http://my.oschina.net/zhangjiawen/blog/185625
1基于用户的协同过滤算法:
基于用户的协同过滤算法是推荐系统中最古老的的算法,可以说是这个算法的诞生标志了推荐系统的诞生。该算法在1992年被提出,并应用于邮件过滤系统,1994年被GroupLens用于新闻过滤。
在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的而用户A没有接触过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,通过余弦相似度计算用户的相似度。由于很多用户相互之间并没有对同样的物品产生过行为,即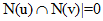 ,因此可以先计算
,因此可以先计算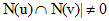 的用户对(u,v)。为此,可以首先建立物品到用户的倒查表,对于每个物品保存对该物品产生过行为的用户列表。令稀疏矩阵
的用户对(u,v)。为此,可以首先建立物品到用户的倒查表,对于每个物品保存对该物品产生过行为的用户列表。令稀疏矩阵 ,假设用户u和用户v同时属于倒查表中K个物品对应的用户列表,就有
,假设用户u和用户v同时属于倒查表中K个物品对应的用户列表,就有 (即用户u和v对相同物品产生正反馈的物品数),从而可以扫描倒查表中每个物品对应的用户列表,将用户列表中的两两用户对应的
(即用户u和v对相同物品产生正反馈的物品数),从而可以扫描倒查表中每个物品对应的用户列表,将用户列表中的两两用户对应的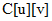 加1,最终就可以获得所有用户之间不为0的
加1,最终就可以获得所有用户之间不为0的 (也就是余弦相似度的分子)。
(也就是余弦相似度的分子)。
得到用户之间的兴趣相似度之后,基于用户的协同过滤算法(User Based Collaborative Filering)会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下公式度量了UserCF算法中用户u对物品i的感兴趣程度:
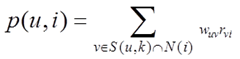
其中,S(u,k)包含和用户u兴趣相似度最接近的k个用户集合,N(i)是对物品i有过行为的用户集合,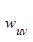 是用户u和用户v的兴趣相似度,
是用户u和用户v的兴趣相似度, 代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,因此
代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,因此 为1。
为1。
根据以上思路,使用Python实现UserCF算法的代码如下:
004 |
def __init__(self,datafile = None): |
005 |
self.datafile = datafile |
009 |
def readData(self,datafile = None): |
011 |
read the data from the data file which is a data set |
013 |
self.datafile = datafile or self.datafile |
015 |
for line in open(self.datafile): |
016 |
userid,itemid,record,_ = line.split() |
017 |
self.data.append((userid,itemid,int(record))) |
019 |
def splitData(self,k,seed,data=None,M = 8): |
022 |
testdata is a test data set |
023 |
traindata is a train set |
024 |
test data set / train data set is 1:M-1 |
028 |
data = data or self.data |
030 |
for user,item, record in self.data: |
031 |
if random.randint(0,M) == k: |
032 |
self.testdata.setdefault(user,{}) |
033 |
self.testdata[user][item] = record |
035 |
self.traindata.setdefault(user,{}) |
036 |
self.traindata[user][item] = record |
038 |
def userSimilarityBest(self,train = None): |
040 |
the other method of getting user similarity which is better than above |
041 |
you can get the method on page 46 |
042 |
In this experiment,we use this method |
044 |
train = train or self.traindata |
045 |
self.userSimBest = dict() |
047 |
for u,item in train.items(): |
048 |
for i in item.keys(): |
049 |
item_users.setdefault(i,set()) |
051 |
user_item_count = dict() |
053 |
for item,users in item_users.items(): |
055 |
user_item_count.setdefault(u,0) |
056 |
user_item_count[u] += 1 |
059 |
count.setdefault(u,{}) |
060 |
count[u].setdefault(v,0) |
062 |
for u ,related_users in count.items(): |
063 |
self.userSimBest.setdefault(u,dict()) |
064 |
for v, cuv in related_users.items(): |
065 |
self.userSimBest[u][v] = cuv / math.sqrt(user_item_count[u] * user_item_count[v] * 1.0) |
067 |
def recommend(self,user,train = None,k = 8,nitem = 40): |
068 |
train = train or self.traindata |
070 |
interacted_items = train.get(user,{}) |
071 |
for v ,wuv in sorted(self.userSimBest[user].items(),key = lambda x : x[1],reverse = True)[0:k]: |
072 |
for i , rvi in train[v].items(): |
073 |
if i in interacted_items: |
077 |
return dict(sorted(rank.items(),key = lambda x :x[1],reverse = True)[0:nitem]) |
079 |
def recallAndPrecision(self,train = None,test = None,k = 8,nitem = 10): |
081 |
Get the recall and precision, the method you want to know is listed |
084 |
train = train or self.traindata |
085 |
test = test or self.testdata |
089 |
for user in train.keys(): |
090 |
tu = test.get(user,{}) |
091 |
rank = self.recommend(user, train = train,k = k,nitem = nitem) |
092 |
for item,_ in rank.items(): |
097 |
return (hit / (recall * 1.0),hit / (precision * 1.0)) |
099 |
def coverage(self,train = None,test = None,k = 8,nitem = 10): |
100 |
train = train or self.traindata |
101 |
test = test or self.testdata |
102 |
recommend_items = set() |
104 |
for user in train.keys(): |
105 |
for item in train[user].keys(): |
107 |
rank = self.recommend(user, train, k = k, nitem = nitem) |
108 |
for item,_ in rank.items(): |
109 |
recommend_items.add(item) |
110 |
return len(recommend_items) / (len(all_items) * 1.0) |
112 |
def popularity(self,train = None,test = None,k = 8,nitem = 10): |
115 |
the algorithm on page 44 |
117 |
train = train or self.traindata |
118 |
test = test or self.testdata |
119 |
item_popularity = dict() |
120 |
for user ,items in train.items(): |
121 |
for item in items.keys(): |
122 |
item_popularity.setdefault(item,0) |
123 |
item_popularity[item] += 1 |
126 |
for user in train.keys(): |
127 |
rank = self.recommend(user, train, k = k, nitem = nitem) |
128 |
for item ,_ in rank.items(): |
129 |
ret += math.log(1+item_popularity[item]) |
131 |
return ret / (n * 1.0) |
133 |
def testUserBasedCF(): |
134 |
cf = UserBasedCF('u.data') |
135 |
cf.userSimilarityBest() |
136 |
print "%3s%20s%20s%20s%20s" % ('K',"recall",'precision','coverage','popularity') |
137 |
for k in [5,10,20,40,80,160]: |
138 |
recall,precision = cf.recallAndPrecision( k = k) |
139 |
coverage = cf.coverage(k = k) |
140 |
popularity = cf.popularity(k = k) |
141 |
print "%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (k,recall * 100,precision * 100,coverage * 100,popularity) |
143 |
if __name__ == "__main__": |
2 基于物品的协同过滤算法:
基于物品的协同过滤算法(Item-Based Collaborative Filtering)是目前业界应用最多的算法,亚马逊、Netflix、Hulu、YouTube都采用该算法作为其基础推荐算法。
基于用户的协同过滤算法有一些缺点:随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似平方关心。并且,基于用户的协同过滤算法很难对推荐结果做出解释。因此亚马逊提出了基于物品的协同过滤算法。
基于物品的协同过滤算法给用户推荐那些和他们之前喜欢的物品相似的物品。不过ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算用户之间的相似度,也就是说物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B(这一点也是基于物品的协同过滤算法和基于内容的推荐算法最主要的区别)。同时,基于物品的协同过滤算法可以利用用户的历史行为给推荐结果提供推荐解释,用于解释的物品都是用户之前喜欢的或者购买的物品。
“Customers Who Bought This Item Also Bought”(亚马逊显示相关物品推荐时的标题),从这句话的定义出发,利用以下公式定义物品之间的相似度:

其中N(i)是喜欢物品i的用户数,分子 是同时喜欢物品i和物品j的用户数。这个公式惩罚了物品j的权重,减轻了热门物品会和很多物品相似的可能性(这样wij的值会很大,接近于1)。这个公式说明两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。
是同时喜欢物品i和物品j的用户数。这个公式惩罚了物品j的权重,减轻了热门物品会和很多物品相似的可能性(这样wij的值会很大,接近于1)。这个公式说明两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。
和UserCF算法类似,用ItemCF算法计算物品相似度时也可以首先建立用户-物品倒排表,即对每个用户建立一个包含他喜欢的物品的列表,然后对于每个用户,将他物品列表中的物品两两在共现矩阵C中加1,最终就可以得到所有物品之间不为0的 ,也就是公式中的分子。
,也就是公式中的分子。
在得到物品之间的相似度后,ItemCF通过如下公式计算用户u对一个物品i的兴趣:
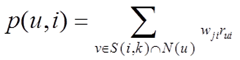
其中,N(u)是用户喜欢的物品集合,S(i,k)是和物品i最相似的k个物品的集合, 是物品j和物品i的相似度,
是物品j和物品i的相似度, 是用户u对物品i的兴趣,对于隐反馈数据集,如果用户u对物品i有过行为,即可令
是用户u对物品i的兴趣,对于隐反馈数据集,如果用户u对物品i有过行为,即可令 为1。
为1。
根据以上思路,使用Python实现ItemCF算法的代码如下:
004 |
def __init__(self, datafile = None): |
005 |
self.datafile = datafile |
009 |
def readData(self,datafile = None): |
010 |
self.datafile = datafile or self.datafile |
012 |
file = open(self.datafile,'r') |
013 |
for line in file.readlines()[0:100*1000]: |
014 |
userid, itemid, record,_ = line.split() |
015 |
self.data.append((userid,itemid,int(record))) |
017 |
def splitData(self,k,seed,data=None,M = 8): |
020 |
data = data or self.data |
022 |
for user,item,record in self.data: |
023 |
if random.randint(0,7) == k: |
024 |
self.testdata.setdefault(item,{}) |
025 |
self.testdata[item][user] = record |
027 |
self.traindata.setdefault(item,{}) |
028 |
self.traindata[item][user] = record |
030 |
def ItemSimilarity(self, train = None): |
031 |
train = train or self.traindata |
032 |
self.itemSim = dict() |
034 |
item_user_count = dict() #item_user_count{item: likeCount} the number of users who like the item |
035 |
count = dict() #count{i:{j:value}} the number of users who both like item i and j |
036 |
for user, item in train.items(): #initialize the user_items{user: items} |
037 |
for i in item.keys(): |
038 |
item_user_count.setdefault(i,0) |
039 |
item_user_count[i] += 1 |
040 |
for j in item.keys(): |
043 |
count.setdefault(i,{}) |
044 |
count[i].setdefault(j,0) |
046 |
for i, related_items in count.items(): |
047 |
self.itemSim.setdefault(i,dict()) |
048 |
for j, cuv in related_items.items(): |
049 |
self.itemSim[i].setdefault(j,0) |
050 |
self.itemSim[i][j] = cuv / math.sqrt(item_user_count[i] * item_user_count[j] * 1.0) |
052 |
def recommend(self,user,train = None, k = 8, nitem = 40): |
053 |
train = train or self.traindata |
055 |
ru = train.get(user,{}) |
056 |
for i,pi in ru.items(): |
057 |
for j,wj in sorted(self.itemSim[i].items(), key = lambda x:x[1], reverse = True)[0:k]: |
062 |
#print dict(sorted(rank.items(), key = lambda x:x[1], reverse = True)[0:nitem]) |
063 |
return dict(sorted(rank.items(), key = lambda x:x[1], reverse = True)[0:nitem]) |
065 |
def recallAndPrecision(self,train = None,test = None,k = 8,nitem = 10): |
066 |
train = train or self.traindata |
067 |
test = test or self.testdata |
071 |
for user in train.keys(): |
072 |
tu = test.get(user,{}) |
073 |
rank = self.recommend(user,train = train,k = k,nitem = nitem) |
074 |
for item,_ in rank.items(): |
079 |
return (hit / (recall * 1.0),hit / (precision * 1.0)) |
081 |
def coverage(self,train = None,test = None,k = 8,nitem = 10): |
082 |
train = train or self.traindata |
083 |
test = test or self.testdata |
084 |
recommend_items = set() |
086 |
for user in train.keys(): |
087 |
for item in train[user].keys(): |
089 |
rank = self.recommend(user, train, k = k, nitem = nitem) |
090 |
for item,_ in rank.items(): |
091 |
recommend_items.add(item) |
092 |
return len(recommend_items) / (len(all_items) * 1.0) |
094 |
def popularity(self,train = None,test = None,k = 8,nitem = 10): |
097 |
the algorithm on page 44 |
099 |
train = train or self.traindata |
100 |
test = test or self.testdata |
101 |
item_popularity = dict() |
102 |
for user ,items in train.items(): |
103 |
for item in items.keys(): |
104 |
item_popularity.setdefault(item,0) |
105 |
item_popularity[item] += 1 |
108 |
for user in train.keys(): |
109 |
rank = self.recommend(user, train, k = k, nitem = nitem) |
110 |
for item ,_ in rank.items(): |
111 |
ret += math.log(1+item_popularity[item]) |
113 |
return ret / (n * 1.0) |
116 |
ubcf = ItemBasedCF('u.data') |
118 |
ubcf.splitData(4,100) |
119 |
ubcf.ItemSimilarity() |
121 |
rank = ubcf.recommend(user,k = 3) |
122 |
for i,rvi in rank.items(): |
123 |
items = ubcf.testdata.get(user,{}) |
124 |
record = items.get(i,0) |
125 |
print "%5s: %.4f--%.4f" %(i,rvi,record) |
127 |
def testItemBasedCF(): |
128 |
cf = ItemBasedCF('u.data') |
130 |
print "%3s%20s%20s%20s%20s" % ('K',"recall",'precision','coverage','popularity') |
131 |
for k in [5,10,20,40,80,160]: |
132 |
recall,precision = cf.recallAndPrecision( k = k) |
133 |
coverage = cf.coverage(k = k) |
134 |
popularity = cf.popularity(k = k) |
135 |
print "%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (k,recall * 100,precision * 100,coverage * 100,popularity) |
137 |
if __name__ == "__main__": |
3 UserCF和ItemCF的综合比较:
UserCF给用户推荐那些和他有共同兴趣爱好的用户喜欢的物品,而ItemCF给用户推荐那些和他之前喜欢的物品类似的物品。从这个原理可以看到,UserCF的推荐结果着重于反映和用户兴趣相似的小群体的热点,而ItemCF的推荐结果着重于维系用户的历史兴趣。UserCF的推荐更社会化,反映了用户所在的小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反映了用户自己的兴趣传承。同时,从技术上来说,UserCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品相似度矩阵。从存储的角度来说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大的空间,同理,如果物品很多,维护物品相似度矩阵代价较大。
对于UserCF和ItemCF,我们采用http://www.grouplens.org/node/73 的数据集进行测试,使用准确率/召回率、覆盖率和流行度对实验结果进行评测。
对用户u推荐N个物品R(u),令用户u在测试集上喜欢的物品集合为T(u),则:
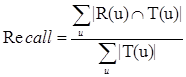

召回率描述有多少比例的用户-物品评分记录包含在最终的推荐列表中,而准确率描述最终的推荐列表中有多少比例是发生过的用户-物品评分记录。
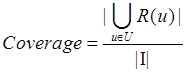
覆盖率表示最终的推荐列表中包含多大比例的物品,如果所有的物品都被推荐给至少一个用户,那么覆盖率就是100%。
最后还需要评测推荐的新颖度,这里用推荐列表中物品的平均流行度度量推荐结果的新颖度,如果推荐出的物品都很热门,说明推荐的新颖度较低,否则说明推荐结果比较新颖。

图1 UserCF实验结果

图2 ItemCF实验结果
对于以上UserCF和ItemCF的实验结果可以看出,推荐系统的精度指标(准确率和召回率)并不和参数k成线性关系。推荐结果的精度对k也不是特别敏感,只要选在一定的区域内,就可以获得不错的精度。
对于覆盖率而言,k越大则推荐结果的覆盖率越低,覆盖率的降低是因为流行度的增加,随着流行度增加,推荐算法越来越倾向于推荐热门的物品,这是因为k决定了推荐算法在做推荐时参考多少和你兴趣相似的其他用户的兴趣,如果k越大,参考的人或者物品越多,结果就越来越趋近于全局热门的物品。
- 推荐系统第2周--itemCF和userCF
推荐系统分类 基于应用领域分类:电子商务推荐,社交好友推荐,搜索引擎推荐,信息内容推荐基于设计思想:基于协同过滤的推荐,基于内容的推荐,基于知识的推荐,混合推荐基于使用何种数据:基于用户行为数据的推荐 ...
- 推荐系统之隐语义模型(LFM)
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统之隐语义模型LFM
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- 推荐系统——online(上)
框架介绍 上一篇从总体上介绍了推荐系统,推荐系统online和offline是两个组成部分,其中offline负责数据的收集,存储,统计,模型的训练等工作:online部分负责处理用户的请求,模型数据 ...
- Mahout介绍和简单应用
Mahout学习(主要学习内容是Mahout中推荐部分的ItemCF.UserCF.Hadoop集群部署运行) 1.Mahout是什么? Mahout是一个算法库,集成了很多算法. Apache Ma ...
- 推荐系统第5周--- 基于内容的推荐,隐语义模型LFM
基于内容的推荐
- 基于Spark机器学习和实时流计算的智能推荐系统
概要: 随着电子商务的高速发展和普及应用,个性化推荐的推荐系统已成为一个重要研究领域. 个性化推荐算法是推荐系统中最核心的技术,在很大程度上决定了电子商务推荐系统性能的优劣,决定着是否能够推荐用户真正 ...
- 大数据学习路线copy自淘宝
一.hadoop视频学习(入门到精通) 二.数据挖掘(入门到精通) 三.Hadoop学习路线 1.开发前期准备 首先,如果你没有Java和Linux基础,建议你先简单学一下这两门课程,此宝贝里面都为你 ...
随机推荐
- 数据库操作类——C#
整理数据库操作类以便取用: using System; using System.Collections.Generic; using System.Linq; using System.Web; u ...
- 关于使用react的思考
1. 组件化开发:将可以复用的部分独立封装成一个组件,每个部分的数据互不影响
- svn简单记录
记录一下工作中常用到的svn命令 一.文件的提交流程 1.svn up // 先更新本地文件 2.svn st // svn status 查看要提交的文件 3.#svn ci -m &quo ...
- HTML5之Javascript多线程
Javascript执行机制 在HTML5之前,浏览器中JavaScript的运行都是以单线程的方式工作的,虽然有多种方式实现了对多线程的模拟(例如:Javascript 中的 setint ...
- Redis "MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk"问题的解决(转)
今天第二次遇到Redis “MISCONF Redis is configured to save RDB snapshots, but is currently not able to persis ...
- USBDM RS08/HCS08/HCS12/Coldfire V1,2,3,4/DSC/Kinetis Debugger and Programmer -- Driver Install
Installation of USBDM USB drivers for Windows There are four installers provided: USBDM_Drivers_x_x_ ...
- CentOS 7.x,不重新编译 PHP,动态安装 imap 扩展
先前的教程:PHP5不重新编译,如何安装自带的未安装过的扩展,如soap扩展? # 安装依赖包 yum install -y libc-client-devel /usr/local/src/cent ...
- HDU 4081 Qin Shi Huang's National Road System(最小生成树/次小生成树)
题目链接:传送门 题意: 有n坐城市,知道每坐城市的坐标和人口.如今要在全部城市之间修路,保证每一个城市都能相连,而且保证A/B 最大.全部路径的花费和最小,A是某条路i两端城市人口的和,B表示除路i ...
- 用xcode 5 开发访问IOS 7上面的通讯录有问题
NSMutableArray *addressBookTemp = [NSMutableArray array]; ABAddressBookRef addressBooks = ABAddressB ...
- C#高级编程小结
小结 这几章主要介绍了如何使用新的dynamic类型,还讨论了编译器在遇到dynamic类型时会做什么.还讨论了DLP,可以把它包含在简单的应用程序中.并通过Pythin使用DLR,执行Python脚 ...