python正则表达式模块re:正则表达式常用字符、常用可选标志位、group与groups、match、search、sub、split,findall、compile、特殊字符转义
本文内容:
- 正则表达式常用字符、
- 常用可选标志位、
- group与groups、
- match、
- search、
- sub、
- split
- findall、
- compile
- 特殊字符转义
- 一些现实例子
首发时间:2018-02-07 17:17
修改:
- 2018-02-19 00:34:增加可选标志位re.M
- 2018-03-19 12:55:修改了一些文字表述,修改了一些小错误,增加了一些常用字符,增加了特殊字符转义,增加了一些例子
re:
介绍:
关于正则表达式的模块
正则表达式字符:
| 字符 | 意义 | 例子【#后面代表结果】 |
| . | .代表匹配一个任意字符,\n除外 |  |
| ^ | ^后面的字符串必须是待匹配字符串的开头,否则找不到,同样功能的是\A |  |
|
$ |
$前面的字符串必须是待匹配字符串的结尾,否则找不到,同样功能的是\Z |  |
| \d | 可以匹配一个数字 |  |
\D |
匹配一个非数字 |  |
| \s | 可以匹配一个空白字符(空格,缩进符、\n,\r),同样功能:[\n\t\r\v\f] |  |
| \S | 匹配一个非空白字符 | |
| \b 注:\b是字符串中的一个转义字符,所以需要变成\\b,当然也可以使用原始字符串r"\b" |
匹配的是一个单独的单词,有边界,比如\bthe可以匹配出"bite the boy"的the,而不能匹配出"bithe"中的the. |  |
| \B | 与\B相反,匹配的单词不是边界的 |  |
| 可以用+、?、*来选择匹配次数 | ||
| + | 代表匹配前一个字符一次或多次,贪婪的 | 
|
| ? | 代表匹配前一个字符0次或1次,不贪婪的 |  |
| * | 匹配*号前的字符0次或多次,贪婪的, |
 |
| +?或*? |
如果问号紧跟在+或者*后面,它将直接要求+、*尽可能少的次数。 |
 |
可以用 []表示范围 |
注:范围自己定,用-来代表,如可以有[0-9]、[1-9]、[1-6]、[abcd]等 | |
| [a-z] | 代表匹配范围是a-z |  |
| [0-9] | 代表匹配范围是0-9 |  |
| 也可以多个范围: [a-zA-Z0-9] |
代表匹配字母或数字 |  |
| 也可以没有-,仅仅只有字符 | 代表匹配[]内的字符中的一个 |  |
|
[^] |
如果脱字符(^)紧跟在左方括号后面,这个符号就表示不匹配给定字符 |
 |
| 或: | | 用在两个模式中间,代表匹配|左或|右的字符,如 A|B 代表可以匹配A或B |
 |
可以用{m}来表示匹配次数 |
||
| {n} | 代表匹配n次前一个字符 |  |
| {n,} | 代表匹配n次或更多次前一个字符 |  |
| {n,m} | 代表匹配前一个字符n到m次 |
 |
可以用(...)来表示分组匹配 |
代表将()里面的当成一整块来匹配,可以用于一组组数据的情况 |  |
| 可以用()来获取子组 | 使用.group(组号)可以获取之前()中匹配的结果 | 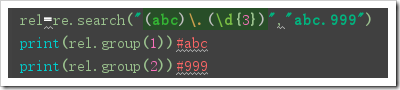  |
这里还有一些扩展表示法没写出来。
更多:https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215?fr=aladdin
常用可选标志位:
- re.S:
- 使 . 匹配包括换行在内的所有字符

- re.I:
- 匹配忽略大小写

- re.M:
- 进行多行匹配,在新的一行中,同样可以使用^来匹配该行字符串的开头,用$来匹配该行字符串的结尾
【英文文档原意:
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
】
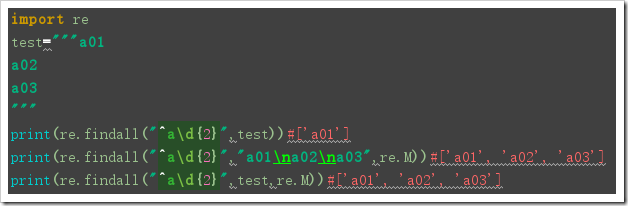
- 如果想同时使用多个标志位,需要使用|:

group与groups:
match和search匹配的返回结果都是对象,如果要获取对应字符串,需要使用group(num) 或 groups() :

group(num=0):
直接调用则返回整个匹配结果,
如果group里面有参数:group(0)代表整个匹配结果,group(1) 列出第一个分组匹配部分,group(2) 列出第二个分组匹配部分,group(3) 列出第三个分组匹配部分,以此类推。
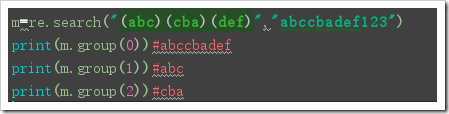
groups()
以元组返回所有分组匹配的字符

附加:
start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
- 没有子组的情况下是返回整个匹配结果的start和end:

- 只有有group方法的查找方式的结果才有start,end,span,而findall是没有的
re.match(pattern, string, flags=0):
功能:
re.match 从头开始匹配,如果字符串开头不匹配,那么返回None【如果匹配模式是】
参数介绍:
- pattern:匹配的正则表达式
- string:要匹配的字符串。
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
re.search(pattern, string, flags=0):
功能:
re.search 搜索整个字符串,返回第一个匹配结果参数介绍:
- pattern:匹配的正则表达式
- string:要匹配的字符串。
- flags:标志位,用于控制正则表达式的匹配方式

re.sub(pattern, repl, string, count=0, flags=0):
功能:
re.sub 用于替换字符串中的匹配项,可指定替换个数参数介绍:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags:标志位,用于控制正则表达式的匹配方式
用法:
import re
print(re.sub("abc","ABC","123abc123"))#123ABC123
print(re.sub("abc","ABC","123abc123abc123abc",2))#123ABC123ABC123abc
print(re.sub("abc","ABC","123abc123abc123abc",2))#123ABC123ABC123abc
def func(x):
x=int(x.group())+1
return str(x)
print(re.sub("",lambda x:str(int(x.group())+1),"123abc123"))#124abc124
print(re.sub("",func,"123abc123"))#124abc124
补充:
- subn()与sub()的区别:
- subn()和 sub()的功能一样,但 subn()还返回一个表示替换的总数,替换后的字符串和表示替换总数的数字一起作为一个拥有两个元素的元组返回。
re.split(pattern, string, maxsplit=0, flags=0):
功能:
基于正则表达式的模式分隔字符串
参数介绍:
- pattern : 正则中的模式字符串。
- string : 要被分割的原始字符串。
- maxsplit:分割的最大次数
用法:
import re
rel=re.split(':', 'str1:str2:str3')
print(rel)#['str1', 'str2', 'str3']
re.findall(pattern, string, flags=0)
功能:
re.findall 搜索整个字符串,把所有匹配到的字符串以列表中的元素返回参数介绍:
- pattern : 正则中的模式字符串。
- string : 待匹配的字符串。
- flags:标志位,用于控制正则表达式的匹配方式
用法:

补充:
- 对于使用了分组的正则表达式,findall只会返回各个分组的内容:

- finditer()函数与findall()函数不同的是返回的是一个迭代器
re.compile 函数
功能:
- compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象
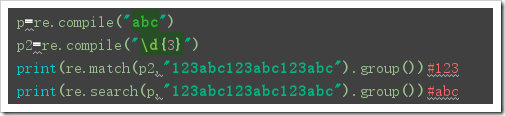
补充:
为什么需要compile()【摘自Python核心编程】:
- eval()或者 exec(在 2.x 版本中或者在 3.x 版本的 exec()中)调用一个代码对象而不是一个字符串,性能上会有明显提升
- 使用预编译的代码对象比直接使用字符串要快,因为解释器在执行字符串形式的代码前都必须把字符串编译成代码对象。
- 同样的概念也适用于正则表达式 — 在模式匹配发生之前,正则表达式模式必须编译成正则表达式对象。由于正则表达式在执行过程中将进行多次比较操作,因此强烈建议使用预编译。而且,既然正则表达式的编译是必需的,那么使用预编译来提升执行性能无疑是明智之举。re.compile()能够提供此功能。
complie()与purge():
其实模块函数会对已编译的对象进行缓存,所以不是所有使用相同正则表达式模式的 search()和 match()都需要编译。即使这样,你也节省了缓存查询时间,并且不必对于相同的字符串反复进行函数调用。在不同的 Python 版本中,缓存中已编译过的正则表达式对象的数目可能不同,而且没有文档记录。purge()函数能够用于清除这些缓存。
上面的演示的代码:
import re
print(".".center(50,'-'))
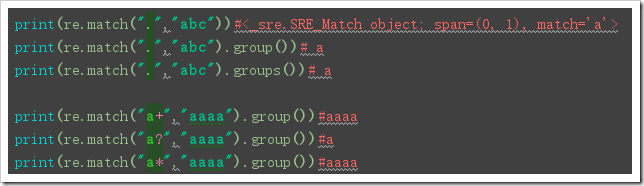
print(re.match(".","abc"))#<_sre.SRE_Match object; span=(0, 1), match='a'>
print(re.match(".","abc").group())# a
print(re.match(".","abc").groups())# a
print("+".center(50,'-'))
print(re.match("a+","aaaa").group())#aaaa
print("?".center(50,'-'))
print(re.match("a?","aaaa").group())#a
print("*".center(50,'-'))
print(re.match("a*","aaaa").group())#aaaa
print("^".center(50,'-'))
print(re.search("^a.b","acbd").group())#acb
print(re.match("^a.+","abc").group())
print(re.search("^a.b","123acbd"))#这样找不到
print(re.search("a.+d$","acbd").group())#acbd
print(re.search("a.+d$","acbdc"))#这样找不到
print("".center(50,'-'))
print("\d".center(50,'-'))
print(re.match("\d","").group())#
print(re.match("\d+","").group())#
print("\D".center(50,'-'))
print(re.search("\D","123456b").group())#b
print(re.search("\D","a123456").group())#a
print("\s".center(50,'-'))
print(re.search("a\sb","123a b456").group())#a b
print("[]".center(50,'-'))
print(re.search("[a-z]+","abcdefg").group())#abcdefg
print(re.search("[a-k]+","abczefg").group())#abc
print(re.search("[0-9]+","").group())#
print(re.search("[0-4]+","").group())#
print(re.search("[a-zA-Z0-9]+","1a2bC456ef").group())#1a2bC456ef
print("".center(50,'-'))
print(re.search("[a-z]+|[A-Z]+","1ab2bC4ef").group())#ab
print(re.search("([a-z]|[A-Z])+","1ab2bC4ef").group())#ab
print("{n}{n,m}".center(50,'-'))
print(re.search("[a-z]{3}","1ab2bC4efg").group())#efg
print(re.search("[a-z]{2,3}","1ab2bC4efg").group())#ab
print(re.search("[a-z]{2,3}","1a2C4efg").group())#efg
print(re.search("[a-z]{2,}","1a2C4efgaaaa").group())#efgaaaa
print("分组匹配".center(50,'-'))
print(re.search("([a-z]|[A-Z])+","1ab2bC4ef").group())#ab
print(re.search("([a-z]|[A-Z])+","1ab2bC4ef").group())#ab
print("group groups".center(50,'-'))
print(re.search("(\d[a-z]\d){3}","1x11a32a465").group())#1x11a32a4
print(re.search("(abc){3}","abcabcabc123").group())#abcabcabc
print(re.search("(abc)","abcabcabc123").groups())#('abc',)
m=re.search("(abc)(cba)(def)","abccbadef123")
print(m.groups())#('abc', 'cba', 'def')
print(m.group(0))#abccbadef
print(m.group(1))#abc
print(m.group(2))#cba
print("findall".center(50,'-'))
print(re.findall("(abc)","abcabcabc123"))#['abc', 'abc', 'abc']
print("flag".center(50,'-'))
print(re.search("a.b","a\nb",re.S).group())#分两行打印的 a b
print(re.search("a.b","A\nb",re.S|re.I).group())#分两行打印的 A b
print(re.search("ab","Ab",re.I).group())#Ab
特殊字符转义:
2018-03-18:前几天遇到一个人问我一个正则问题,才发现忘记写下特殊字符转义的情况了。
特殊字符转义:遇到正则表达式定义好的字符该怎么匹配出来这样的问题时利用转义来标注特定字符使用非正则功能的字符意义
比如:
想要匹配一个.,可以使用"\."或"\\."
想要匹配一个"[" 或 "]",可以使用
import re
rel=re.search(".","a.a")
print(rel.group())
rel=re.search("\\.","a.a")
print(rel.group())
rel=re.search("\.","a.a")
print(rel.group())
rel=re.search("\[","-[用户名]-")
print(rel.group())
rel=re.search("\[\]","-[]-")
print(rel.group())
rel=re.search("\\[","-[用户名]-")
print(rel.group())
rel=re.search("\[(\w+)\]","-[用户名]-")
print(rel.group())
一些现实例子:
整数:^(0|[1-9][0-9]*)$
正浮点数:^\d+(\.\d+)?$
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码(“XXX-XXXXXXX”、”XXXX-XXXXXXXX”、”XXX-XXXXXXX”、”XXX-XXXXXXXX”、”XXXXXXX”和”XXXXXXXX):^($$\d{3,4}-)|\d{3.4}-)?\d{7,8}$
身份证号(15位、18位数字):^\d{15}|\d{18}$
IP地址:\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}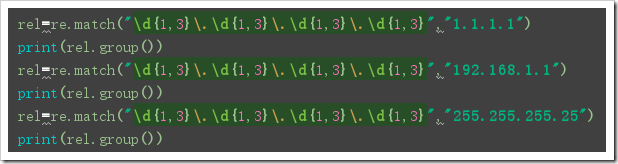
python正则表达式模块re:正则表达式常用字符、常用可选标志位、group与groups、match、search、sub、split,findall、compile、特殊字符转义的更多相关文章
- python 中 模块,包, 与常用模块
一 模块 模块:就是一组功能的集合体, 我们的程序可以直接导入模块来复用模块里的功能 导入方式 一般为 : import 模块名 在python中, 模块一般分为四个通用类别 1使用python编写. ...
- Python re模块与正则表达式的运用
re模块 永远不要起一个py文件的名字,这个名字和你已知的模块同名 查找 findall(): 匹配所有 每一项都是列表中的一个元素 语法 : findall(正则判断条件,要判断字符 ...
- 19 Python 正则模块和正则表达式
什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代码(.p ...
- python——re模块(正则表达式)
re 模块的使用: 1.使用compile()函数编译一个parttern对象, 例如:parttern=re.compile(r'\d+') 2.通过pattern对象提供的一系列属相和方法,对文本 ...
- python re模块与正则表达式
首先要先继承re模块: import re re.findall() 方法 # 返回值为列表 \w 表示一个字符,为数字,字母,下滑线之一, \W匹配任意非数字,字母,下划线 print(re.fin ...
- javascript正则表达式总结(test|match|search|replace|split|exec)
test:测试string是否包含有匹配结果,包含返回true,不包含返回false. <script type="text/javascript"> var str ...
- Python中re(正则表达式)模块学习
re.match re.match 尝试从字符串的开始匹配一个模式,如:下面的例子匹配第一个单词. import re text = "JGood is a handsome boy, he ...
- python正则表达式模块
正则表达式是对字符串的最简约的规则的表述.python也有专门的正则表达式模块re. 正则表达式函数 释义 re.match() 从头开始匹配,匹配失败返回None,匹配成功可通过group(0)返回 ...
- python学习笔记之——正则表达式
1.re模块 Python通过re模块提供对正则表达式的支持,re 模块使 Python 语言拥有全部的正则表达式功能.使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用 ...
随机推荐
- Jenkins 集成Sonar代码质量扫描
Jenkins上安装插件 在jenkins插件安装界面安装: 插件名 SonarQube Scanner for Jenkins Jenkins上配置 jenkins中操作:系统管理-系统设置,找到 ...
- Python函数——命名空间与闭包
前言 执行以下代码 def my_test(): x = 1 y = x+1 print(x) >> Traceback (most recent call last): File &qu ...
- web自动化测试(java)---环境搭建
java的测试环境搭建相较于python还简单些,只要把相关的jar包导入即可了 1.安装java 从官网下载最新的java安装程序,双击安装(java1.8) 2.下载java版的selenium的 ...
- Android模拟微信主页面的Demo
Android模拟微信主页面的Demo 效果图如下: 项目结构图如下: ContanctFragment: package com.demo.moniwexin; import android.app ...
- OpenStack 单元测试
OpenStack 单元测试 OpenStack开发——单元测试 本文将介绍OpenStack单元测试的部分.本文将重点讲述Python和OpenStack中的单元测试的生态环境. openstack ...
- Docker应用场景
Docker的应用场景 Web 应用的自动化打包和发布. 自动化测试和持续集成.发布. 在服务型环境中部署和调整数据库或其他的后台应用. 从头编译或者扩展现有的OpenShift或Cloud Foun ...
- Android并发编程 开篇
该文章是一个系列文章,是本人在Android开发的漫漫长途上的一点感想和记录,我会尽量按照先易后难的顺序进行编写该系列.该系列引用了<Android开发艺术探索>以及<深入理解And ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(二十):服务熔断(Hystrix、Turbine)
在线演示 演示地址:http://139.196.87.48:9002/kitty 用户名:admin 密码:admin 雪崩效应 在微服务架构中,由于服务众多,通常会涉及多个服务层级的调用,而一旦基 ...
- 将文件内容隐藏在bmp位图中
首先要实现这个功能,你必须知道bmp位图文件的格式,这里我就不多说了,请看:http://www.cnblogs.com/xiehy/archive/2011/06/07/2074405.html 接 ...
- java基础之继承(一)
虽然说java中的面向对象的概念不多,但是具体的细节还是值得大家学习研究,java中的继承实际上就是子类拥有父类所有的内容(除私有信息外),并对其进行扩展.下面是我的笔记,主要包含以下一些内容点: 构 ...