C++ 提取网页内容系列之四正则
标 题: C++ 提取网页内容系列之四
作 者: itdef
链 接: http://www.cnblogs.com/itdef/p/4173833.html
欢迎转帖 请保持文本完整并注明出处
将网页内容下载后存入字符串string 或者本地文件后 我们开始进行搜索和查询 获取信息
这里使用正则式 使用vs2008 其自带的tr1库(预备标准库) 有正则式库供使用
带头文件/*******************************************************************************
* @file
* @author def< qq group: 324164944 >
* @blog http://www.cnblogs.com/itdef/
* @brief
/*******************************************************************************/
#include <regex>
using namespace std::tr1;
using namespace std;
这里推荐正则式教程
正则表达式30分钟入门教程
http://www.cnblogs.com/deerchao/ ... zhongjiaocheng.html
C++:Regex正则表达式
http://blog.sina.com.cn/s/blog_ac9fdc0b0101oow9.html
首先来个简单例子
#include <string>
#include <iostream>
#include <regex> using namespace std::tr1;
using namespace std; string strContent = " onclick=\"VeryCD.TrackEvent('base', '首页大推', '神雕侠侣');"; void Test1()
{
string strText = strContent;
string strRegex = "首页大推";
regex regExpress(strRegex); smatch ms; cout << "*****************************" << endl;
cout << "Test 1" << endl << endl; while(regex_search(strText, ms, regExpress))
{
for(string::size_type i = ;i < ms.size();++i)
{
cout << ms.str(i).c_str() << endl;
}
strText = ms.suffix().str();
} cout << "*****************************" << endl << endl;
} void Test2()
{
string strText = strContent;
string strRegex = "首页大推.*'(.*)'";
regex regExpress(strRegex); smatch ms; cout << "*****************************" << endl;
cout << "Test 2" << endl << endl;
while(regex_search(strText, ms, regExpress))
{
for(string::size_type i = ;i < ms.size();++i)
{
cout << ms.str(i).c_str() << endl;
}
strText = ms.suffix().str();
}
cout << "*****************************" << endl << endl;
} int _tmain(int argc, _TCHAR* argv[])
{
Test1();
Test2(); return ;
}
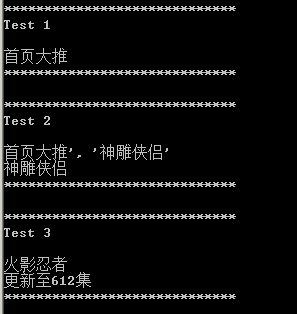
Test1中 我们等于是直接搜索字符串 然后 打印出找到的位置Test2中 我们使用 首页大推.*'(.*)'
.号等于是任意非空白换行字符 *则代表重复任意多次(0-无穷次)
而括号表示一个字符集 也就是我们需要查找的内容
请注意这个括号是在 ' ' 之间的 也就是查找 首页大推 任意字符之后 两个 ' '号之间的内容
效果如下:
而且我们也发现 ms的显示规律 他首先显示符合条件的字符串 然后现实符合( )里面条件的子字符串

下面来个深入点得 分析这个字符串
string strContent0 = "alt=\"火影忍者\" /><div class=\"play_ico_middle\"></div><div class=\"cv-title\" style=\"width:85px;\">更新至612集</div>";
我们使用的正则式规则为 string strRegex = "alt=\"([^\"]*)\".*width:85px;\">(.*)</div>";
注意里面有两个括号 一个是在alt= 之后 在两个" " 之间的内容 一个是在width:85px;\"> 和 </div> 之间的内容
注意 "的显示 由于C++语言的特性 必须写成 \"
现在分析两个括号内容 ([^\"]*) (.*)
(.*)无须多说 就是任意非空白字符 而且是在width:85px;\"> 和 </div> 之间的内容
([^\"]*) 就是说 非"的内容任意重复多次 而且这个括号是在alt= 之后 在两个" " 之间的内容
运行结果如下:(为了不显示过多内容 符合条件的内容没有全部显示 只显示了符合括号需求的子字符串)
/*******************************************************************************
* @file
* @author def< qq group: 324164944 >
* @blog http://www.cnblogs.com/itdef/
* @brief
/*******************************************************************************/ #include <string>
#include <iostream>
#include <regex> using namespace std::tr1;
using namespace std; string strContent = " onclick=\"VeryCD.TrackEvent('base', '首页大推', '神雕侠侣');"; string strContent0 = "alt=\"火影忍者\" /><div class=\"play_ico_middle\"></div><div class=\"cv-title\" style=\"width:85px;\">更新至612集</div>"; void Test1()
{
string strText = strContent;
string strRegex = "首页大推";
regex regExpress(strRegex); smatch ms; cout << "*****************************" << endl;
cout << "Test 1" << endl << endl; while(regex_search(strText, ms, regExpress))
{
for(string::size_type i = ;i < ms.size();++i)
{
cout << ms.str(i).c_str() << endl;
}
strText = ms.suffix().str();
} cout << "*****************************" << endl << endl;
} void Test2()
{
string strText = strContent;
string strRegex = "首页大推.*'(.*)'";
regex regExpress(strRegex); smatch ms; cout << "*****************************" << endl;
cout << "Test 2" << endl << endl;
while(regex_search(strText, ms, regExpress))
{
for(string::size_type i = ;i < ms.size();++i)
{
cout << ms.str(i).c_str() << endl;
}
strText = ms.suffix().str();
}
cout << "*****************************" << endl << endl;
} void Test3()
{
string strText = strContent0;
string strRegex = "alt=\"([^\"]*)\".*width:85px;\">(.*)</div>";
regex regExpress(strRegex); smatch ms; cout << "*****************************" << endl;
cout << "Test 3" << endl << endl; while(regex_search(strText, ms, regExpress))
{
for(string::size_type i = ;i < ms.size();++i)
{
if(i > )
cout << ms.str(i).c_str() << endl;
}
strText = ms.suffix().str();
}
cout << "*****************************" << endl << endl; } int _tmain(int argc, _TCHAR* argv[])
{
Test1();
Test2();
Test3(); return ;
}
C++ 提取网页内容系列之四正则的更多相关文章
- C++ 提取网页内容系列之三
标 题: C++ 提取网页内容系列作 者: itdef链 接: http://www.cnblogs.com/itdef/p/4171659.html 欢迎转帖 请保持文本完整并注明出处 这次继续下载 ...
- C++ 提取网页内容系列之二
标 题: C++ 提取网页内容系列作 者: itdef链 接: http://www.cnblogs.com/itdef/p/4171203.html 欢迎转帖 请保持文本完整并注明出处 另外一种下载 ...
- C++ 提取网页内容系列之一
标 题: C++ 提取网页内容系列作 者: itdef链 接: http://www.cnblogs.com/itdef/p/4171179.html 欢迎转帖 请保持文本完整并注明出处 首先分析网页 ...
- C++ 提取网页内容系列之五 整合爬取豆瓣读书
工作太忙 没有时间细化了 就说说 主要内容吧 下载和分析漫画是分开的 下载豆瓣漫画页面是使用之前的文章的代码 见http://www.cnblogs.com/itdef/p/4171179.html ...
- 在.NET中使用JQuery 选择器精确提取网页内容
1. 前言 相信很多人做开发时都有过这样的需求:从网页中准确提取所需的内容.思前想后,方法无非是以下几种:(本人经验尚浅,有更好的方法还请大家指点) 1. 使用正则表达式匹配所需元素.(缺点:同类型的 ...
- Sql Server来龙去脉系列之四 数据库和文件
在讨论数据库之前我们先要明白一个问题:什么是数据库? 数据库是若干对象的集合,这些对象用来控制和维护数据.一个经典的数据库实例仅仅包含少量的数据库,但用户一般也不会在一个实例上创建太多 ...
- Red Gate系列之四 SQL Data Compare 10.2.0.885 Edition 数据比较同步工具 完全破解+使用教程
原文:Red Gate系列之四 SQL Data Compare 10.2.0.885 Edition 数据比较同步工具 完全破解+使用教程 Red Gate系列之四 SQL Data Compare ...
- .NET 4 并行(多核)编程系列之四 Task的休眠
原文:.NET 4 并行(多核)编程系列之四 Task的休眠 .NET 4 并行(多核)编程系列之四 Task的休眠 前言:之前的几篇文章断断续续的介绍了Task的一些功能:创建,取消.本篇介绍Tas ...
- .Neter玩转Linux系列之四:Linux下shell介绍以及TCP、IP基础
基础篇 .Neter玩转Linux系列之一:初识Linux .Neter玩转Linux系列之二:Linux下的文件目录及文件目录的权限 .Neter玩转Linux系列之三:Linux下的分区讲解 .N ...
随机推荐
- 队列&广搜
搜索里有深搜,又有广搜,而广搜的基础就是队列. 队列是一种特殊的线性表,只能在一段插入,另一端输出.输出的那一端叫做队头,输入的那一端叫队尾.是一种先进先出(FIFO)的数据结构. 正经的队列: 头文 ...
- 知识点:SQL中char、varchar、text区别
Char为定长,varchar,text为变长. 1.CHAR.CHAR存储定长数据很方便,CHAR字段上的索引效率级高,比如定义char(10),那么不论你存储的数据是否达到了10个字节,都要占去1 ...
- DBUS 的学习 概念清晰
dbus里面 name和path 怎么确定的,xml的不准确: 后来发现这个应该是在写debus server的时候自己制定的,xml只是理论上应该和这个保持一致 D-Bus三层架构 D-Bus是一个 ...
- python网页爬虫开发之二
1.网站robots robotparser模块首先加载robots.txt文件,然后通过can_fetch()函数确定指定的用户代理是否允许访问网页. 2.识别网站技术 3.下载网页 使用urlli ...
- EL(Expression Language)和JSTL标签(JSP Standard Tag Library)
一.EL表达式: Expression Language提供了在 JSP 脚本编制元素范围外(例如:脚本标签)使用运行时表达式的功能.脚本编制元素是指页面中能够用于在JSP 文件中嵌入 Java代码的 ...
- k8s学习笔记之三:k8s快速入门
一.前言 kubectl是apiserver的客户端工具,工作在命令行下,能够连接apiserver上实现各种增删改查等各种操作 kubectl官方使用文档:https://kubernetes.io ...
- Java 多态的实现机制
http://my.oschina.net/onlytwo/blog/52222 是父类或接口定义的引用变量可以指向子类或实现类的实例对象,而程序调用的方法在运行期才动态绑定,就是引用变量所指向的具体 ...
- Xeon Phi 《协处理器高性能编程指南》随书代码整理 part 3
▶ 第二章,几个简单的程序 ● 代码,单线程 #include <stdio.h> #include <stdlib.h> #include <string.h> ...
- PHP实现JS点击点击定位
点击class='women' 定位到 class='m=foot'$(".women").on('click',function(){ $("html, body&qu ...
- SpringCloud系列二:Restful 基础架构(搭建项目环境、创建 Dept 微服务、客户端调用微服务)
1.概念:Restful 基础架构 2.具体内容 对于 Rest 基础架构实现处理是 SpringCloud 核心所在,其基本操作形式在 SpringBoot 之中已经有了明确的讲解,那么本次为 了清 ...