py-faster-rcnn
踩坑:
1. 服务器上训练:
sh ./experiments/scripts/faster_rcnn_end2end.sh
会各种报错
有说是因为#!/bin/bash的问题,改过,不行。
改成如下ok
sudo ./experiments/scripts/faster_rcnn_end2end.sh
2. __C.DEDUP_BOXES = 1./16. 取决于网络结构,就是之前pool和stride的大小。关于这个参数,大神git上有回复#34。
3. KeyError: 'max_overlaps' 删除两个cache目录下的.pkl #501
4. 编译好的py-faster-rcnn,编译好以后测试demo.py跑起来了,复制一份打算同时训练,发生了hdf5错误,在复制的faster rcnn里make clean, 重新make就没问题了。
5.
File "pascal_voc.py", line 269, in _write_voc_results_file
with open(filename, 'w+') as f:
IOError: [Errno 2] No such file or directory: '~/wkspace/caffe_wk/branch_faster_rcnn/data/VOCdevkit2007/results/VOC2007/Main/comp4_a4f85e93-deaa-4519-ae71-969f285f439e_det_test_heart.txt'
报错是因为VOCdevkit2007这个目录下没有results/VOC2007/Main/
6. 用VGG finetune自己的模型,首先是类别不一样的话不能用默认的VGG.v2.caffemodel,那个带了后面的21分类。用VGG_ILSVRC_16_layers.caffemodel
然后会报错:TypeError: slice indices must be integers or None or have an __index__ method,仍旧大神博客解决#480,用:
After line 126,
start=int(start)
end=int(end)
After line 166,
fg_rois_per_this_image=int(fg_rois_per_this_image)
7. 迭代到一万多报错:keep = np.where((ws >= min_size) & (hs >= min_size))[0],修改lr=0.0001
8. assert(boxes[:,2]>=boxes[:,0].all()
去掉-1操作,躲过了框在边界上的坑,没有躲过标注标反的坑,最后修改lib/dataset/pascal_voc.py如下:
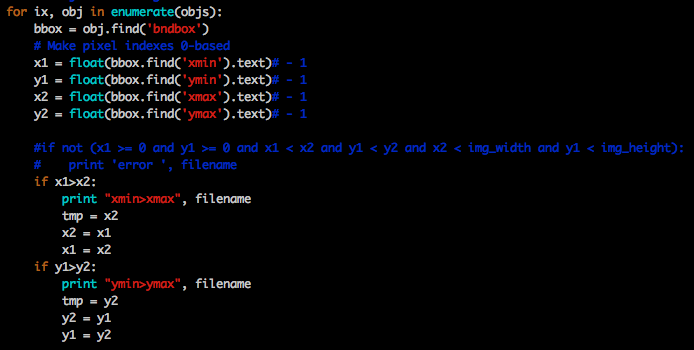
9.
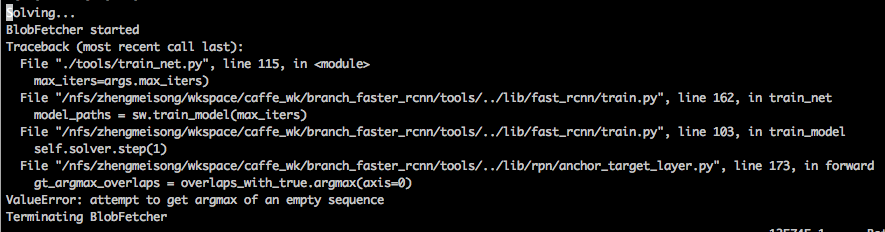
9. 1 输入改小为144*256以后出现的问题,自己设计的网络第一次迭代就报了这个错误,训VGG16,迭代5万次后也出现这个问题。中间试过换Adam为SGD、删除data/cache,各种折腾未果,改为600,好了,锁定就是改小输入尺度的原因(前两天忙着搞别的,没顾上训练,忘记上次的配置了,这样很不好,按说应该每次只改动一处,就不需要定位问题。但这个比较特殊,因为之前在别的服务器上改过这个尺度当时训练没问题)
看代码lib/rpn/anchor_target_layer.py:
anchor_scales = layer_params.get('scales', (8, 16, 32))
self._anchors = generate_anchors(scales=np.array(anchor_scales))
这里会生成一个这样的anchor(尺寸映射回原图):
#array([[ -83., -39., 100., 56.],
# [-175., -87., 192., 104.],
# [-359., -183., 376., 200.],
# [ -55., -55., 72., 72.],
# [-119., -119., 136., 136.],
# [-247., -247., 264., 264.],
# [ -35., -79., 52., 96.],
# [ -79., -167., 96., 184.],
# [-167., -343., 184., 360.]])
猜测是因为输入尺寸改小了,anchors还是那么大,faster rcnn又设置在训练的时候超出边界的候选框一律不要,导致返回到原图上没有多少候选框了,最后导致overlaps空了
修改第二行:
self._anchors = generate_anchors(scales=np.array( scales=np.array([2,4,8]) ))
或者:
anchor_scales = layer_params.get( 'scales', (2, 4, 8) )
self._anchors = generate_anchors(scales=np.array(anchor_scales)
对应anchor如下,因为是在setup函数里,所以会在模型初始化的时候打印:
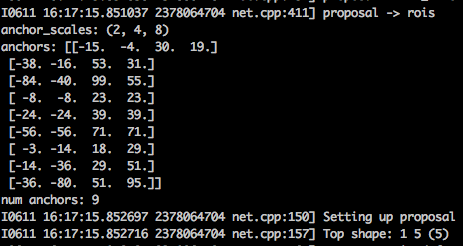
同时修改lib/fast_rcnn/config.py里的RPN_PRE_NMS_TOP_N、RPN_POST_NMS_TOP_N。改小输入尺寸后stride16,提rpn的特征层只有9*16那么大,只能提到9*16*9=1296个anchor,再去掉超出边界的,就没有多少可用了,这里默认的还是1.2万,2千,明显不合理。边改边看代码,发现proposal layer.py也有相同操作:
def setup(self, bottom, top):
# parse the layer parameter string, which must be valid YAML
layer_params = yaml.load(self.param_str_) self._feat_stride = layer_params['feat_stride']
anchor_scales = layer_params.get( 'scales', (8, 16, 32) )
这个笔记是良心分享
9.2 stride设错会导致这个问题,开始训练的时候就会看到loss大于3、4,迭代到几千或一万次就报这个错误了
10. 绘制loss曲线,去掉if line.find('Solving') != -1的判断,参考这里 frcnn专用,更详细的版本,备用
11. 训练完AP全是0,通常是因为test.prototxt和train.prototxt不一致导致的,比如某一层的stride,train里面改成2,test里面还是4,导致最后特征图大小都不一样,画出来的框位置全错。
这个问题是刚上手搞faster rcnn就遇到了,那时候一脸懵,以为模型训废了,直到看了大半代码,并且自己把模型拉到本地跑过一次,发现还能捡出来不少,中间迂回几次,基本可以锁定是这个原因。
12. 一个端午假期回来,之前的命令全不能跑,ssd还可以训练,faster rcnn下的一切都崩溃,全是这个错误:
syncedmem.cpp: Check failed: error == cudaSuccess ( vs. ) out of memory #
重新caffe-fast-rcnn make过也不行,幸好没有重装驱动各种,参考这里,杀死两个占用gpu 0 的进程,test搞定,训练还是不行,事实证明还是显存不足的问题,batchsize从256改成64就可以训练了。
13. 增加分类数量后原来的模型不能用来finetune了,一种方案是修改layer名字,但是涉及到pred_bbox,参考1、2,在py-faster-rcnn/tools目录下新建python文件
# -*- coding: utf- -*-
#!/usr/bin/env python
# --------------------------------------------------------
# 直接复制文件头部 # -------------------------------------------------------- import _init_paths
from fast_rcnn.config import cfg
from fast_rcnn.test import im_detect
from fast_rcnn.test import vis_detections
from fast_rcnn.nms_wrapper import nms
from utils.timer import Timer
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
import os, sys
# Make sure that caffe is on the python path:
caffe_root = './caffe-fast-rcnn/'
os.chdir(caffe_root)
sys.path.insert(, os.path.join(caffe_root, 'python'))
import caffe
import cv2
import argparse
if __name__ == "__main__":
caffe.set_mode_cpu
net = caffe.Net("/Users/_/wkspace/caffe_space/detection/py-faster-rcnn/models/pascal_voc/_/faster_rcnn_end2end/deploy.prototxt",\
"/Users/_/wkspace/caffe_space/detection/py-faster-rcnn/data/_.v2.caffemodel", \
caffe.TEST)
#第一个卷基层的权值
conv1_w = net.params['conv1_small'][].data[]
#第一个卷基层的偏置值
conv1_b = net.params['conv1_small'][].data[]
#可以打印相应的参数和参数的维度等信息
print conv1_w,'\n'
print conv1_b,'\n'
print conv1_w.size,conv1_b.size
net.save('/Users/_/Desktop/out/rm_pred_box_layer.caffemodel')
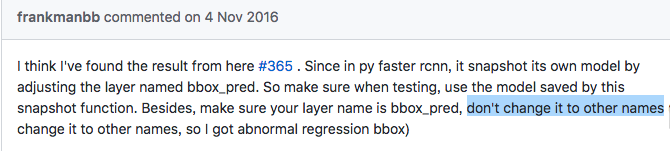
保存一个删除最后两层的caffemodel。诸多证据表明,faster rcnn里的pred_box层名字是不能随意修改的:
14. 赶deadline一个工程复制了8份全线开工,ln -s ~/VOCdevkit VOCdevkit2007 共用同一段数据,这种情况下8个工程是共享trainval.txt和test.txt的,如果其中一个工程修改过trainval.txt,其他工程重新开始训练时候要删除工程目录下的data/cache和data/VOCdevkit2007/anotation_cache。
15. 一个诡异的python问题,可能和faster rcnn无关,在tools目录下自己写了一个准确率测试脚本,加载model,累计计算loss求和,求均值:
src/tcmalloc.cc:331] Attempt to free invalid pointer 0x7fcb4aa7e2e0
[1] 74204 abort python tools/mtcnnAccTest.py
百度谷歌说啥的都有,最后发现abort的节点和读入图片数、图片大小有直接关系,于是注释掉脚本开头的import matplotlib.pyplot as plt这一句就好了。
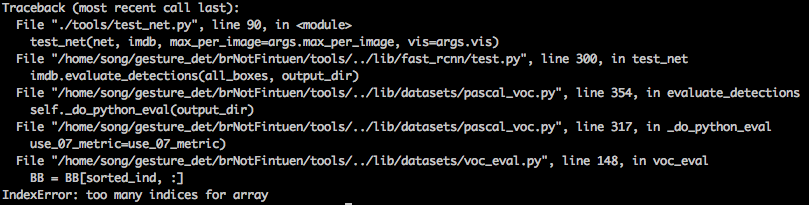
16. 测误检,手工加了一批测试集,name标为'__background__',报错如下:
Evaluating detections
VOC07 metric? Yes
Traceback (most recent call last):
File "./tools/test_net.py", line 90, in <module>
test_net(net, imdb, max_per_image=args.max_per_image, vis=args.vis)
File "/home/song/branch_faster_rcnn/tools/../lib/fast_rcnn/test.py", line 300, in test_net
imdb.evaluate_detections(all_boxes, output_dir)
File "/home/song/branch_faster_rcnn/tools/../lib/datasets/pascal_voc.py", line 344, in evaluate_detections
self._do_python_eval(output_dir)
File "/home/song/branch_faster_rcnn/tools/../lib/datasets/pascal_voc.py", line 307, in _do_python_eval
use_07_metric=use_07_metric)
File "/home/song/branch_faster_rcnn/tools/../lib/datasets/voc_eval.py", line 126, in voc_eval
R = [obj for obj in recs[imagename] if obj['name'] == classname]
KeyError: '20180626_dzf_shortV_1_00006_f183'
解决方案: 删掉data/VOCdevkit2007/目录下的annotations_cache。
17. test阶段,如果模型什么都检测不出来会这样:
训练:
./experiments/scripts/faster_rcnn_end2end.sh
tools/train_net..py
args.cfg_file
caffe.set_mode_gpu, set_gpuid
lib/datasets/factory.py: get_imdb
#实例化pascal_voc类,imdb = pascal_voc(trainval, 2007) --lib/datasets/pascal_voc.py
lib/datasets/imdb.py: get_proposal_method
lib/fast_rcnn/train.py: get_training_roidb
lib/datasets/imdb.py: append_flipped_images
lib/roi_data_layer/roidb.py: prepare_roidb #至此,图片地址和信息保存到imdb里了
lib/fast_rcnn/config.py: get_output_dir #caffemodel输出目录
lib/fast_rcnn/train.py
关于imdb参考python面向对象,从此可以通过imdb.gt_roidb()访问pascal_voc类方法
imdb是pascal_voc类的一个实例,roidb是一个list
imdb.append_flipped_images()是直接将水平翻转后的图append到roidb后面,所以水平翻转操作是对所有数据进行,该操作使训练数据翻倍。
以上,全是初始化。
pascal_voc.py:
gt_roidb()
selective_search_roidb()
gt_roidb()中调用_load_pascal_annotation,会解析xml,返回如下内容:

利用cPickle写入data/cache/voc_2007_trainval_gt_roidb.pkl,如果trainval.txt不变,下次就可以直接加载了,第一次会等在这里很久,以后加载就不会了。
读写pkl用到了python cPickle:对任意类型的python对象进行序列化操作。所谓的序列化,我的粗浅的理解就是为了能够完整的保存并能够完全可逆的恢复。

实际的训练数据读入开始于lib/fast_rcnn/train.py:
def train_net(solver_prototxt, roidb, output_dir, pretrained_model=None, max_iters=40000):
sw = SolverWrapper(solver_prototxt, roidb, output_dir, pretrained_model=pretrained_model) :init
self.solver.net.layers[0].set_roidb(roidb)
lib/roi_data_layer/layer.py : BlobFetcher
lib/roi_data_layer/lminibatch.py: blobs = get_minibatch(minibatch_db, self._num_classes)

初始化在此,选择solver:SGD,读入事先训练好的caffemodel,加载roidb,其中第46行会掉roi_data_layer,返回图示blob:

至此,带有roi的训练数据给到网络第一层。
lib/fast_rcnn/train.py:
sw.train_model(max_iters)
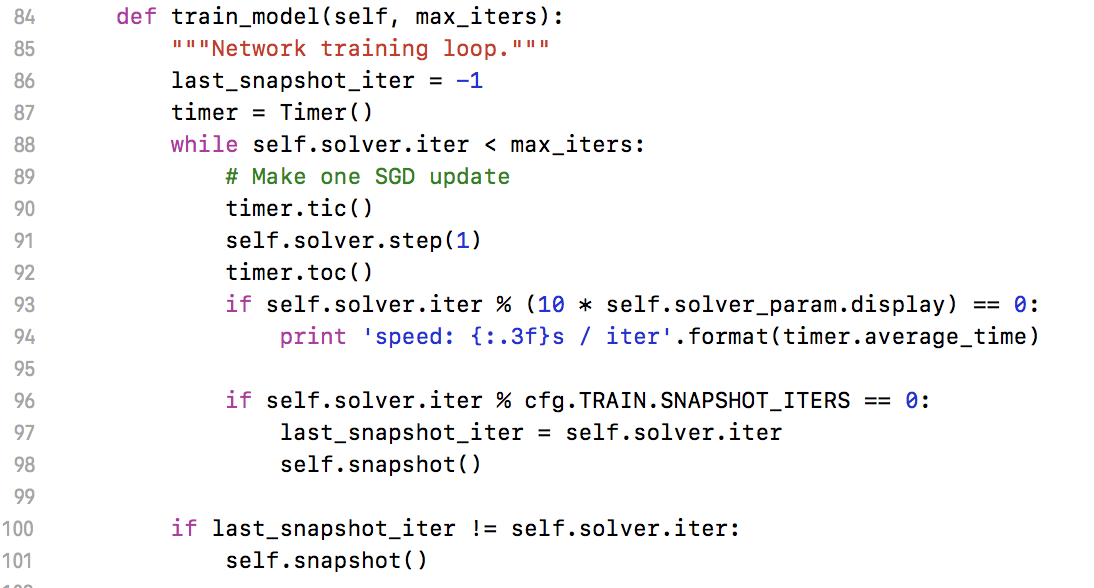
调caffe里的solver开始迭代训练,step(1)表示forward+backward 1次。
NET_FINAL=`grep -B 1 "done solving" ${LOG} | grep "Wrote snapshot" | awk '{print $4}'`
这句话的详细解释见这里,就是把训练好的caffemodel完整路径读入NET_FINAL,下一步test_net.py参数--net ${NET_FINAL}会用到。
细节:
fast rcnn的roi pooling: 先把roi中的坐标映射到feature map上,映射规则比较简单,就是把各个坐标除以“输入图片与feature map的大小的比值”,得到了feature map上的box坐标后,使用Pooling得到输出。详解1 详解2
知识点:
由于ImageNet数以百万计带标签的训练集数据,使得如CaffeNet之类的预训练的模型具有非常强大的泛化能力,这些预训练的模型的中间层包含非常多一般性的视觉元素,我们只需要对他的后几层进行微调,在应用到我们的数据上,通常就可以得到非常好的结果。最重要的是,在目标任务上达到很高performance所需要的数据的量相对很少。 from: fine-tuning:利用已有模型训练其他数据集
其他:
来自这里,先存着,回头验证下,现在用的Adam, fixed lr=1e-05

py-faster-rcnn的更多相关文章
- py faster rcnn+ 1080Ti+cudnn5.0
看了py-faster-rcnn上的issue,原来大家都遇到各种问题. 我要好好琢磨一下,看看到底怎么样才能更好地把GPU卡发挥出来.最近真是和GPU卡较上劲了. 上午解决了g++的问题不是. 然后 ...
- py faster rcnn的lib编译出错问题
真是好事多磨啊,计算机系统依然是14.04,而cuda依然是8.0,唯一不同的是时间不一样,下载的各种库版本有差别,GPU的driver不一样. 但是这样就出问题了,py-faster rcnn的li ...
- faster rcnn 源码学习-------数据读入及RoIDataLayer相关模块解读
参考博客:::https://www.cnblogs.com/Dzhen/p/6845852.html 非常全面的解读参考:::https://blog.csdn.net/DaVinciL/artic ...
- faster r-cnn 在CPU配置下训练自己的数据
因为没有GPU,所以在CPU下训练自己的数据,中间遇到了各种各样的坑,还好没有放弃,特以此文记录此过程. 1.在CPU下配置faster r-cnn,参考博客:http://blog.csdn.net ...
- 如何才能将Faster R-CNN训练起来?
如何才能将Faster R-CNN训练起来? 首先进入 Faster RCNN 的官网啦,即:https://github.com/rbgirshick/py-faster-rcnn#installa ...
- 新人如何运行Faster RCNN的tensorflow代码
0.目的 刚刚学习faster rcnn目标检测算法,在尝试跑通github上面Xinlei Chen的tensorflow版本的faster rcnn代码时候遇到很多问题(我真是太菜),代码地址如下 ...
- faster rcnn训练详解
http://blog.csdn.net/zy1034092330/article/details/62044941 py-faster-rcnn训练自己的数据:流程很详细并附代码 https://h ...
- faster rcnn相关内容
转自: https://zhuanlan.zhihu.com/p/31426458 faster rcnn的基本结构 Faster RCNN其实可以分为4个主要内容: Conv layers.作为一种 ...
- 运行Keras版本的Faster R-CNN(1)
Keras版本的Faster R-CNN源码下载地址:https://github.com/yhenon/keras-frcnn下载以后,用PyCharm打开(前提是已经安装了Tensorflow-g ...
- (原)faster rcnn的tensorflow代码的理解
转载请注明出处: https://www.cnblogs.com/darkknightzh/p/10043864.html 参考网址: 论文:https://arxiv.org/abs/1506.01 ...
随机推荐
- dedecms wap 上一篇 下一篇 链接出错
打开 \include\arc.archives.class.php 文件 大约在839 行,查找 $mlink = 'view.php?aid='.$preRow['id']; 修改 ...
- oracle 聚合函数 LISTAGG ,将多行结果合并成一行
LISTAGG( to_char(Item_Category_Name), ',') WITHIN GROUP(ORDER BY Item_Category_Name) -- 将 Item_Cate ...
- Mock an function to modify partial return value by special arguments on Python
Mock an function to modify partial return value by special arguments on Python python mock一个带参数的方法,修 ...
- javascript: 类、方法、原型
// 类.方法.原型 //================================================================================== /* 类 ...
- Windows上使用telnet测试端口号
之前测试服务器某一端口开启开启情况一般在服务器上使用 netstat –ano|findstr "端口号"命令查看. 但是有时候端口在服务器上开通了,但是客户端并不一定可以访问到 ...
- 开发环境使用docker 快速启动 单机 RocketMq
镜像说明 https://cr.console.aliyun.com/?spm=5176.2020520001.1001.8.kpaxIC&accounttraceid=176ddc4e-62 ...
- JBPM工作流(七)——详解流程图
概念: 流程图的组成: a. 活动 Activity / 节点 Node b. 流转 Transition / 连线(单向箭头) c. 事件 1.流转(Transition) a) 一般情况一个活动中 ...
- Java8 中的 default
之前的版本里 interface 中的方法必须是抽象方法,不能有方法体.现在可以添加 interface 内方法,只需要在方法的前面加一个 default 关键字,表示属于接口内部默认存在的方法. 如 ...
- socket与http
参考文档:http://blog.csdn.net/zeng622peng/article/details/5546384 1.TCP连接 手机能够使用联网功能是因为手机底层实现了TCP/IP协议,可 ...
- jquery和js检测浏览器窗口尺寸和分辨率
jquery和js检测浏览器窗口尺寸和分辨率,转载自网络,记录备忘 <script type="text/javascript">$(document).ready(f ...