C++ 提取网页内容系列之五 整合爬取豆瓣读书
工作太忙 没有时间细化了 就说说 主要内容吧
下载和分析漫画是分开的
下载豆瓣漫画页面是使用之前的文章的代码
见http://www.cnblogs.com/itdef/p/4171179.html
http://www.cnblogs.com/itdef/p/4081963.html
注意 豆瓣网是https
下载后进行页面分析
fstream fs(szfileName);
stringstream ss; // 创建字符串流对象
ss << fs.rdbuf(); // 把文件流中的字符输入到字符串流中
fs.close();
string str = ss.str(); // 获取流中的字符串
页面不大 载入到string中 如果是UTF8 还需要进行GBK到UTF8的转换
然后使用正则 摘出每个漫画索引信息 存入vector<string>
string strRegex = "<li class=\"subject-item\">.*?</li>";
vector<string> vstr;
regex regExpress(strRegex);
smatch ms;
try {
while (regex_search(strText, ms, regExpress))
{
for (string::size_type i = 0; i < ms.size(); ++i)
{
vstr.push_back(ms.str(i));
}
strText = ms.suffix().str();
}
}
catch (exception& e)
{
cerr << e.what() << endl;
return vstr;
}
然后在对每本书的信息进行分析 解析出 书本名 简介 评分等
由于这些信息都是有固定标签 用正则反而麻烦 所以使用的字符串查找
basic_string <char>::size_type keyWordStart = s.find("title=\"");
basic_string <char>::size_type keyWordEnd = s.find("\"", keyWordStart + sizeof("title=\"")-1);
if ((keyWordStart != string::npos) && (keyWordEnd != string::npos) && (keyWordEnd > keyWordStart))
{
string strKeyWord = s.substr(keyWordStart+ sizeof("title=\"") - 1, keyWordEnd - keyWordStart- sizeof("title=\"")+1);
cout << strKeyWord << endl;
}
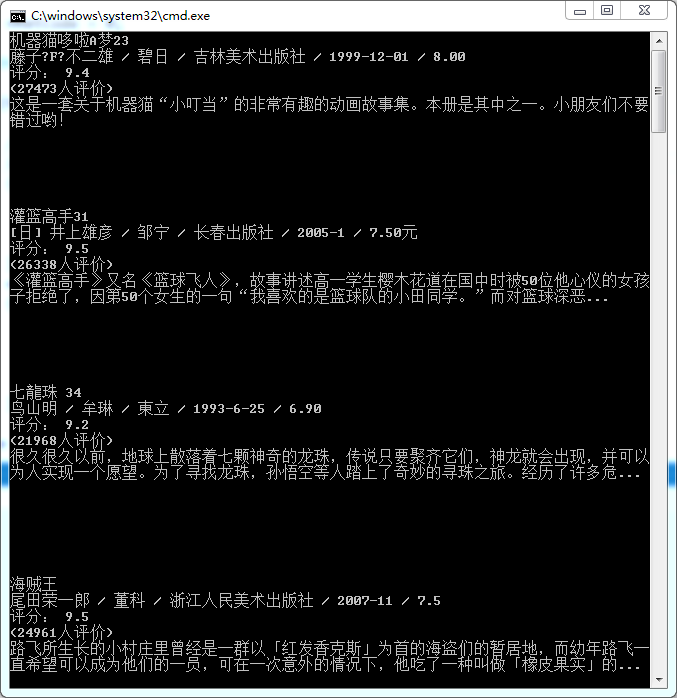
最后结果如图
C++ 提取网页内容系列之五 整合爬取豆瓣读书的更多相关文章
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- Python爬虫爬取豆瓣读书
一,准备工作. 工具:win10+Python3.6 爬取目标:爬取图中红色方框的内容. 原则:能在源码中看到的信息都能爬取出来. 信息表现方式:CSV转Excel. 二,具体步骤. 先给出具体代码吧 ...
- scrapy框架爬取豆瓣读书(1)
1.scrapy框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- python实例:自动爬取豆瓣读书短评,分析短评内容
思路: 1.打开书本“更多”短评,复制链接 2.脚本分析链接,通过获取短评数,计算出页码数 3.通过页码数,循环爬取当页短评 4.短评写入到txt文本 5.读取txt文本,处理文本,输出出现频率最高的 ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
随机推荐
- Hadoop-HBASE 热添加新节点
Hadoop-HBASE 热添加新节点 环境:192.168.137.101 hd1192.168.137.102 hd2192.168.137.103 hd3192.168.137.104 hd4四 ...
- SpringSecurity-FilterSecurityInterceptor的作用
FilterSecurityInterceptor也是很重要的一个interceptor,它的作用是对request进行权限判断,允许访问或者抛出accessDenied异常. 这个类继承Abstra ...
- Qt中三种解析xml的方式
在下面的随笔中,我会根据xml的结构,给出Qt中解析这个xml的三种方式的代码.虽然,这个代码时通过调用Qt的函数实现的,但是,很多开源的C++解析xml的库,甚至很多其他语言解析xml的库,都和下面 ...
- OpenStack Q版本新功能以及各核心组件功能对比
OpenStack Q版本已经发布了一段时间了.今天, 小编来总结一下OpenStack Q版本核心组件的各项主要新功能, 再来汇总一下最近2年来OpenStack N.O.P.Q各版本核心组件的主要 ...
- 【Linux】【Jenkins】系统配置报反向代理设置有误问题的解决方案
1.如图所示: 2.点击更多信息,查看解决办法: https://wiki.jenkins-ci.org/display/JENKINS/Jenkins+says+my+reverse+proxy+s ...
- spring boot 接口用例测试
接口: 测试用例:
- 判断文件的唯一性--MD5
JAVA中获取文件MD5值的四种方法 JAVA中获取文件MD5值的四种方法其实都很类似,因为核心都是通过JAVA自带的MessageDigest类来实现.获取文件MD5值主要分为三个步骤,第一步获 ...
- 《Spring_Four》第二次作业 基于Jsoup的大学生考试信息展示系统开题报告
一.项目概述 该项目拟采用Jsoup对大学生三大考试(考研.考公务员.考教师资格证)进行消息搜集,研发完成一款轻量级的信息展示APP,本项目主要的创新点在于可以搜集大量的考试信息,对其进行一个展示,而 ...
- AR涂涂乐
<1> 涂涂乐着色 https://blog.csdn.net/begonia__z/article/details/51282932 http://www.manew.com/blog- ...
- faster-RCNN框架之rpn 较小目标检测,如果只使用rpn,并减少多个候选框
通常faster-rcnn目标检测有两个步骤,一个是侯选框生成,一个是侯选框微调+目标区分,但是对于单目标识别, 我经常喜欢只使用rpn网络,效果还不错,不过仅仅的rpn使用参考的参数通常会造成一个目 ...