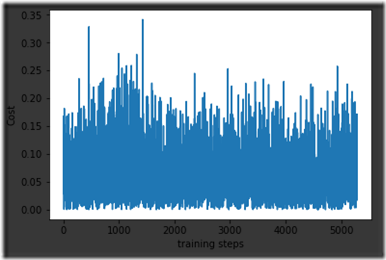
训练的loss似乎并没有收敛,还在找原因
ps. 第一次使用open live writer写博客,体验很差!!!!!我需要公式、代码和图片的支持。。。。还在寻找中
mxnet(gluon) 实现DQN简单小例子的更多相关文章
- php+jquery+ajax+json简单小例子
直接贴代码: <html> <title>php+jquery+ajax+json简单小例子</title> <?php header("Conte ...
- C#利用事件与委托进行窗体间传值简单小例子
本篇博客是利用C#委托与事件进行窗体间传值的简单小例子 委托与事件的详细解释大家可以参照张子阳的博客: http://www.tracefact.net/CSharp-Programming/Dele ...
- ASP.NET Cookie对象到底是毛啊?(简单小例子)
记得刚接触asp.net的时候,就被几个概念搞的头痛不已,比如Request,Response,Session和Cookie.然后还各种在搜索引擎搜,各种问同事的,但是结果就是自己还是很懵的节奏. 那 ...
- 关键字Lock的简单小例子
一.什么是Lock? Lock——字面上理解就是锁上:锁住:把……锁起来的意思: 为什么要锁?要锁干什么?——回到现实中可想象到,这个卫生间我要上,其他人不要进来!(所以我要锁住门):又或者土味情话所 ...
- 详细解读Android中的搜索框(一)—— 简单小例子
这次开的是一个讲解SearchView的栏目,第一篇主要是给一个小例子,让大家对这个搜索视图有一个了解,之后再分布细化来说. 目标: 我们先来定个目标,我们通过搜索框来输入要搜索的联系人名字,输入的时 ...
- 关于ExpandableListView用法的一个简单小例子
喜欢显示好友QQ那样的列表,可以展开,可以收起,在android中,以往用的比较多的是listview,虽然可以实现列表的展示,但在某些情况下,我们还是希望用到可以分组并实现收缩的列表,那就要用到an ...
- Ajax的简单小例子
1.首先下载ajax.dll,一个百度一下都有下载的!自行查找. 2.把ajax.dll导入到工程.右键工程-->添加引用--->浏览,找到下载好的ajax.dll文件,点击确定,这时候在 ...
- SpringMVC静态文件(图片)访问+js访问 简单小例子
项目文件布局: web.xml文件: <?xml version="1.0" encoding="UTF-8"?> <web-app vers ...
- MVC实现(简单小例子)
Here I’ll demonstrate simple Spring MVC framework for building web applications. First thing first. ...
随机推荐
- javascript中的console.log有什么作用?
javascript中的console.log有什么作用? 主要是方便你调式javascript用的.你可以看到你在页面中输出的内容. 相比alert他的优点是:他能看到结构话的东西,如果是alert ...
- 20145307陈俊达_安卓逆向分析_Xposed的hook技术研究
20145307陈俊达_安卓逆向分析_Xposed的hook技术研究 引言 其实这份我早就想写了,xposed这个东西我在安卓SDK 4.4.4的时候就在玩了,root后安装架构,起初是为了实现一些屌 ...
- C++ tinyXml直接解析XML字符串
转载:http://www.cnblogs.com/1024Planet/p/4401929.html <?xml version=\"1.0\" encoding=\&qu ...
- List集合实现简易学生管理
题目: 代码: package org.wlgzs; import java.util.ArrayList; import java.util.List; import java.util.Scann ...
- QT学习资源
http://www.qter.org/portal.php?mod=view&aid=26
- HDU 5992 Finding Hotels(KD树)题解
题意:n家旅店,每个旅店都有坐标x,y,每晚价钱z,m个客人,坐标x,y,钱c,问你每个客人最近且能住进去(非花最少钱)的旅店,一样近的选排名靠前的. 思路:KD树模板题 代码: #include&l ...
- JDBC中 execute 与 executeUpdate的区别
相同点 execute与executeUpdate的相同点:都可以执行增加,删除,修改 不同点 execute可以执行查询语句 然后通过getResultSet,把结果集取出来 executeUpda ...
- [微信开发] - 微信支付 JSAPI 形式
微信官方的JSAPI文档 微信官方的JSAPI支付SDK与DEMO下载 查看JSAPI的API可以从这里看 下载了支付DEMO其实有些地方不对的,比如如果做沙盒测试的时候,需要使用getsignkey ...
- java命令行执行程序解决依赖外部jar包的问题
用java命令行直接执行程序,如果这个程序需要引用外部jar包.就不能单纯用java xx来执行 如果你的jar包和程序就在一个目录: 编译 javac -cp D:\yy\yy.jar,D\xx\x ...
- python 加密与解密
加密算法分类 对称加密算法: 对称加密采用了对称密码编码技术,它的特点是文件加密和解密使用相同的密钥 发送方和接收方需要持有同一把密钥,发送消息和接收消息均使用该密钥. 相对于非对称加密,对称加密具有 ...